아드 폰테스(Ad Fontes)는 ‘기본으로 돌아가자(Back to Basics)’라는 뜻의 라틴어다. 르네상스 시대 인문주의 학자들이 과거의 찬란했던 그리스 로마 문화로 돌아가자는 의미로 이 표어를 사용했다. 당시 종교 개혁자들도 타락한 기독교를 향해 ‘아드 폰테스’를 외쳤다. 기독교 신앙의 원천인 성경으로 돌아가자는 것이었다.
700여 년이 지난 지금도 우리는 ‘기본으로 돌아가자’는 말을 자주 사용한다. 특히, 위기를 맞았을 때일수록 ‘기본’의 중요성이 강조된다. 무슨 일이든 기초가 중요하다는 것은 당연한 말이고, 이는 기업 경쟁력과 직결되는 ‘데이터 품질 관리’에도 마찬가지다.
데이터에도 법률이 필요하다
디지털 시대의 적합한 미래를 구상하기 위해 현재의 데이터 관리 체계와 품질을 확인하는 순간, 이상한 느낌을 받는 경우가 종종 있다. 업무 현장 전반에 빅데이터(Big Data)를 활용하게 됨에 따라 대규모의 분석 시스템을 운영하고 있지만, 정작 분석 결과에 대한 경영진과 현업 부서의 신뢰도와 만족도가 그리 높지 않다는 것이다.
여기에는 너무나 기본이어서 알고는 있지만, 그 중요성을 깨닫지 못하는 부분이 숨어있다. 그것은 국가의 운영을 위해 법률을 제정하듯, 데이터를 제대로 활용하기 위해서도 그 나름의 구조가 밑바탕이 돼야 한다는 사실이다.
기업 내 데이터의 흐름을 체계적으로 관리하는 프로세스가 없다면 데이터의 신뢰성을 보장할 수 없게 된다. 이것을 바로 잡을 수 있는 데이터의 법률이 바로 ‘데이터 거버넌스(Data Governance, 데이터 통합 관리)’다. 기업에서 가치 있는 양질의 데이터를 지속적으로 발굴 및 관리해 비즈니스 자산으로 활용하기 위한 데이터 통합 관리 체계를 말한다.
