이번 연재는 컴퓨터와 반도체의 관점에서 인공지능을 살펴볼 것이다. 기존의 프로그램이 인공지능으로 바뀌면서 0과 1의 세계가 구체적으로 어떻게 변화하는 것인지 알아보고, 이를 실행하는 데 필수적인 반도체는 어떤 중요한 역할을 해야 하는지 확인해볼 것이다. 이를 통해 반도체는 인공지능을 포함한 새로운 ICT 기술의 등장에도 두려워하기보다는 세상을 변화시킬 혁명의 주인공이 될 것이다. (필자 주)
전통적 프로그램이 동작하는 방식
우리는 이미 20년 전에도 컴퓨터 없는 세상을 상상할 수 없었다. 21세기 초, 인터넷 뱅킹이 생겨나기 시작했고, 각종 인터넷 쇼핑몰이 생겨났다. 수많은 회사가 엑셀과 같은 스프레드시트 프로그램을 사용해 회계 작업의 효율성을 높였고, 워드프로세서 프로그램들을 통해 수기 작업을 대체했다. 이후에는 개별 컴퓨터에 보관되던 작업물이 중앙 서버에 집중되기 시작했고, 각 직원은 자신의 물리적 위치에 구애받지 않고 일할 수 있게 됐다. 그렇다면 의문이 하나 생길 것이다. 대체 프로그램이란 무엇인가?
간단한 예를 들어 보자. 한 직원이 문서 내의 모든 행에 있는 숫자를 합하는 프로그램을 만들고 싶어 한다고 가정해보겠다. 그리고 현재 문서가 다섯 줄이라면 어떻게 해야 할까? 제일 첫 단계는 일단 ‘사람이라면 어떻게 하는지’ 고민하는 것이다. 아마도 마음속에 제일 먼저 떠오르는 것은 무언가를 ‘다섯 번 반복’하면 된다는 사실일 것이다.
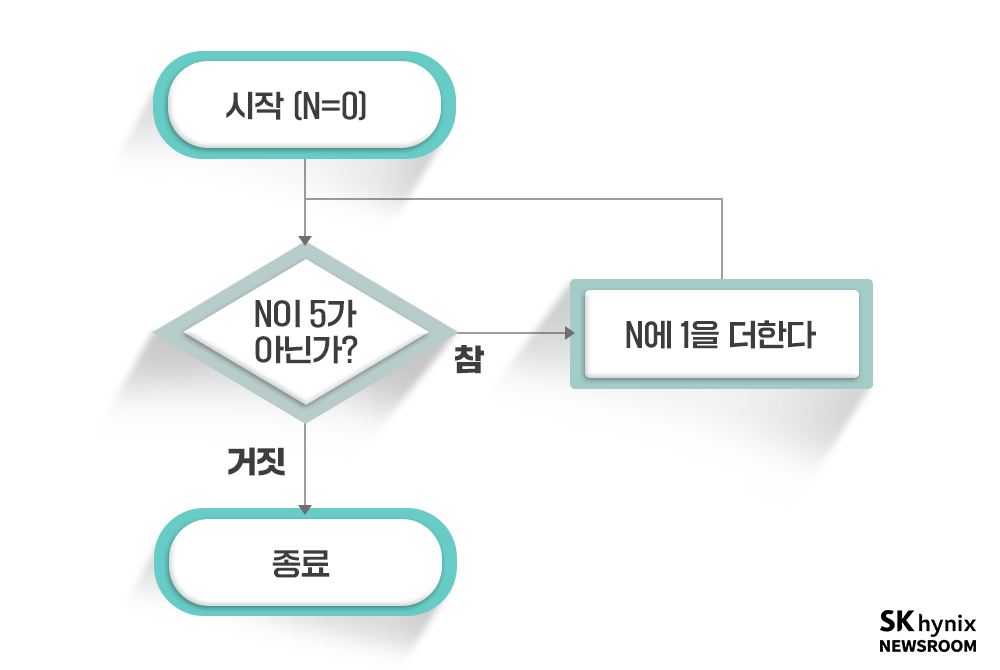
▲ 그림 1 : 무언가를 다섯 번 반복하기 위한 코드의 흐름
하지만 이렇게 다섯 번 반복해서는 의미가 없다. 수를 모두 합해야 하기 때문이다. 반복할 때마다 사라지지 않고 누적되는 어떤 값을 만들어야 한다. 따라서 프로그램을 다음과 같이 개조할 수 있다.
