이번 연재는 컴퓨터와 반도체의 관점에서 인공지능을 살펴볼 것이다. 기존의 프로그램이 인공지능으로 바뀌면서 0과 1의 세계가 구체적으로 어떻게 변화하는 것인지 알아보고, 이를 실행하는 데 필수적인 반도체는 어떤 중요한 역할을 해야 하는지 확인해볼 것이다. 이를 통해 반도체는 인공지능을 포함한 새로운 ICT 기술의 등장에도 두려워하기보다는 세상을 변화시킬 혁명의 주인공이 될 것이다. (필자 주)
인공지능 시대의 개막
2012년, 사물 인식 대회였던 이미지넷 챌린지(ImageNet Challenge)에서 이변이 일어난다. 이미지넷 챌린지는 전 세계에 있는 사물 인식 알고리즘에 동일한 데이터를 준 뒤, 주어진 데이터 내에서 누가 더 정확하게 사물을 분류하는지 겨루는 대회다. 2012년 전까지 이 대회는 매해 극히 적은 수준의 정확도 개선이 일어나고 있었지만, 인공신경망 알렉스넷(AlexNet)이 대회에 등장하면서 그 흐름이 바뀐다.
알렉스넷은 수많은 사물 데이터를 인공신경망에 투입함으로써 신경망을 학습시키는 방식으로 만들어졌다. 알렉스넷은 기존의 사물인식 알고리즘과는 다르게 동작했다. 사진에 복잡한 처리를 하고 각종 특징을 뽑아내어 알고리즘에 전해주는 대신, 사진을 그대로 투입하면 인공신경망이 결괏값을 스스로 판단해내는 방식으로 동작했다. 알렉스넷은 대회에서 압도적인 차이로 우승했고, 이후 이미지넷 챌린지의 승자는 전부 인공신경망으로 변화하게 된다. 인공지능의 시대가 열렸음을 보여주는 상징적이고 결정적인 사건이었다.
인공지능이 메모리에 던진 과제
알렉스넷은 처음부터 GPU* 사용을 염두에 두고 만들어진 인공신경망이었다. 앞서 설명했듯 사물 인식 프로그램(인공지능)을 만들기 위해서는 수십억 개의 인공 뉴런 사이 연결 강도를 올바른 값으로 지정해줄 필요가 있다. 하지만 올바른 값은 단 한 번에 찾아낼 수 없다.
* GPU(Graphics Processing Unit) : 각종 대규모 병렬 연산에 강점을 가진 반도체. 본래 그래픽 처리에 사용되었으나, 인공지능 기술이 대규모 병렬 연산을 통해 구현 가능하다는 사실이 알려지면서 최근 인공지능 분야에서 큰 인기를 끌고 있다. GPU와 인공지능의 관계를 더욱 자세히 알고 싶다면 지난 칼럼을 참고바란다.
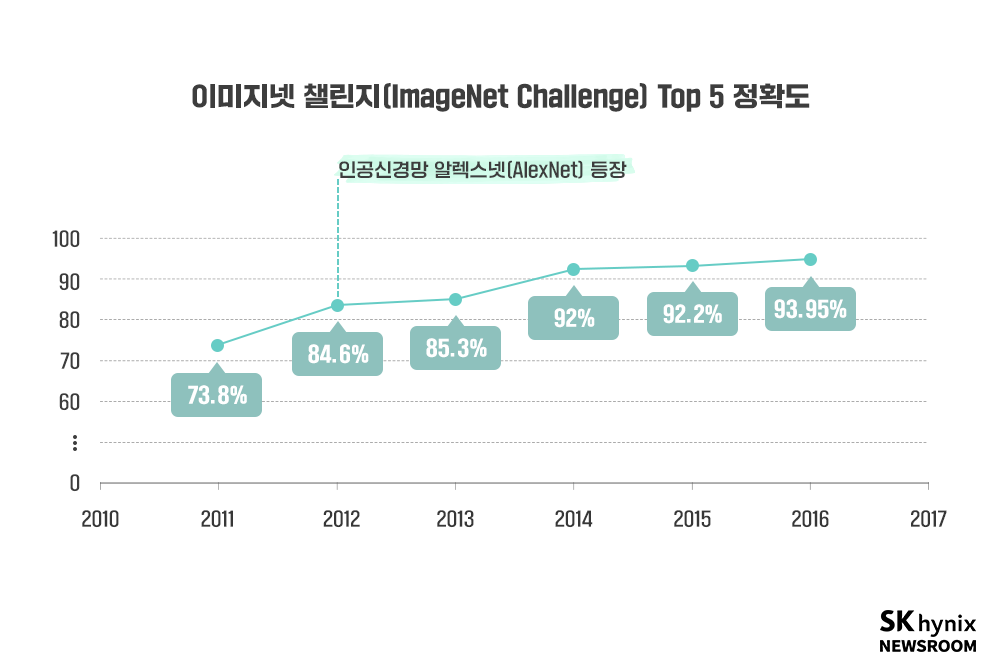
▲ 이미지넷 챌린지 TOP5 모델의 정확도는 2011년 73.8%를 기록했으나, 2012년 알렉스넷이 등장함에 따라 가파르게 상승, 2016년 93.95%에 다다르게 된다.