기업 내 데이터 관리 정책과 프로세스를 관장하는 데이터 거버넌스, 그 중심에는 MDM(Master Data Management, 기준정보관리)이 자리하고 있다. MDM이란 기업의 핵심 데이터인 기준 정보를 생성하고, 이를 일관성 있게 유지하며 비즈니스 프로세스 흐름에 맞춰 정확하게 관리하기 위한 솔루션이다.
MDM을 구현함으로써 기업은 핵심 정보를 효과적으로 유지 및 관리할 수 있으며, 이를 바탕으로 데이터 품질을 강화해 정보의 신뢰성을 확보할 수 있다. 데이터 분석의 가치가 재조명받는 ‘빅데이터’ 시대, 데이터의 품질 관리는 기업의 필수 불가결한 요소가 됐다.
마스터 데이터가 흔들리면, 기업이 흔들린다?
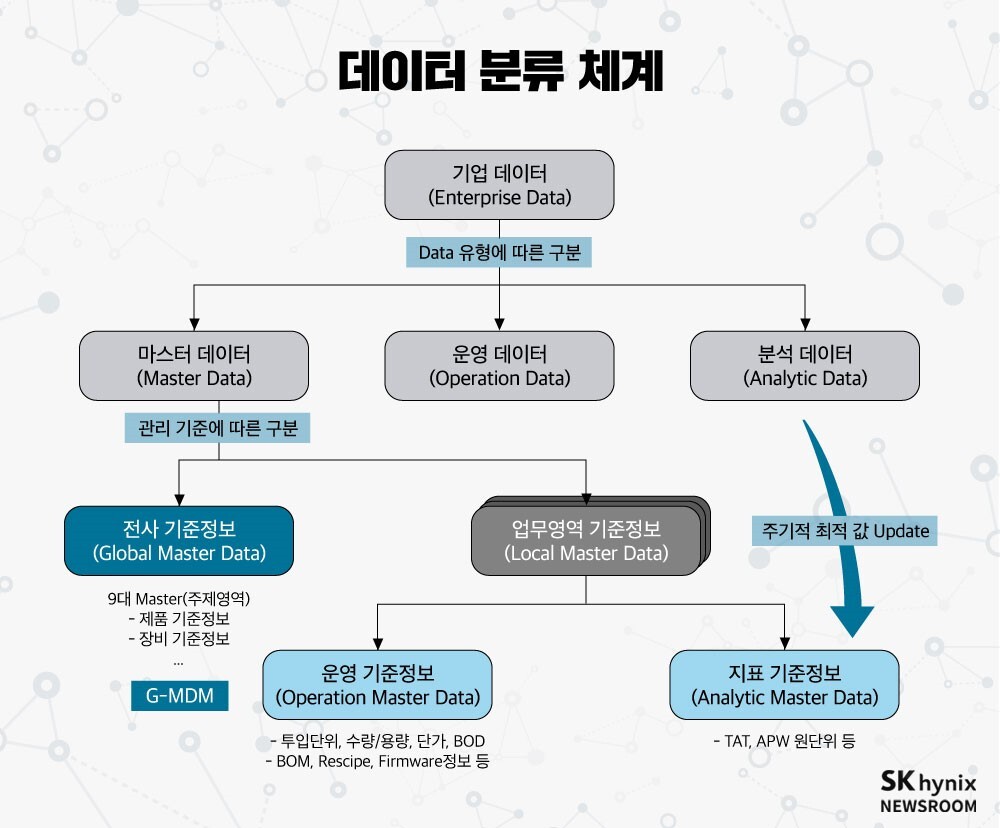
기업 데이터는 일반적으로 마스터 데이터(Master Data), 운영 데이터(Operation Data)1)분석 데이터(Analytic Data)2)로 나뉜다. 이 가운데 마스터 데이터는 전사 업무 부문 간 공통의 의미를 가져야 할 정보로, 기업 경영 활동의 근간이 되는 핵심 항목들로 이뤄진 ‘기준 정보’를 의미한다. SK하이닉스의 경우 제품 코드, 자재 코드 등이 여기에 해당하며, 각각의 코드가 가지고 있는 속성 정보도 이에 포함된다.
1) 기업이 사업활동을 수행함에 따라 생성되고 수집되는 데이터.
2) 기업의 성과를 나타내기 위해 발굴하고 활용하는 데이터.
지금 이 순간에도 우리 주변에는 막대한 양의 데이터가 생성되고, 축적되고, 사용되고 있다. 그런데, 이런 데이터의 기준점이 흔들린다면 과연 우리는 정확한 결과를 얻을 수 있을까?
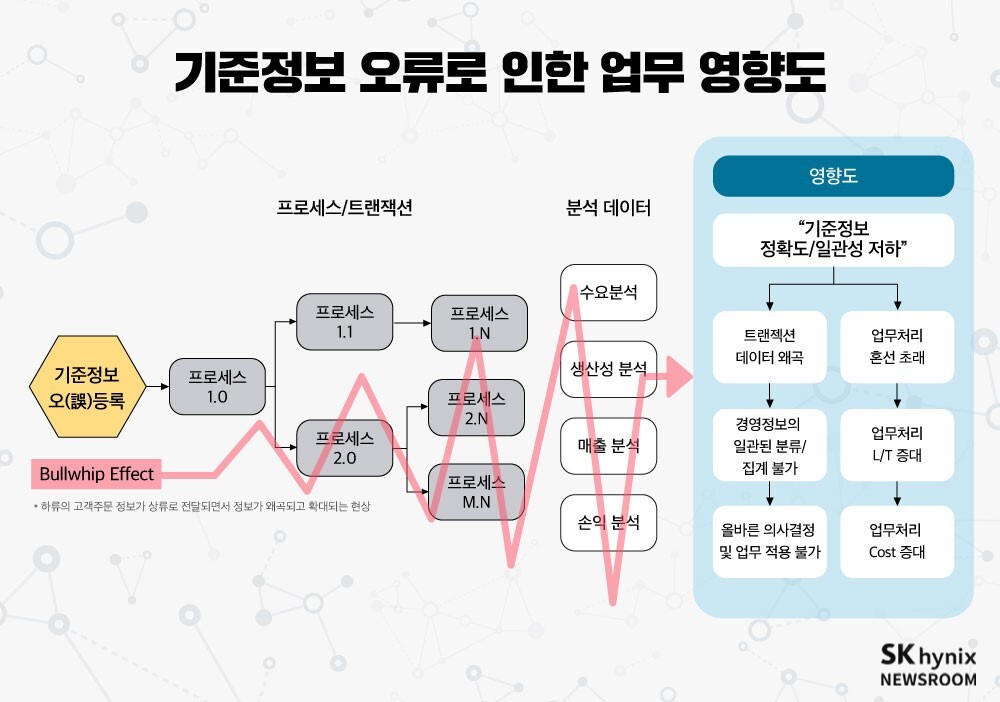
특히 마스터 데이터가 중복이나 누락 등의 이유로 부정확해질 경우, 마스터 데이터를 참조해 생성되는 운영 데이터뿐 아니라 이를 가공해 생성되는 분석 데이터까지 신뢰성과 품질에 치명적인 오류가 발생할 수 있다. 이는 나아가 기업의 의사결정에도 심각한 문제를 초래할 수 있는 것이다.