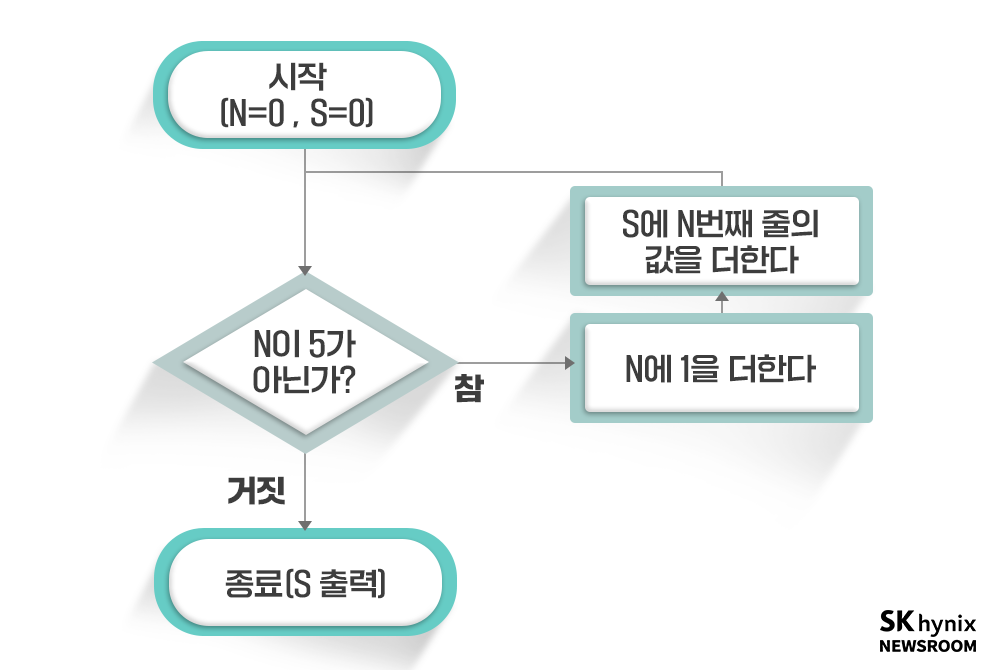
▲ 그림 2 : 다섯 줄의 숫자를 합하는 프로그램의 흐름
해냈다! 드디어 프로그램의 구조를 만들었다. 이제 이 순서도에 맞춰서 프로그래밍 언어로 코드를 만들면 된다. 파이썬(Python)*이라는 프로그래밍 언어로 만든다면 아래와 같은 모습이 될 것이다. 프로그래밍 언어를 모르는 사람이라도, 아래 코드를 읽는 것에는 큰 어려움이 없을 것이다.
* 파이썬(Python) : 귀도 반 로썸(Guido van Rossum)이 개발한 프로그래밍 언어. 초보자도 사용하기 편하다는 특징이 있다.
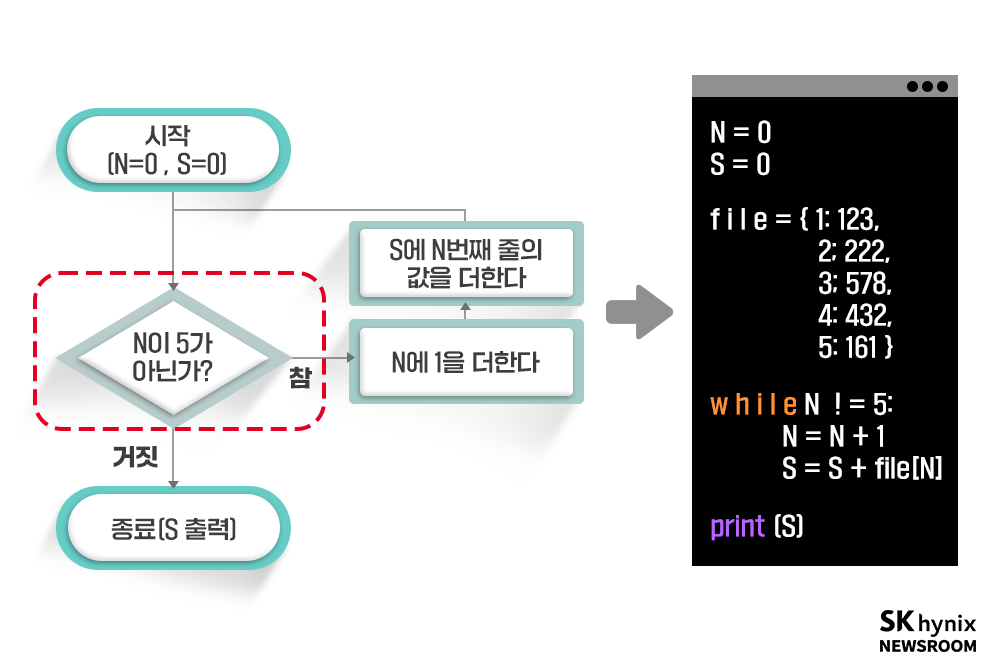
▲ 그림 3 : 완성된 다섯 줄의 숫자를 합하는 파이썬 프로그램 코드
만약 지금 만든 프로그램을 다섯 줄의 한계 없이, 어떤 데이터가 입력되더라도 파일의 끝까지 더하는 프로그램으로 개선하고 싶다면 어떻게 해야 할까? 아마도 ‘다섯 번 반복’을 무언가 다른 것으로 바꿔야 한다는 짐작이 가능할 것이다. 다행히도 이미 ‘누군가’가 파일을 읽을 때 EOF(End of File)을 알려주는 기능을 추가했다. 이 기능을 활용하면 된다. 위 그림에서 빨간 네모 친 부분을 바꾸면 된다는 의미다.