연구원들이 찾아낸 방법은 수없이 많은 데이터를 투입해가며 서서히 올바른 값을 찾아가는, 연산이 매우 많이 필요한 과정이었다. 이 과정에서 정확도가 50%에서 51%, 그리고 90% 이상까지 서서히 높아졌다. ‘프로그래밍’이라는 단어보다는 ‘학습’이라는 단어가 더 어울리는 이유이기도 하다.
한편, 인공신경망이 더 많은 사물을 정확하게 구분하기 위해서는 주어진 사진 내에서 더욱 다양한 정보를 뽑아낼 수 있어야 한다. 그렇게 하려면 신경망의 크기를 키우고, 더 많은 데이터를 투입해 학습시켜야 한다. 그러기 위해서는 더 큰 메모리가 필요하다. 실제 알렉스넷 논문에도 메모리 용량의 중요성을 언급하는 부분이 있음을 알 수 있다.
In the end, the network’s size is limited mainly by the amount of memory available on current GPUs and by the amount of training time that we are willing to tolerate.*
* 출처. ImageNet Classification with Deep Convolutional Neural Networks (nips.cc)
이 글에서 알 수 있듯, 네트워크(신경망) 크기를 키우지 못한 이유 중 하나로 메모리 용량을 언급하고 있다. 당시에도 연구팀은 더 큰 메모리와 학습 시간만 주어졌다면, 더 높은 점수를 낼 수 있다고 생각했을 것이다. 메모리가 인공지능 시대에 중요한 역할을 한다는 사실은 이미 11년 전부터 알려져 있던 것이다.
실제로 알렉스넷은 이런 한계를 뛰어넘기 위해 GPU 2개(GTX 580)를 결합하는 테크닉을 사용하는 등 다양한 연구를 해야 했다. 이 문제에 대해 메모리 회사가 내놓은 답은 무엇이었을까?
HBM : 고대역폭 메모리의 부상
메모리는 다양한 특성을 가졌다. 이중 메모리 구매자가 중요하게 살펴보는 특성은 대역폭(Bandwidth), 반응 속도(Latency), 용량(Capacity)이다. 대역폭은 메모리에서 한 번에 빼낼 수 있는 데이터의 양을 의미한다. 반응 속도는 CPU나 GPU의 요청이 들어왔을 때 얼마나 빨리 첫 반응을 할 수 있는지를 뜻한다. 용량은 메모리 안에 얼마나 많은 데이터를 담을 수 있는지를 말한다.
