이 칼럼 시리즈는 『최리노의 한 권으로 끝내는 반도체 이야기』의 일부를 발췌하여 정리했다. 이 책은 반도체 역사부터 시스템과 소자의 발전까지 폭넓게 다루며 반도체 산업 및 시스템 전반을 소개하고 있다.
반도체는 부품이다. 부품은 그 자체로 쓰이지 못하고 어떤 제품(시스템 혹은 세트) 내에서 사용된다. 시스템이 추구하는 바가 그 부품인 반도체의 탄생과 발전을 가져왔고, 앞으로 나올 새로운 시스템은 반도체의 변화를 요구하고 있다. 본 연재에서는 반도체를 시스템과 연결해 설명하며 과거와 미래, 앞으로의 발전 방향에 관해 7편에 걸쳐 이야기하고자 한다. (필자 주)
반도체 산업은 어떤 이유로 모든 산업 중 가장 중요한 산업이 되었을까? 그것은 반도체가 인류 사회에서 기여하고 있는 역할 때문이다. 반도체는 단순히 하나의 전자 부품이 아니다. 인류가 누리고 있는 발전 속도를 책임지고 있다. 복잡한 도시의 교통 제어, 신속하고 정확한 일기예보, 실감 나는 영화 및 게임 그래픽, 자율주행 자동차의 사물 인식 등 인류의 발전은 정보 처리 속도에 비례한다. 그런데 이러한 속도 증가는 많은 부분 반도체 소자의 성능 향상에 의존하고 있다. PC, 인터넷, 스마트폰, AR(Augmented Reality, 증강 현실), VR(Virtual Reality, 가상 현실) 등 지난 50년간 우리가 갖게 된 전자기기의 모든 신문물은 반도체 소자의 성능 발전으로 속도는 빨라지고 전기를 적게 쓰게 되었기 때문에 가능했다.
존 폰노이만(John Von Neumann)이 제안했던 컴퓨터의 기본 구조는 반도체 산업에 명확한 목표를 제시했다. CPU 기업은 제어와 연산을 빠르게 할 CPU를 만들면 됐다. 메모리 기업은 더 많은 정보를 담을 수 있도록 집적도 높은 메모리 소자를 만들면 됐다. 이 빠른 CPU와 집적도 높은 메모리는 모두 소자 미세화를 통해 달성 가능했다. 이를 통해 고집적화와 저전력도 동시에 달성할 수 있었다. 인류는 반도체 소자 미세화에 의존해 컴퓨팅 속도를 10년에 1,000배씩 증가시켜 왔다.
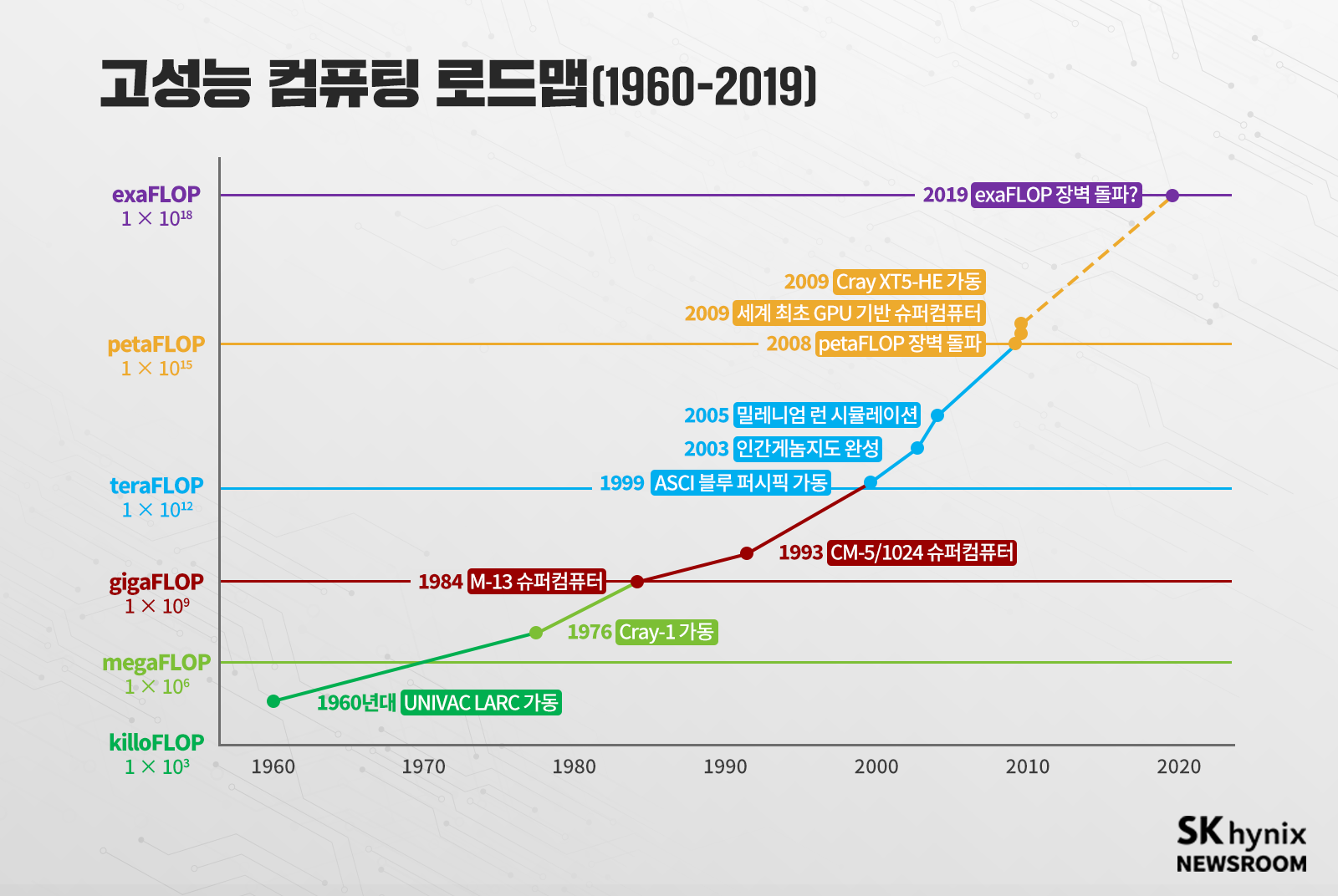
