
빌 게이츠의 저서 <생각의 속도>에서는 인간의 신경 체계와 같은 ‘디지털 신경망(Digital Nervous System)’이 언급됐습니다. 얼핏 인공지능(AI)과 비슷하지만, 조금 차이가 있습니다. 핵심은 시공을 초월해 연결된 세계입니다. 이를 위해 비즈니스가 말 그대로 생각의 속도로 운영되어야 한다는 조건을 달았죠. 아무리 IT 기기가 발전하더라도 사람보다 빠르게 생각하기는 어렵습니다. 여기서 말하는 것은 단순 연산 능력이 아닌, 생각하고 실행하며 목적을 달성하는 종합적인 능력을 말합니다. 하지만 앞으로는 상황이 바뀔지 모르겠습니다. 바로 고대역폭 메모리(High Bandwidth Memory, HBM) 덕분입니다.
TSV, 발상의 전환을 시작하다

▲ SK하이닉스는 AMD와 함께 세계 최초로 HBM을 상용화했다.
SK하이닉스 블로그에서도 HBM은 여러 번 다뤄졌습니다. D램을 설명하는 과정과 실리콘관통전극(Through Silicon Via, TSV), 후공정 등을 언급하면서 소개됐죠. 이번에는 조금 다른 이야기를 해보겠습니다. 잘 알려진 것처럼 HBM은 여러 개의 D램을 TSV를 통해 쌓아 데이터 전송속도를 높이는 것이죠.
지난해 SK하이닉스는 반도체 올림픽이라 불리는 ‘국제 고체 회로 학술회의(International Solid-State Circuit Conference, ISSCC)’에서 341GB/sec(초)의 속도를 가진 ‘2세대 고대역폭 메모리(High Bandwidth Memory, HBM2)’를 선보인 바 있습니다.
좀 더 자세히 살펴보면, 사실 HBM은 지난 2014년 AMD와 SK하이닉스가 협력해 만든 작품입니다. 당시만 하더라도 명확한 표준은 없었고, 말 그대로 백지에 그림을 그리는 과정에 있었습니다. SK하이닉스의 고민은 단순했습니다. 용량과 데이터 전송속도를 동시에 높이는 것이었죠.
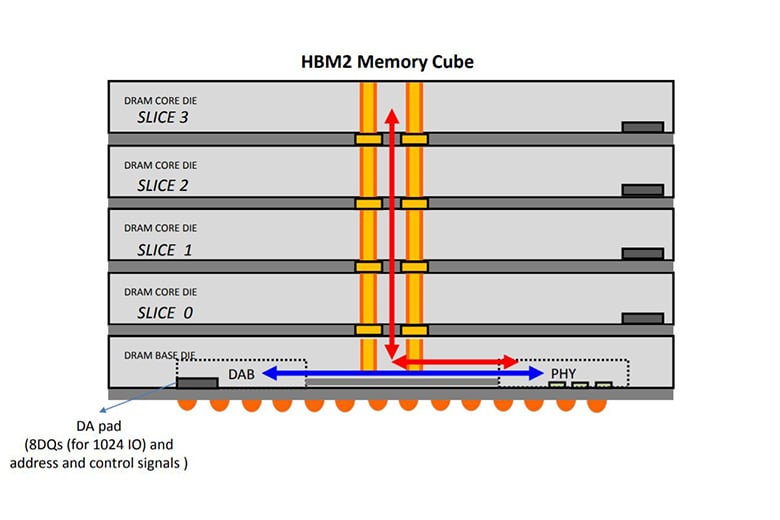
▲ TSV는 한 마디로 초고층 빌딩을 오르내리는 엘리베이터다.
▲ 앞으로 모든 반도체는 하나의 칩 안에 여러 단계의 적층이 필수적일 것으로 예상된다.