이렇게 우리는 전통적 프로그램을 완성하고, 개선까지 해냈다. 우리는 이 과정에서 여러 가지 사실을 알 수 있다. 가장 중요한 것은 순서도를 만드는 것이다. 시키고 싶은 작업이 있다면, 프로그래밍 언어는 달라도 순서도의 모습 자체는 동일하다는 것을 명심해야 한다. 다시 말하면, 순서도를 떠올리지 못하면 프로그램을 만들 수 없다는 의미다.
또, 한 가지 사실은 프로그램을 만드는 과정에서 ‘누군가’ 다른 사람이 만든 코드에 크게 의존하게 된다는 것이다. 사실 위에서 구체적으로 언급하지는 않았지만, EOF 확인 이외에도 ‘파일을 읽는 것’, ‘모니터에 출력하는 것’ 등 역시 다른 누군가가 만든 함수다. 이런 기능들은 운영체제(OS, Operating System)가 제공하기도 하며, 누군가 다른 사람이 특정 프로그래밍 언어로 만들어 두기도 한다. 프로그래머들은 프로그래밍을 시작하기 전 이런 다양한 요소들을 고려한다. 예를 들어, 만약 내가 만들고 싶은 프로그램을 개발하기 위해선 데이터를 매우 특별한 방식으로 바꿔야 하는데, 그 기능이 자바(Java)*에 이미 존재한다면 자바로 코드를 만드는 것이 효율적이다.
우리가 매일 사용하는 워드프로세서, 스프레드시트, 웹 브라우저 등 대부분의 프로그램이 위와 같은 작업을 통해 만들어진 것이다. 그렇다면 인공지능 시대에는 무엇이 바뀌는 것일까?
* 자바(Java) : 오라클(Oracle)사가 개발한 프로그래밍 언어의 일종
신경망과 인공지능
위에서 우리가 살펴본 프로그래밍 방법은 완벽한 것 같지만 사실은 그렇지 않다. 여기에는 두 가지 문제가 있다. 하나는 프로그램이 스스로 배우지 못한다는 것이다. 우리는 프로그램을 고치기 위해 순서도를 고쳐야 했다. ‘다섯 번 루프’를 ‘EOF로 대체하지 않는 이상, 프로그램은 영원히 파일의 첫 다섯 줄만을 가져와 처리했을 것이다.
더 큰 문제는 따로 있다. 바로 인간이 순서도를 만들지 못하는 프로그램은 만들 수 없다는 것이다. 프로그래밍의 첫 단계를 해내지 못하니 다음 단계로 가지 못하는 것이다.
사진이 입력되면 동물의 종류(개와 고양이)를 구분하는 프로그램을 만들어야 한다고 해 보자. 여러분은 개와 고양이를 어떻게 구분하는가? 아마 바로 떠오르는 것은 주둥이의 모습일 것이다. 그래서 아래와 같은 순서도를 만들었다고 해 보자.