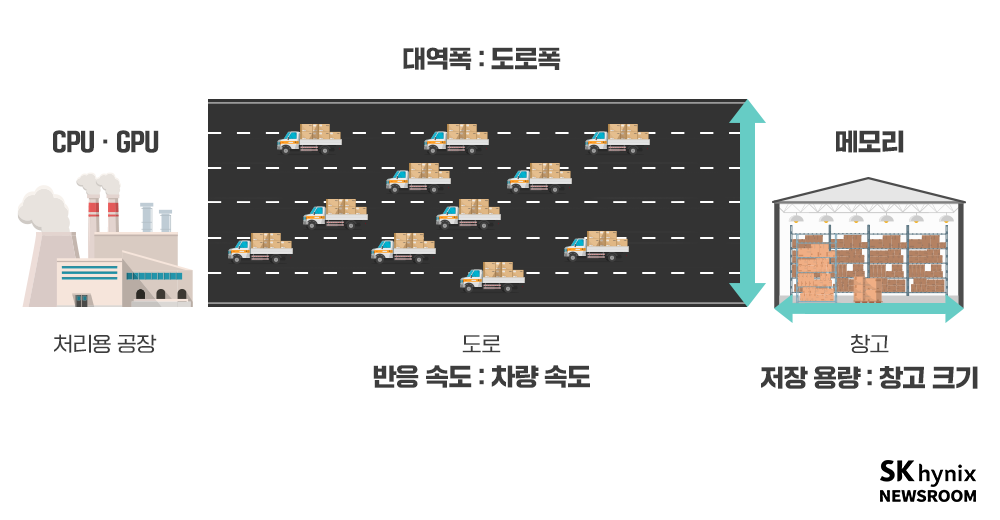
▲ 데이터가 메모리에서 CPU/GPU로 이동하는 모습을 적재물(데이터), 창고(메모리), 공장(CPU/GPU), 그리고 도로의 너비(대역폭)에 비유
메모리를 일종의 데이터 창고라고 한다면, 대역폭은 창고로 들어오는 도로의 너비다. 도로가 넓다면 한 번에 지나다닐 수 있는 자동차 수가 많음으로, 창고에서 많은 양의 데이터를 한 번에 빼낼 수 있다. 반응 속도는 도로 위에서 돌아다니는 자동차들의 속도다. 용량은 창고의 총 크기라고 생각하면 된다.

HBM*은 대역폭과 용량에 중점을 두고, 반응 속도를 다소 양보한 제품이다. 따로 제조된 D램 칩을 여러 개 적층한 뒤, D램에 TSV* 공법을 이용해 칩을 관통하는 전극을 생성하는 것이다.
* HBM(High Bandwidth Memory) : 여러 개의 D램을 수직으로 연결해 기존 D램보다 데이터 처리 속도를 혁신적으로 끌어올린 고부가가치, 고성능 제품
* TSV(Through Silicon Via) : 수천 개의 미세한 구멍을 뚫고 이를 관통하는 전극으로 여러 개의 칩을 연결해 데이터를 전달한다. 기존 방식 대비 신호 전달 속도가 빠르고, 집적도(Density)를 확보하기도 훨씬 용이함
HBM은 일반 PC용 D램과는 매우 구분되는 장점이 있다. 일단, D램을 여러 개 적층했으므로 기반 면적당 높은 용량을 확보할 수 있다. 그뿐만 아니라 반도체 제조에 가까운 방식인 TSV를 사용하기에 좁은 면적에 여러 D램의 데이터 연결 통로를 촘촘하게 밀집시켜 만들 수 있다. 덕분에 고작 칩 하나 면적 수준에서 메모리 4개 이상의 대역폭을 가진다. 4차선 도로를 짓는 대신 4개 층을 가진 1차선 도로를 만드는 셈이다. 다만, 칩을 적층한 이유로 발열 해소에 문제가 생길 수 있어, 개별 칩의 동작 속도는 약간 줄었다. 이로 인해 반응 속도에서 약간의 손해가 발생한다.