하지만 작업은 순탄치 못했습니다. 가장 큰 문제는 TSV 그 자체에 있었습니다. TSV는 회로 기판과 칩 사이에 들어가는 기능성 패키지판인 ‘인터포저’ 위로 회로 칩, 그리고 겹겹이 D램이 올라가 있는 형태입니다. 아파트를 연상하면 이해가 쉽습니다. 요즘 많이 찾아볼 수 있는 필로티(인터포저) 위에 커뮤니티센터(로직 칩)가 있고, 다음으로 각 세대(D램)가 얹혀진 모습이라고 생각하면 됩니다.
이런 상태에서 TSV는 여러 층의 반도체를 뚫고 지나가면서 데이터를 부지런히 이동시켜야 하는데 예상치 못하게 너무 많은 부하(負荷)가 생기게 됩니다. 이는 TSV 망 구성(토폴러지, topology) 방식이 ‘멀티-드롭(Multi-Drop)’ 방식으로 구성되어 있었기 때문입니다. 결국 다른 방법을 찾아야 했습니다.
컴퓨터는 당연히 대역폭이 좋을수록 데이터 처리가 빨라집니다. 다만 복잡해지는 신호와 이로 인한 간섭현상, 치솟는 원가 등을 해결해야 합니다. 대역폭을 높이는 방법에는 멀티-드롭 외에도 ‘싱글-엔드(Single-ended)’, ‘디퍼런셜(differential)’, ‘P-디퍼런셜’, ‘포인트 투 포인트(Point to Point, P2P)’ 등이 있습니다. 이 가운데 SK하이닉스는 멀티-드롭을 사용하다가 최근 P2P 방식을 도입하죠.
그런데 이름이 재미있습니다. ‘스파이럴 P2P(Spiral P2P)’입니다. 간단하게 말해서 망 구성 방식을 직렬에서 나선형으로 바꿨다고 보면 됩니다. TSV가 8채널(8층)을 뚫고 지나가는 것은 기존과 다르지 않지만, 데이터 송수신(TX/RX)에 변화를 줬다고 이해하면 됩니다. 조금 억지스럽지만, 중앙처리장치(CPU)와 비유하면 싱글 코어만 쓰다가 멀티 코어로 진화한 셈입니다.
서버를 넘어 컴퓨팅 전 분야에 활용
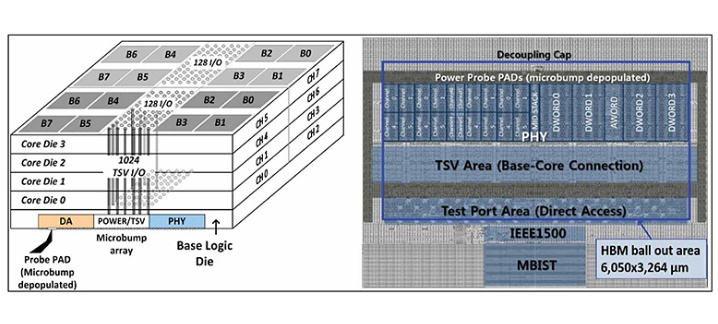
▲ 망 구성 방식의 변화로 HBM2의 성능이 크게 개선됐다.
SK하이닉스가 처음부터 스파이럴 P2P가 아닌 멀티-드롭을 사용한 이유는 ‘용량’과 ‘속도’를 모두 잡으려는 목적 때문으로 보입니다. 2채널부터 8채널까지 같은 망 구성으로 유연하게 라인업을 구성하려고 했던 것이죠. TSV의 성능을 한계까지 끌어내려던 것 같습니다. ‘상남자’ 스타일이네요.
스파이럴 P2P로 망 구성 방식의 변경은 앞으로 일어날 몇 가지 사건을 암시하고 있습니다. 첫 번째는 20나노에서 10나노 D램 시대로의 진입을 염두에 뒀다는 점, 두 번째는 성능에 있어 저전력의 중요성, 세 번째는 애플리케이션(적용분야)의 확대입니다.