그러나 무어의 법칙으로 상징되는 소자 미세화는 가까운 미래에 멈출 수밖에 없다. 단위 소자의 크기가 분자 크기에 점점 가까워지고 있기 때문이다. 실제로 그동안 전 산업의 종합적인 R&D를 이끌어 왔던 국제 반도체 기술 로드맵(International Technology Roadmap for Semiconductors, ITRS)은 2015년을 마지막으로 더는 소자 미세화 발전에 관한 로드맵을 만들지 않기로 했다.
‘소자 미세화가 한계에 부딪혀 인류의 연산 속도 발전도 멈추는 것인가’ 하는 의문이 들 수밖에 없다. 절대로 그런 일은 일어나지 않을 것이다. 인류는 반드시 방법을 찾아 발전을 지속할 것이다. 이번 연재에서는 컴퓨팅 속도를 높이기 위해 현재 연구되는 다양한 방향과 새로운 반도체 소자 기술에 관해 이야기해 보고자 한다.
폰노이만 구조의 ‘속도 한계’를 극복하려는 반도체 연구
컴퓨터는 폰노이만 구조(아키텍처)로 이뤄져 있고 그것은 CMOS 기술로 통칭되는 반도체 집적 소자 기술로 구현한 것이다[관련기사]. 원래 CMOS 기술은 로직 기술의 일종을 말하지만, 메모리 소자 기술까지 포함하여 실리콘(Si) MOSFET* 소자를 사용하는 현재의 반도체 집적 소자 기술을 의미하는 용어로 많이 사용된다.
* MOSFET: Metal, Oxide, Semiconductor로 금속 산화막 반도체 구조를 통해 전기가 있는 영역인 전계(Field)의 효과(Effect)를 활용한 트랜지스터
소자 미세화로 성능 향상이 어려운 현실에서 컴퓨팅 속도를 빠르게 할 방법은 MOSFET을 만들고 있는 Si 채널*을 더 성능 좋은 물질로 대체해 트랜지스터를 만드는 것이다. 이 같은 시도는 꽤 오랜 기간 연구됐다. Si의 전하 이동도*는 전자가 1,500㎠/V·s, 홀은 500㎠/V·s 정도가 한계다. 그러므로 이보다 더 큰 전하 이동도를 갖는 물질을 채널로 사용해 전류를 더 많이 흐르게 하려는 시도가 이어졌다.
* 채널: 반도체 내에서 일종의 전자 이동 통로
* 전하 이동도: 전자가 전기장 내에서 얼마나 빨리 움직이는지 나타낸 정도. [길이2/전압·시간] 단위를 가진다.
저마늄(Ge) 채널의 경우 전하 이동도는 4,000㎠/V·s, 홀은 2,000㎠/V·s 정도로 Si 채널보다 크다. 특히 홀의 전하 이동도가 Si 대비 매우 우수하다. 그래서 pMOSFET에 Si 채널 대신 Ge을 사용하려는 연구가 계속됐다. 반면 nMOSFET은 전하 이동도가 매우 큰 3-5족 반도체*(GaAs, InAs 등)로 대체하려는 시도가 이어져 오고 있다.