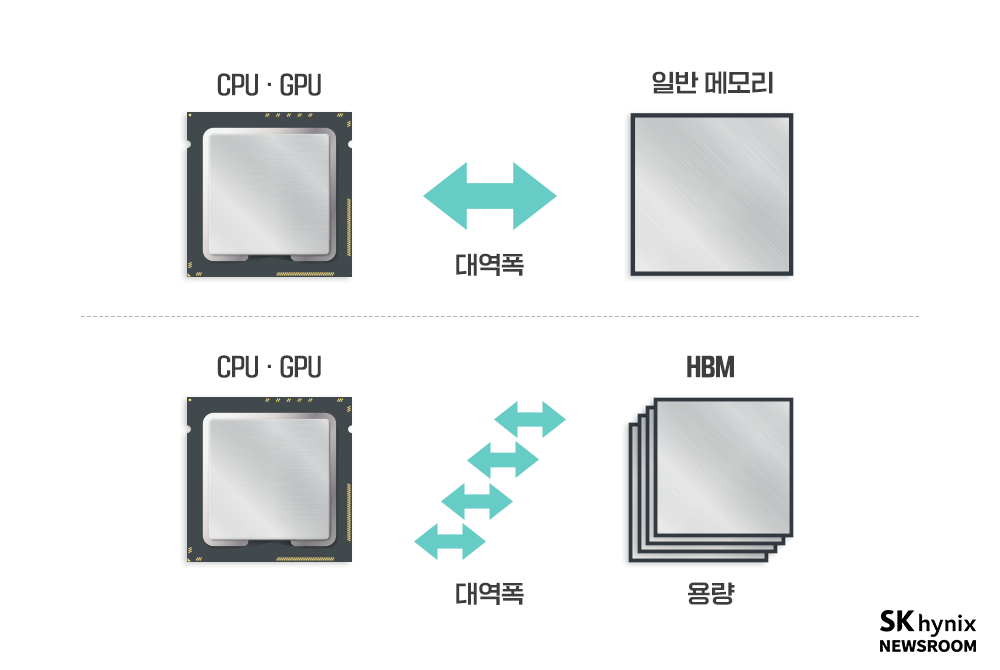
▲ 더 많은 대역폭을 가지는 HBM의 장점
본래 HBM은 고성능 그래픽 처리를 위해 탄생한 제품이다. 그래픽 처리는 모니터에 표시될 수백만 개의 픽셀(Pixel)을 계산해야 하기에 매우 높은 대역폭과 실수 연산 능력을 필요로 했다. 이로 인해 그래픽 처리는 컴퓨터 역사에서 일찌감치 CPU에서 독립하여 GPU, 혹은 VGA라는 이름의 그래픽 전용 가속 카드가 처리하게 발전했다.
메모리 회사들 역시 GPU가 요구하는 고대역폭 메모리를 GDDR(Graphics Double Data Rate)이란 이름으로 꾸준히 공급해 왔다. 그리고 인공지능학자들이 GPU를 이용해 돌파구를 열면서, GPU의 든든한 동반자였던 고대역폭 메모리 역시 날아오르게 된 것이다. 여기에 그래픽 처리를 능가할 정도로 높은 메모리 용량을 요구하게 되면서 HBM이 더욱 빛을 보게 된 것이다.
인공지능에 HBM이 필요한 이유: 학습
인공지능을 만드는 첫 단계는 학습이다. 학습은 과거의 프로그래밍으로 따지면 프로그램 자체를 구현하는 매우 중요한 작업이다. 연구원들은 신경망을 구성하고 난 뒤, 신경망을 초기화하고 본격적으로 학습 작업에 들어간다.
신경망 학습을 위해서 연구원들은 수만~수백만 개의 데이터를 준비한다. 이 데이터는 단순한 사진, 글자 등의 조합이 아니다. 연구원들은 문제-정답으로 한 쌍을 갖춰준 뒤 신경망이 특정 문제를 풀었을 때 오답을 내면 에러를 줄이는 방향으로, 신경망 내부 수백~수백억 개의 뉴런 연결 강도를 조정해 주고, 정답이 나왔을 경우 정답을 더 말하는 방향으로 연결 강도를 조정해 준다. 이는 24시간 내내 GPU를 구동해도 수시간, 수개월이 걸리는 매우 고된 작업이다. 학습 과정에서 각 인공 뉴런 사이의 연결 강도는 수십만 번 이상 변화한다.
당연하지만 이 작업을 빠르게 하기 위해서는 학습 데이터가 최대한 연산 장치에 가까이 있어야 한다. 먼 곳에 있는 학습 데이터를 가져와야 할 경우 학습 데이터를 전송하는 데 너무나 많은 시간이 들기 때문이다. 당연히 GPU 칩과 최대한 가까운 곳에 메모리를 두려 하게 된다. GPU 회사가 HBM의 큰 고객이 될 수밖에 없는 이유다.