SK하이닉스는 멀티-드롭에서 스파이럴 P2P로의 변경하면서 전력소비량이 30% 줄고 크로스토크와 같은 간섭현상이 개선됐다고 밝혔습니다. 현재 2세대 HBM(HBM2)은 20나노 D램으로 만들고 있지만, 10나노로 진입할 경우 용량이 늘어나게 되므로 32GB 이상의 고용량 시대를 대비할 필요가 있습니다.
현재 어떤 HBM2라도 칩 하나당 구현할 수 있는 용량은 최대 8GB에 머무르고 있습니다. 시스템온칩(SoC)에 붙일 수 있는 최대 용량은 32GB(8GB×4)에 불과하죠. 서버의 메모리 용량이 테라바이트(TB) 시대에 진입했다는 점을 생각하면 아직 갈 길이 멉니다. CPU나 그래픽처리장치(GPU) 등 일부 제품에서만 HBM이 쓰이는 이유가 여기에 있습니다.
따라서 HBM은 당연히 서버 시장을 노릴 수밖에 없습니다. 물론 지금도 서버에 적용되고 있으나 어디까지나 보조적인 역할에 머무르고 있습니다. 주메모리는 여전히 D램의 영역이죠. 한계극복을 위해서는 새로운 방식이 계속해서 시도되어야 합니다.
쓰임새 다양해지면 더 많은 기회 생길 듯
▲ SK하이닉스의 HBM2는 기존의 DDR3 대비 256GB/s 이상의 고속, 저전력 제품으로 세계적 수준의 성능을 자랑한다. 이 제품은 그래픽, 서버, 슈퍼 컴퓨터, 네트워크 등의 다양한 응용분야에 쓰일 예정이다.
HBM 자체가 널리 사용될 필요가 여기에 있습니다. 위에서도 언급한 것처럼 TSV를 구현하기 위한 인터포저의 가격이 비싸 대중화에 걸림돌이 되고 있죠. 하지만 보급형 HBM이 선보이면 상황이 달라질 것으로 보입니다.
국제반도체표준협의기구(Joint Electron Device Engineering Council, JEDEC)에 따르면 보급형 HBM은 D램 적층을 위한 베이스 다이(로직 칩)를 없애고 인터페이스 대역폭을 1024비트에서 512비트로 줄였습니다. 여기에 에러보정기술(ECC)을 빼고 비용 상승이 가장 큰 인터포저 재료를 무기물인 실리콘에서 유기물로 대체한다는 계획입니다. 그런데도 최대 데이터 전송속도는 200GB/sec 정도로 유지할 수 있습니다.
사양으로 따지면 보급형 HBM은 HBM2의 가장 낮은 등급의 제품과 엇비슷한 성능을 낼 것으로 예상합니다. 물론 인터페이스 대역폭의 제한, ECC 제외, 유기물 인터포저의 검증 등의 문제로 인해 지금과 같이 서버나 기업 시장을 목표로 삼기는 어려울 것으로 보입니다. 물론 그만큼 가격이 저렴해지기 때문에 고급형 그래픽카드 등에 손쉽게 접목할 수 있습니다.
생각의 속도는 언제나 기술을 앞서 왔습니다. 제품은 확실성의 결정체이지만 생각은 불확실성의 ‘끝판왕’이거든요. 불확실성은 확실성보다 더 큰 영역입니다. 그렇기 때문에 여러 사람의 생각으로 더 나은 제품을 만들 수 있습니다. SK하이닉스가 연구개발(R&D)에 실패해도 상을 주고, 반도체 혁신을 위해 일반인 대상으로도 아이디어를 공모하는 이유가 이겁니다. HBM은 이제 막 시작한 새로운 메모리 영역입니다. 그러니 더 많은 개선과 발전이 이뤄질 겁니다. 그 중심에 언제나 생각이 있다는 점을 잊지 말아야 합니다.
※ 본 칼럼은 반도체/ICT에 관한 인사이트를 제공하는 외부 전문가 칼럼으로, SK하이닉스의 공식 입장과는 다를 수 있습니다.