* 3-5족 반도체: 주기율표상 3족과 5족에 해당하는 원소를 결합한 화합물 반도체
그러나 Ge이나 3-5족 반도체 같은 물질은 MOS(Metal·Oxide·Semiconductor, 금속 산화막 반도체 구조)를 만들었을 때 유전체 산화막과 반도체가 만나는 면에 전기적 결함이 많이 생기고 품질이 좋지 못하다. 실제로 만들었을 때 이론으로 예측한 것보다 소자 성능이 턱없이 떨어지고 심지어 Si보다 나쁜 경우가 많다. 오랜 기간 사용할 때 필요한 신뢰성도 Si 채널에 비해 떨어지는 경우가 많아 사용을 못하고 있다.
이 밖에도 전하 이동도가 수십만으로 알려진 카본 나노 튜브(Carbon Nano Tube)나 그래핀(Graphene)과 같은 2D 물질*을 Si 대신 채널로 사용하려는 시도도 있다. 그러나 카본 나노 튜브의 경우 소자 한 개의 성능은 좋으나, 수백억 개의 소자를 집적하기 위해 소자를 원하는 곳에 정확히 만드는 게 쉽지 않다. 반도체 집적 공정 기술에 적합하지 않은 것이다.
* 2D 물질: 수개의 나노미터 원자가 한 층으로 배열되어 있는 2차원 결정성 물질
카본 나노 튜브와 달리 그래핀은 평면 형태다. 때문에 Si 웨이퍼 위에 옮겨서 사용할 경우 포토리소그래피 등 현재 우리가 사용하는 반도체 집적 공정 기술을 이용해 집적회로를 만들 수 있을 것으로 보였다. 그러나 연구 결과 그래핀으로는 현재 MOSFET과 같은 크기와 성능의 소자를 만드는 것이 쉽지 않은 것으로 밝혀졌다. 물질 특성상 트랜지스터로 제작했을 때 누설 전류를 줄이기 쉽지 않고, 트랜지스터에서 채널의 전류를 외부로 나올 수 있게 해주는 금속 배선과의 접촉 저항도 기존의 Si 채널 대비 큰 약점을 보였다. 다른 2D 반도체들도 비슷한 약점을 보이고 있다.
컴퓨팅 속도를 높이는 또 다른 방법은, MOSFET이 아닌 다른 형태의 스위치 소자를 만들어 사용하는 것이다. 터널 펫(Tunnel FET)*이나 강유전 물질(Ferroelectric Material)*을 MOS의 산화막 대신 적용한 네거티브 커패시턴스 펫(Negative Capacitance FET)과 같은 것이다. 이러한 트랜지스터는 MOSFET보다 빠르거나 저전력이 될 것으로 여겨져 연구가 진행되고 있다. 그러나 이러한 노력으로 가져올 수 있는 연산 속도 향상은 제한적일 수밖에 없다.