또한 짐작할 수 있겠지만, 학습 과정에서 사용되는 메모리 용량은 추론* 시에 사용되는 메모리보다 훨씬 크다. GPU 내부 메모리에는 학습 대상 인공신경망 + 학습시킬 데이터 배치(Batch)* + 각종 연구 개발용 정보 등 다양한 데이터가 들어가야 하기 때문이다. GPU 내부에 한 번에 배치를 많이 넣을수록 학습이 안정적으로 진행될 수 있다. 실제로 신경망의 크기가 1이라고 하면, 학습 데이터에 사용되는 메모리가 4~5 이상 되는 경우도 있다.
* 추론 : 인공신경망이 실제로 문제를 푸는 행위
* 배치(Batch) : 일종의 인공신경망 학습 단위. 데이터의 묶음으로 구성됨
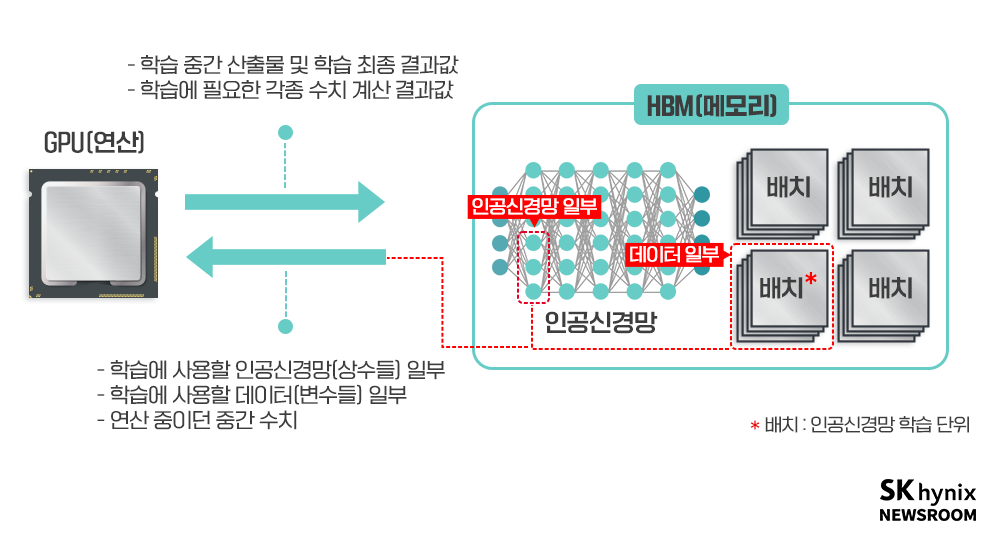
▲ GPU와 메모리가 하는 일, GPU는 메모리에 저장된 인공신경망 일부와 데이터 일부를 지속적으로 가져와 연산(학습 및 추론)하고 중간 산출물과 최종 결과 등을 메모리에 저장하는 과정을 반복한다.
고성능 GPU는 한 번에 처리 가능한 연산량도 크기 때문에, 한 번에 많은 데이터가 GPU 코어에 투입되어야 제 성능을 발휘할 수 있다. 거대한 재고 창고와 공장을 자전거 도로로 연결하면 공장이 쉴 수밖에 없다. 따라서 거대한 공장에는 넓은 도로가 필요하듯, 고성능 GPU 역시 큰 대역폭을 필요로 하는 것이다.
인공지능에 HBM이 필요한 이유 : 추론
한편, HBM은 학습뿐만 아니라 추론에서도 강력한 힘을 발휘하고 있다. 최근 챗GPT 등 초거대 언어 모델이 대두하기 시작했는데, 이들은 추론에도 매우 큰 메모리가 필요하다. 일반적으로 추론용 GPU는 NVIDIA T4 등 학습용 GPU보다는 메모리가 적은 GPU 모델이 사용된다. 하지만 초거대 모델의 경우 8~16GB 정도의 메모리로는 추론을 돌릴 수 없다.
지금 유행하는 챗GPT의 경우 자료형 선택에 따라 320~640GB 정도의 메모리를 사용할 것으로 예상된다. 이는 현재 필자의 작업용 컴퓨터 메모리의 10배 이상인 어마어마한 수치다. 컴퓨터 본체도 아니고, 부속으로 달리는 GPU가 이런 큰 용량을 감당해야 하는 것이다.