데이터 관리 체계에서는 어떠한 문제가 발생하는가?
● 데이터 중복 문제
전사적으로 동일한 데이터에 대한 통합 관리 기준이 없어 중복 문제 발생하는 경우를 보면, 일반적으로 비즈니스 영역별로 독자적인 데이터를 생성하고 있다는 것을 알 수 있다. 동일 데이터를 여러 시스템을 통해 취득해 활용할 수 있지만, 가장 정확하고 우선적이고, 지속적으로 관리하기 위해서는 핵심(Core) 시스템을 정의해 데이터를 관리해야 한다. 이를 기반으로 연관 시스템은 중복해서 데이터를 획득하지 않고, 핵심 시스템의 데이터를 활용하는 것이 필요하다.
● 데이터 분류체계 문제
표준 분류체계를 구성하기 위한 전사 분류기준 및 원칙 등이 부재해, MECE(Mutually Exclusive Collectively Exhaustive, 상호 배제와 전체 포괄 원칙)3)를 충족하지 않는 경우가 발생하고 있다. 전사 관점으로 보면 다양한 분류기준으로 인해 담당자 간 의사소통에 차질을 겪고 있으며, 경영진 의사결정 지원을 위한 정확한 데이터 제공에 어려움이 발생하고 있다.
3) 서로 중복되지 않도록 배타적이면서, 전체를 모아놓았을 때는 누락되지 않는 것.
● 데이터 일관성 문제
여러 시스템(업무 시스템, 분석 시스템 등)에서 데이터를 처리할 때, 동일한 데이터를 사용함으로써 데이터의 일관성이 유지돼야 정확하고 신뢰성 있는 정보를 생산할 수 있다. 그러나, 영역별로 독자적인 데이터 생성 등의 이슈로 식별 기준 및 원칙이 흐트러진 상태로 관리되는 부분이 다수 존재한다.
● 데이터 생애주기(Life Cycle) 문제
데이터의 생성부터 변경, 폐기에 이르는 프로세스에 대한 정의와 데이터 오너십(Data Ownership)4)을 가진 조직의 데이터 승인 절차 등 데이터 생애주기 전반에 대한 관리 역할이 체계적이지 않다. 데이터 생성 시점부터 업무별 오너 부서의 데이터 검증 등 통제가 제대로 되지 않아 데이터 중복 및 일관성 문제가 지속적으로 발생하고 있다. 또한, 데이터 폐기 기준이 없거나 지연됨으로써 불필요한 데이터가 집계 및 평가에 사용되어 정확성 문제가 발생하는 경우도 있다.
4) <데이터 자체에 법적 권리나 지위를 부여하는 것으로, 데이터에 대한 가공처리와 관련한 법적 지위를 인정하기 위해 도입된 개념.
빅데이터 시대, 다시 ‘데이터 거버넌스’와 ‘마스터 데이터’다
빅데이터 시대에는 새로운 데이터가 빠른 속도로 쌓이고 있다. 데이터 품질을 관리하기 위해 데이터 클렌징(Data Cleansing)5)과 같은 사후적 품질 관리가 이뤄지고 있으나, 이는 이슈가 발생 시 이벤트성으로 진행되는 데 그치고 있다. 디지털 시대에 적합한 고품질의 데이터를 확보하고 활용하는 데에는 충분치 못하다.
5) 데이터베이스의 불완전 데이터에 대한 검출·이동·정정 등의 작업.
그렇다고 모든 데이터의 품질 확보를 위해 전사 임직원이 많은 시간을 할애하기란 현실적으로 어렵다. 하지만, 반드시 해결해야 할 문제이며, 방법이 없는 것도 아니다.
가트너(Gartner, 기술시장 분석 전문기관)는 MDM에 대해 “마스터 데이터를 분산 환경으로부터 통합해 정제하고 보완한 뒤, 이를 하나의 기준(Single View Of Truth)으로 각 시스템에 배포해 활용할 수 있도록 돕는 관리 도구”라고 정의한 바 있다.
이는 마스터 데이터의 품질과 일관성을 유지하고 업무 변화에 대응할 수 있도록 표준과 거버넌스를 확립, 사전 데이터 품질을 관리할 수 있는 체계와 인프라를 구축하는 것이다. 전사 데이터의 시작 점인 마스터 데이터부터 데이터 거버넌스에 입각해 관리돼야, 이와 연계된 모든 데이터의 품질을 관리할 수 있다.
현재 전사적인 데이터 표준화뿐만 아니라, 고유의 업무 관련 데이터에 대한 교통정리가 요구되고 있다. 위에 언급한 데이터 거버넌스를 기초로 데이터의 흐름을 얼마나 활용할 수 있느냐에 따라 빅데이터의 활용도 또한 확대될 것이다.