* 터널 펫(Tunnel FET): MOSFET의 평평한 구조를 터널 모양으로 형성하는 기술
* 강유전 물질(Ferroelectric Material): 외부에서 전기장을 가하지 아니하여도 전기 분극(分極)을 나타내는 물질
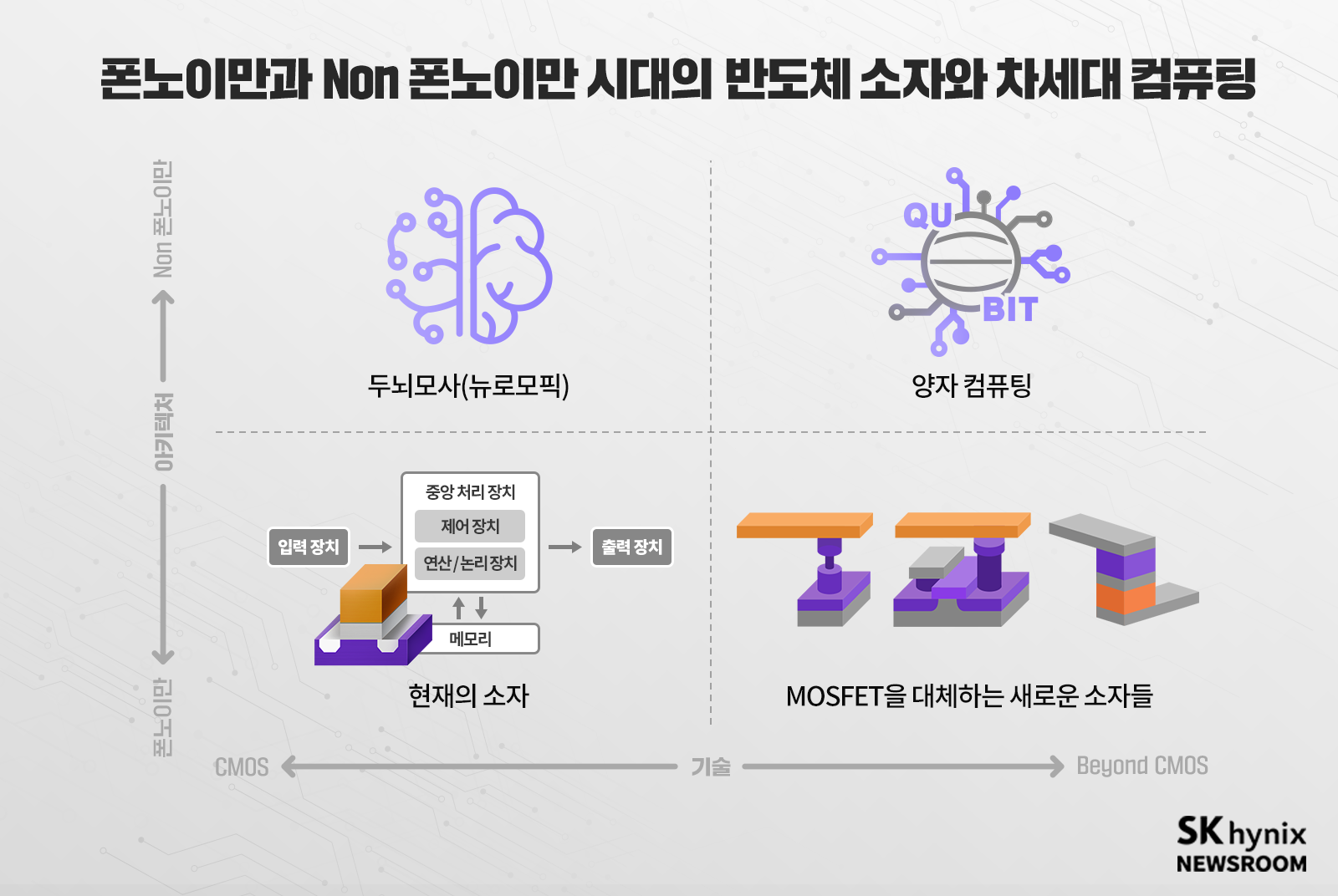
폰노이만 자체를 벗어나려는 차세대 컴퓨팅 연구: 뉴로모픽 컴퓨팅
그래서 더 근본적인 변화를 통해 연산 속도 향상의 한계를 극복하려는 시도도 있다. 현재 우리가 사용하는 폰노이만 구조 자체에 변화를 준 컴퓨터를 만들어 사용하는 것이다.
폰노이만 구조의 가장 큰 약점인 폰노이만 병목 현상*을 줄이기 위한 방법도 그중 하나다. 물리적으로 대역폭을 늘리기 위한 3D Integration* 기술부터 같은 대역폭에서 지나는 정보의 양을 줄여주기 위한 PIM(Processing-In-Memory)* 기술[관련기사]까지 다양하다.
* 폰노이만 병목 현상: CPU 처리 속도가 빠를 경우 다음에 처리해야 할 데이터가 메모리에서 도달하지 못해 CPU가 대기하는 상황이 발생하는 현상
* 3D Integration: 서로 다른 칩을 최대한 가까운 위치에 통합, 연산을 위한 데이터 이동 경로를 최소화해 최상의 성능과 효율을 내는 하나의 칩으로 완성하는 것
* PIM(Processing-In-Memory): 메모리 반도체에 연산 기능을 더해 인공지능(AI)과 빅데이터 처리 분야에서 데이터 이동 정체 문제를 풀 수 있는 차세대 지능형 메모리
폰노이만 구조를 벗어나려는 시도로, 최근 가장 열심히 연구되는 분야는 인간의 뇌 신경망 구조를 흉내 낸 ‘뉴로모픽 컴퓨팅(Neuromorphic Computing)’이다. 인간의 뇌는 숫자 계산에서는 컴퓨터 대비 매우 느리나, 컴퓨터를 압도하는 특정 분야가 있다. 사물을 인식하고 판단하는 영역이다.
인간이 고양이와 개를 구별하는 것은 많은 시간이 걸리지 않는다. 그러나 컴퓨터가 폰노이만 구조에서 이것을 구별하는 것은 짧은 시간에 가능하지 않다. 이렇게 인간이 빠르게 구별할 수 있는 것은 매우 오랜 기간 학습을 통해서 고양이와 개의 특징을 파악하고 인간의 두뇌 신경망에 기억하고 있기 때문이다.