혹자는 GPU 대신, 거대한 서버 컴퓨터에 CPU를 탑재한 뒤 일반 메모리를 대량으로 탑재해 추론에 사용하면 되지 않느냐고 생각할지 모른다. 실제로 메모리 용량만 놓고 비교할 경우, CPU에 메모리 640GB가 탑재된 서버가 GPU로 640GB를 확보한 것보다 더 싸다. 하지만 이 경우 추론 속도가 너무 느려 사용하기 힘들어진다. Hugging Face*에 공개된 GPT-2 알고리즘 기준 CPU에서 추론 시 처리당 0.05~0.1초의 시간이 필요했다. 이보다 100배 이상 거대한 GPT-3 모델의 경우, CPU에서 처리당 10초 이상이 소요된다는 의미다. 이는 상업적으로 사용하기 힘든 속도다. 결국 GPU를 엮어서 쓸 수밖에 없는 것이다.
* 참고. Accelerated Inference with Optimum and Transformers Pipelines (huggingface.co)
당연히 이런 대용량 메모리를 GPU에 탑재하기 위해서는, 면적당 메모리 집적도가 매우 높아야 한다. 현실적으로 메모리 회사가 1~2년 만에 D램 칩 자체 밀도를 3~4배 늘리는 것은 불가능하다. 그 때문에 HBM과 같은 면적 대비 밀도가 높은 칩이 필요한 것이다. 물론 HBM을 사용할 경우 GB당 가격은 일반 DDR 메모리보다 훨씬 높아지게 되지만, 인공지능 기술이 가져다주는 매우 높은 부가가치 덕분에 칩의 인기는 매우 높다.
HBM을 사용하는 NVIDIA A100 카드와 GDDR을 사용하는 NVIDIA A6000 카드의 메모리가 사용하는 면적 차이를 보면 그 힘을 알 수 있다. 두 그래픽 카드의 물리적 크기는 동일하지만, 사용 가능한 메모리 용량은 A6000이 24~48GB, A100이 40~80GB다. A100이 2배 가까이 더 크다. 대역폭 역시 A600은 약 800GB/s이지만, A100은 1,900GB/s로 2배 가까이 크다. A6000 대신 A100을 사용할 경우, 동일 컴퓨터에 신경망을 2배 집적할 수 있을 뿐만 아니라 개별 신경망 작동 속도까지 2배로 상승하게 되는 것이다.
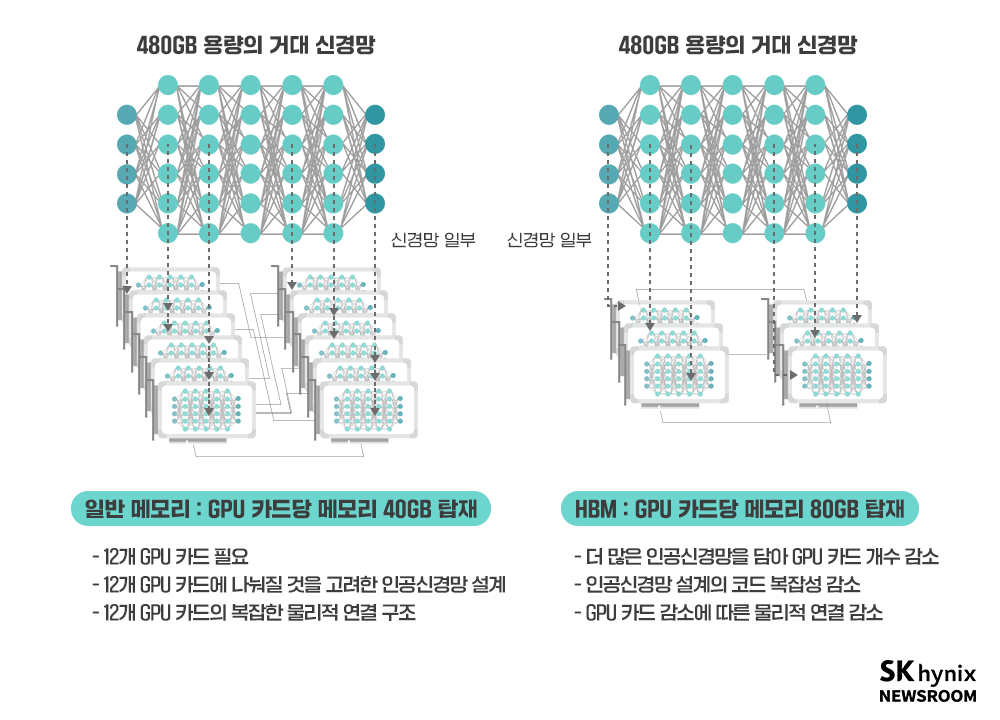
▲ 일반 메모리와 HBM 메모리의 인공신경망 구동 비교, GDDR 메모리 등 일반 메모리는 물리적 공간을 크게 차지하기에 GPU 카드 하나의 메모리 용량을 늘리는 데 한계가 있다. 반면 HBM은 동일 면적에서 더 높은 밀도를 가지기에 GPU 카드당 더 많은 메모리를 부착할 수 있고, 더욱 큰 용량의 인공신경망을 담을 수 있다.