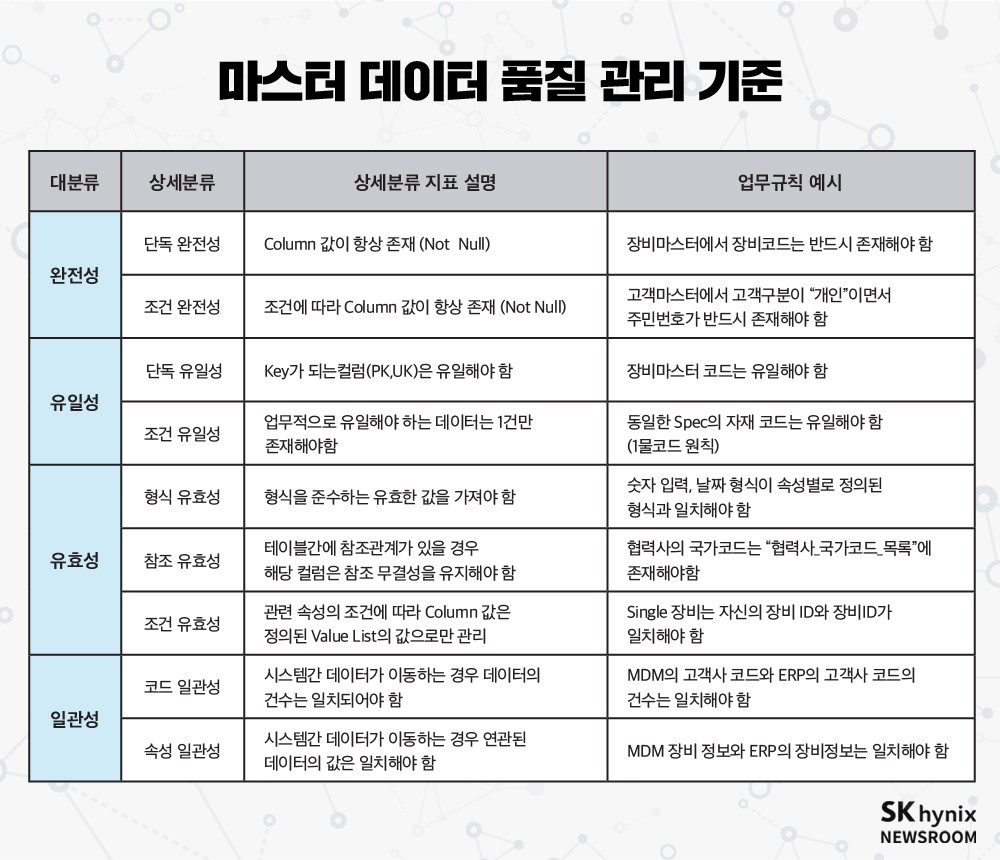
이를 제대로 활용하려면 데이터 거버넌스에 의해 정의된 기준점인, 마스터 데이터에 대한 지속적인 품질 관리(완전성, 유일성, 유효성, 일관성 등)를 통해 신뢰성 있는 데이터를 유지 및 관리하는 것이다.
데이터의 진정한 가치를 찾기 위해
빅데이터 시대를 맞이하며 MDM의 활용 범위는 점점 넓어지고 있다. 미국의 한 금융기업은 신규 가입 고객을 대상으로 조사해본 결과 SNS에서 누군가에게 영향을 받아 가입한 고객이 가장 많다는 것을 알게 됐고, 소셜 데이터를 MDM 고객정보와 연동해 고객에게 영향을 준 인플루언서(Influencer)는 누구인지, 어떻게 영향을 끼치고 있는지 등을 알아내 마케팅에 활용했던 사례가 있다.
또한, 빅데이터들 가운데 쓸모없는 다크데이터(Dark Data)6)를 줄이는 용도로도 활용이 가능하고, 비즈니스 영향을 분석하는 데 있어 기준점의 역할을 한다.
6) 정보를 수집한 후, 저장만 하고 분석에 활용하고 있지 않는 다량의 데이터.
데이터 품질 저하를 야기하는 구조적 문제를 해결하고, 진정한 데이터의 가치를 찾기 위해서는 결국 전사적인 데이터 거버넌스를 바로 세우고 데이터의 체계를 확고히 해야 한다. 이를 통해 빅데이터, 머신러닝, 인공지능 등 새로운 트렌드에 휩쓸리지 않고, 기업이 보유한 기존 체계와 데이터로 어떻게 시너지를 낼 것인지 전체적인 관점에서 바라보는 것이 중요하다.