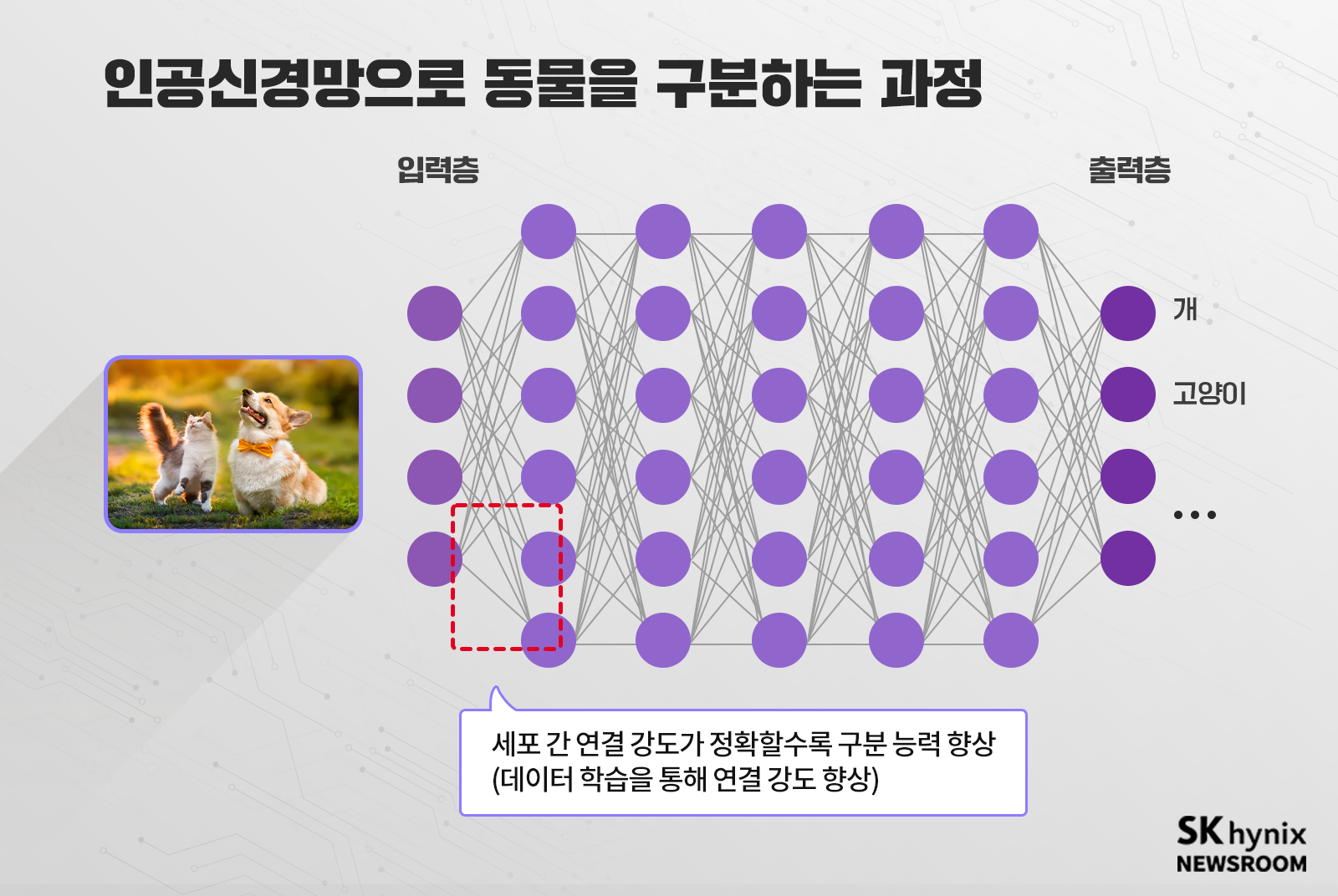
이처럼 학습을 통한 인간 두뇌 활동 방식을 모사해 작동하도록 한 것이 인공지능이다. ‘인공신경망(Artificial Neural Network)’을 구성하고 학습을 통해 인식과 판단을 하게 한 것이다.
현재 엔비디아(NVIDIA) 등에서 출시한 인공지능 칩들은 CMOS 기반의 소자와 칩을 이용해 만들어지고 있다. CPU와 GPU를 D램과 같은 메모리 소자와 연결해 구현한 것이다. 학습을 위해 필요한 대용량의 구조화된 데이터를 대역폭이 큰 고성능 메모리 HBM* 등을 통해 GPU에 공급, 병렬 연산을 통해 학습하도록 하고 그 가중치(학습한 데이터) 역시 메모리를 통해 저장하는 형태로 구현됐다. 지금 컴퓨터에서 사용 중인 디지털 방식을 그대로 이용해 두뇌의 활동 방식을 모사한 것이다.
* HBM(High Bandwidth Memory): 여러 개의 D램을 수직으로 연결해 기존 D램보다 데이터 처리 속도를 혁신적으로 끌어올린 고부가가치, 고성능 제품
인간의 두뇌는 20와트(Watt) 정도의 전력만 소모하는 것으로 알려졌다. 그러면서도 공부를 하고 주변을 살피고 대화를 하는 등 다양한 일을 동시에 할 수 있다. 그러나 우리가 만든 인공지능 칩은 제한된 일만 수행하면서 훨씬 높은 전력을 소모한다. 그래서 현재 연구 방향은 인간 두뇌 신경망의 형태를 그대로 모방하는 쪽으로 향하고 있다. 뇌가 연산하는 활동 방식만 모방한 것이 아니라 하드웨어 자체를 뇌의 구조와 기능을 모사한 전자기기로 만들려는 것이다. 그래서 메모리 사용을 최소화하면서 전력을 아끼고 더 많은 연산 기능을 수행할 수 있도록 연구 중에 있다.