HBM은 복잡한 카드 간 연결을 줄여주는 역할도 한다. 이미 알렉스넷에서 봤듯이, GPU 메모리 용량이 부족하면 신경망을 둘로 쪼개 각기 다른 GPU 카드에 탑재해야 한다. 최근 유행하는 초거대신경망은 A100 카드 한 장에 들어가지 못해 동일 카드를 여러 장 묶어 사용해야만 한다. 이로 인해 인공지능 초반에 알렉스넷이 해야 했던 것 이상으로 번거로운 일을 해주어야 할 것이다. 수백 GB의 신경망을 여러 개의 GPU에 나눠 담는 동시에 추론 속도에 큰 영향을 받지 않게 하는 등 여러 테크닉을 구사해야만 한다.
만약 단일 GPU에 탑재된 메모리가 더욱 크다면 이런 번거로움이 줄어든다. HBM은 동일 GPU 카드 면적에 더 높은 메모리를 제공할 수 있기에 꾸준히 인공지능학자들에게 큰 도움이 될 것이다. NVIDIA의 차기 학습용 GPU인 H100의 경우 80GB 메모리부터 시작한다. A100 역시 40GB에서 출발하여 80GB 카드를 출시했으므로 더 큰 메모리를 가진 H100 제품이 나올 것도 예상할 수 있다.
결론
HBM은 인공지능 시대가 열리면서 가장 주목받은 메모리다. 우리는 HBM이 대두하는 과정을 분명하게 이해해야 할 필요가 있다. 본래 메모리 비즈니스의 덕목은 ‘매해 같은 용량을 더 싸게 파는 비즈니스’가 핵심이었다. CPU 기반의 프로그램은 예측할 수 있는 방식으로 발전해 왔고, 매해 더 큰 용량의 메모리를 제공하면 되는 것이었다. 메모리 회사가 해야 할 일은 더 많은 프로그램을, 혹은 용량이 더 큰 동영상을 동시에 수행할 수 있게 하는 것이었다. CPU의 동작 방식상, 이 모든 데이터를 한 번에 접근하려 하진 않을 것이기 때문이다.
하지만 인공지능 기술이 나타나면서 상황이 바뀐다. 인공신경망 기반의 프로그램, 인공지능은 메모리 공간을 크게 차지할 뿐만 아니라, 주어진 시간 내에 접근해야 하는 메모리의 총량도 압도적으로 컸다. 이로 인해 용량 대비 가격이 비싸더라도, 더 큰 용량과 더 큰 대역폭을 제공하는 메모리를 원하게 된 것이다. 본래 메모리에 수백~수천만 원의 지출을 하는 것은 어마어마한 비용이었지만, 부가가치가 높은 인공지능 입장에서는 HBM 가격은 ‘고작 수백만 원’에 불과하다.
우리는 이런 사실을 잘 이해할 필요가 있다. 프로그램, 나아가 IT 환경의 변화는 비즈니스의 가정 자체를 뒤집어 놓을 수 있다는 것이다. 신기술로 인해 ‘대역폭과 총용량’의 가치가 ‘용량당 가격’의 가치를 넘어섰다. 앞으로 새로운 기술들이 나타날 때마다 이 기술은 과연 메모리에 무엇을 요구하게 될지 고민해 봐야 할 시대다.
※ 본 칼럼은 반도체에 관한 인사이트를 제공하는 외부 전문가 칼럼으로, SK하이닉스의 공식 입장과는 다를 수 있습니다.