인간 두뇌는 정보를 처리하는 코어 역할의 뉴런과 뉴런 사이를 연결하는 시냅스*로 구성됐다. 뉴런 간에는 스파이크(전기적) 신호를 주고받아 정보를 처리한다. 이때 각 시냅스의 강도는 뉴런에 전달하고자 하는 정보에 따라 세기가 정해진다. 인간의 뇌에는 약 1,000억 개의 뉴런이 있으며 각 뉴런은 약 1,000~10,000개의 시냅스를 통해 다른 뉴런과 연결되어 있다. 그리고 학습을 통해 시냅스가 가지는 강도를 조절해 나간다. 이처럼 인간 두뇌 신경의 뉴런과 시냅스의 기능을 그대로 흉내 내는 전자 소자를 만들어, 정말로 두뇌 신경이 움직이듯 만들려는 것이 뉴로모픽 컴퓨팅이다.
* 시냅스: 신경세포접합부(神經細胞接合部)로, 한 뉴런에서 다른 뉴런으로 신호를 전달하는 연결 지점을 말함. 뉴런의 축삭돌기 말단과 다른 신경세포와 연결되는 부위
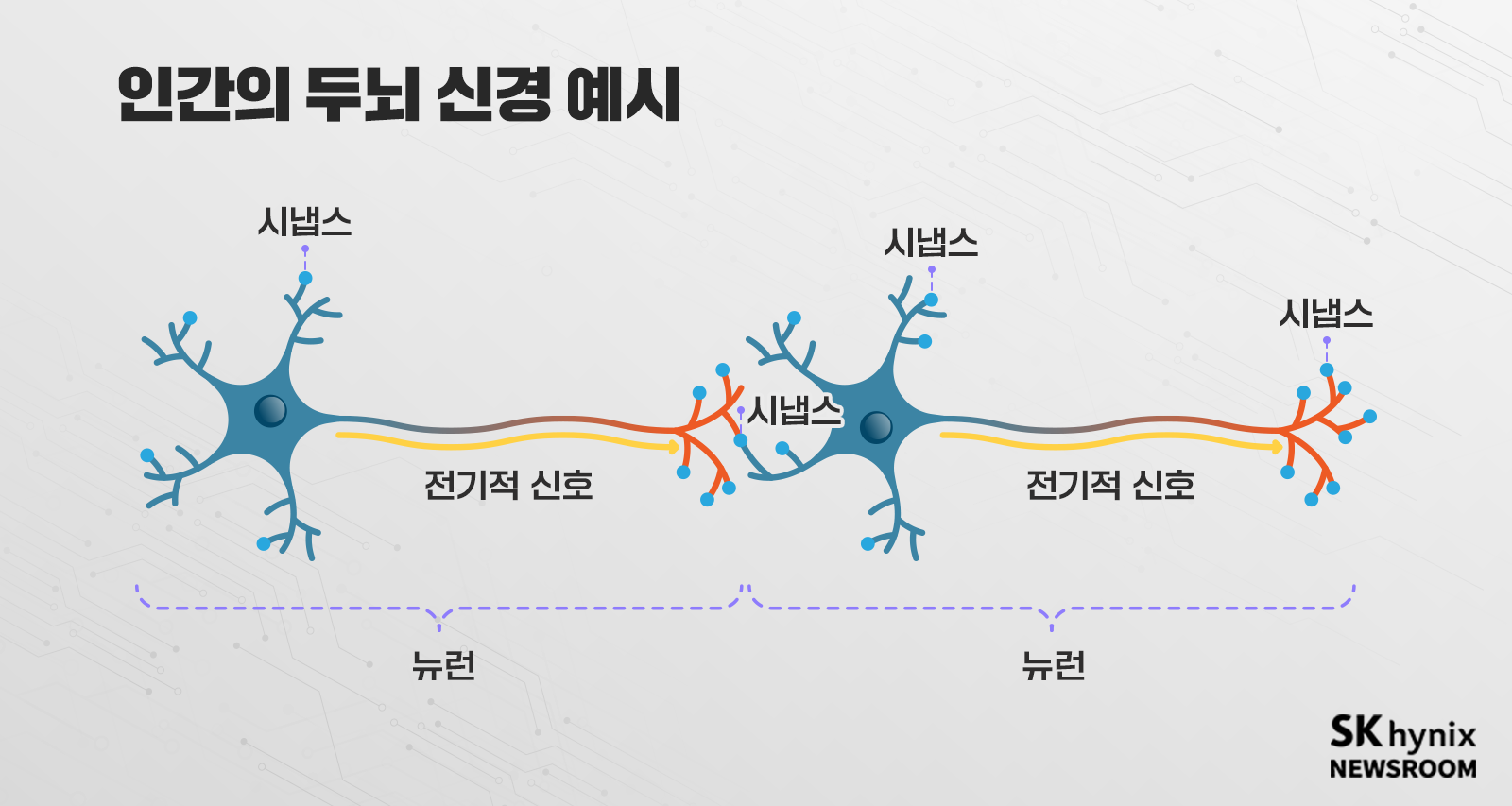
이 분야에선 특히 두뇌 움직임에 가까우면서 에너지가 효율적인 스파이킹 신경망(Spiking Neural Networks, SNN)을 구현하기 위한 연구가 진행되고 있다. 뉴런은 CMOS 기반의 회로를 사용하고, 시냅스는 그 특성을 모방한 비휘발성 메모리 소자로 구성해 보려 하고 있다.
여러 단계의 시냅스 강도를 표현하며 시냅스 학습을 실현하기 위해서는 멤리스터(Memristor)가 제격이다. 멤리스터는 메모리(Memory)와 레지스터(Resistor)의 합성어로, 양단에 인가되는 특정 전압 펄스에 따라 저항이 변하는 특성을 가진 소자를 일컫는다. 지난 회에서 소개했던 새로운 메모리를 위한 소자인 ReRAM(Resistive RAM), PCRAM(Phase Change RAM), MRAM(Magneto-Resistance RAM), FeRAM(Ferroelectric RAM) 등이 대표적인 멤리스터 소자다.
현재 이들 소자를 3D 크로스포인트로 연결, 시냅스 어레이(Array)를 만들어 사용하려는 연구가 진행되고 있다. 이 소자들은 양단에 인가되는 전압 패턴에 따라 저항이 선형적(Linear)으로 커지거나(Potentiation) 작아져야(Depreciation) 시스템에 사용 가능하다. 그러나 아직까지 비선형적인 문제가 발생하고, 오랜 시간 저항값을 유지하는 능력(Retention)에도 문제가 있어 이를 해결하기 위한 연구가 진행되고 있다.
폰노이만 자체를 벗어나려는 차세대 컴퓨팅 연구: 양자 컴퓨팅
논(Non)-폰노이만 구조를 이용한 컴퓨팅이면서 아예 0, 1의 디지털 체계를 벗어난 연구도 진행되고 있다. 원자나 전자처럼 아주 작은 세계에서 일어나는 자연 현상을 설명해 주는 체계인 양자역학을 이용한 ‘양자 컴퓨팅(Quantum Computing)’이 그것이다.
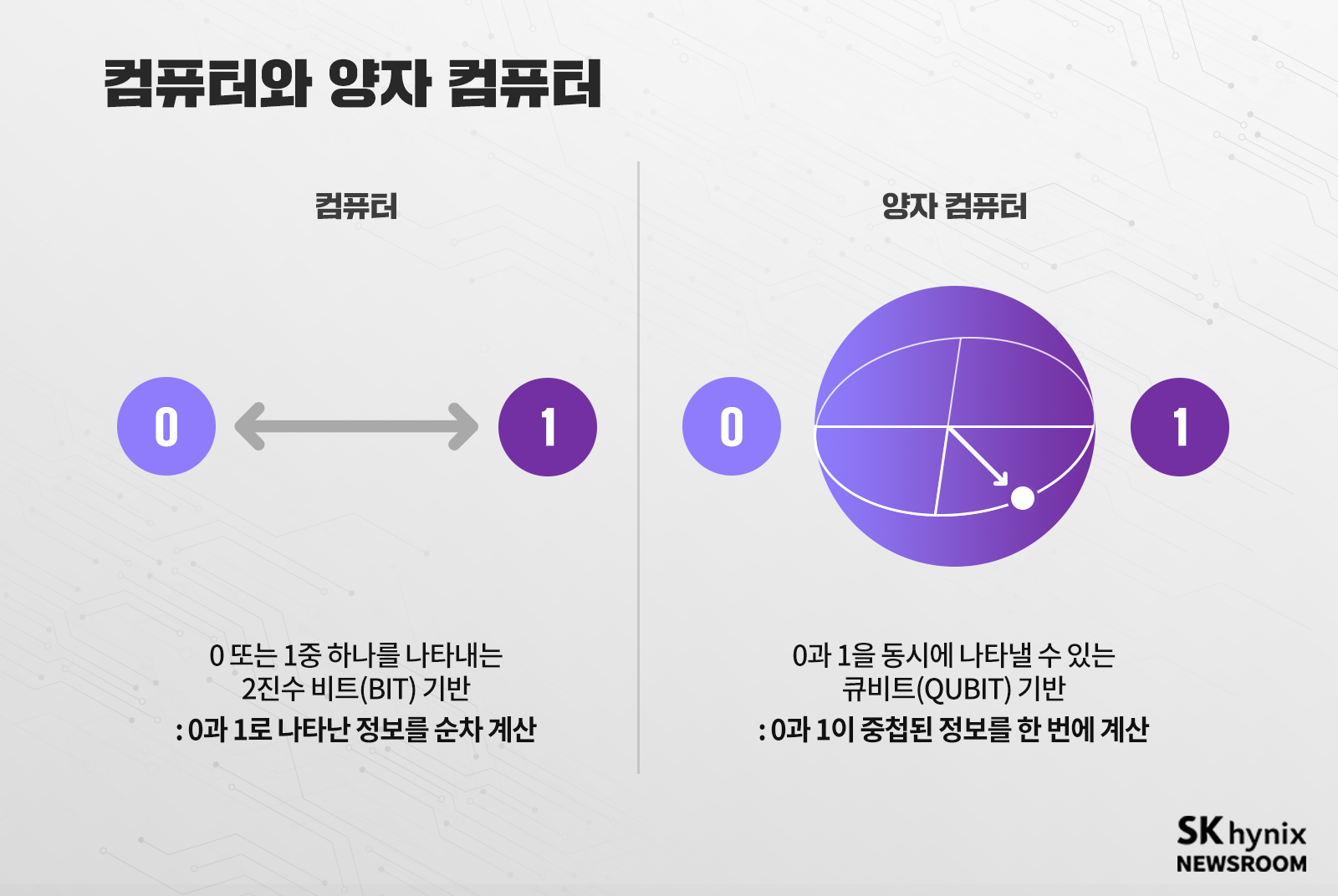
양자역학은 입자이면서 파동이고, 0이면서 1이고, 뭔가 흐릿하고, ‘불확정성의 원리’란 것이 지배하는 모호한 세계다. 그러한 양자역학의 현상을 능동적으로 제어하면서 작동시키는 것을 양자 컴퓨팅이라고 한다. 이와 같이 양자 현상을 구현하는 소자를 큐비트(Qubit)*라고 부른다. 0 또는 1의 신호를 순차로 처리하는 일반적인 반도체 소자와 달리, 0과 1의 중첩된 데이터를 동시에 빠르게 처리한다. 큐비트를 만드는 것은 여러 가지 방법이 있다. 초저온에서 나타나는 초전도 현상*을 이용한 조셉슨(Josephson) 소자*를 활용하는 방법이 대표적이다.
* 큐비트(Qubit): Quantum Bit 줄임말, 양자 컴퓨터 또는 양자 정보의 기본 단위로, 즉 0과 1 두 개의 상태를 가진 양자비트로 양자 컴퓨터의 최소 단위를 말한다.
* 초전도 현상: 특정 물질이 영하 273°C에서 저항이 0이 되며 반자성을 띠는 현상, 이 현상을 통해 소자를 구현하면 경미한 영향에도 변형되는 큐비트를 항구적으로 유지할 수 있다고 알려졌다.
* 조셉슨(Josephson) 소자: 조셉슨 소자는 1962년에 브라이언 조셉슨에 의해 발견됐으며, 초전도체에 의해 만들어진 두 장의 박막 사이에 얇은 절연체를 사이에 끼웠을 때 절연체를 통해서 전류가 흐르는 현상(조셉슨 효과)을 이용하여 만든 스위칭 소자다.

큐비트 기반으로 데이터 처리 속도를 높인 양자 컴퓨터가 제대로 만들어진다면 양자 세계를 시뮬레이션해야 하는 화학, 물리, 제약 등의 분야에서 폰노이만 구조의 컴퓨팅 속도를 월등하게 앞지를 것으로 예상된다. 또한, 현재의 암호 체계를 이루고 있는 소인수를 찾아내는 데 월등한 양자 컴퓨팅은 정보 보안 측면에서도 크게 기여할 수 있을 것으로 기대한다.
이처럼 폰노이만 구조를 벗어나려는 차세대 컴퓨팅 연구는 활발하게 진행되고 있다. 그러나 뉴로모픽 및 양자 컴퓨팅이 완성된다고 해도 현재의 컴퓨팅을 완전히 대체하는 것은 아니다. 논리 연산은 폰노이만 구조의 성능을 넘어설 수 없다. 그러므로 다양한 구조(아키텍처)가 필요에 각자의 영역에서 함께 쓰이는 형태가 될 것이고, 폰노이만 구조의 속도 한계를 극복하기 위한 메모리 반도체 연구도 계속 발전될 것이다
※ 본 칼럼은 반도체에 관한 인사이트를 제공하는 외부 전문가 칼럼으로, SK하이닉스의 공식 입장과 다를 수 있습니다