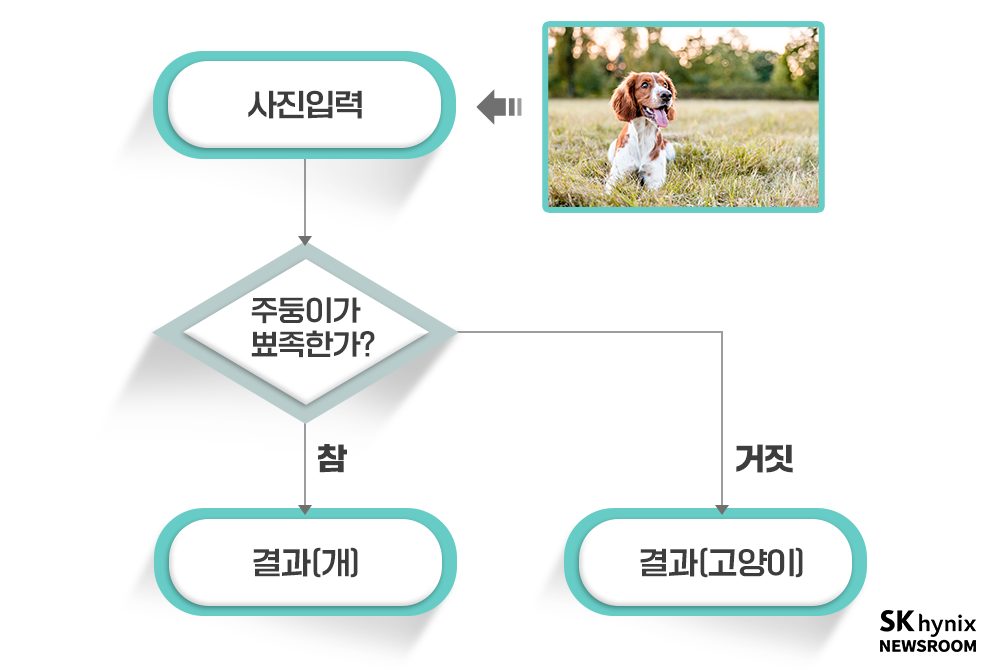
▲ 그림 4 : 개와 고양이를 구분하는 간단한 프로그램의 흐름
그런데 문제가 생긴다. 누군가 동물 주둥이가 가려진 사진을 두 개 가지고 온 것이다. 이제 프로그램이 작동하지 않는다. 프로그래머는 놀라 허겁지겁 새로운 알고리즘을 만들기로 한다. 눈동자의 모양을 확인하는 코드를 추가하면 개와 고양이의 구분이 가능할 것이다. 하지만 새로운 개, 고양이 사진을 가지고 올 때마다 이런 일이 계속 생겨날 것이다. 위와 같은 순서도 기반의 프로그램으로는 도저히 개와 고양이를 구분하는 안정적인 프로그램을 만들 수 없을 것이다. 현실에서는 개와 고양이를 구분하는 눈, 코 등의 요소들을 찾아내는 것도 힘든데, ‘주둥이, 눈동자 모양’만 골라내는 코드를 만드는 것 역시 매우 힘들다. 특정 사진에서는 쉽게 찾아낼 수도 있지만, 수백만 개의 다양한 사진에서 특정 요소를 골라내기는 매우 어려운 일이다.
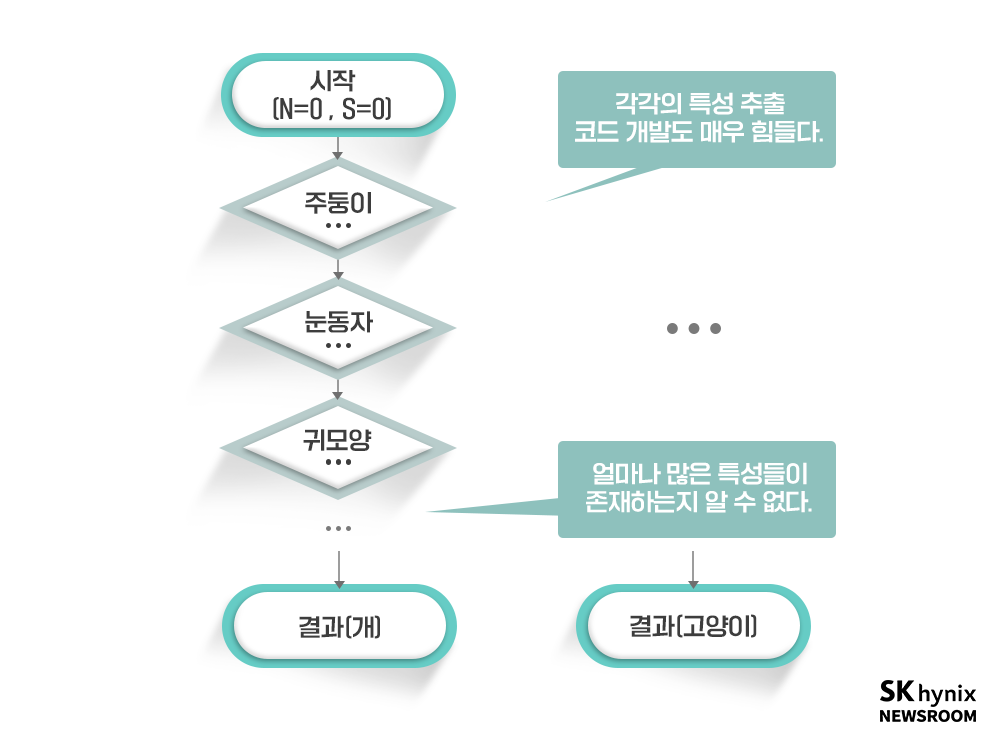
▲ 그림 5 : 개와 고양이 구분하는 프로그램을 구성하기란 매우 어렵다.
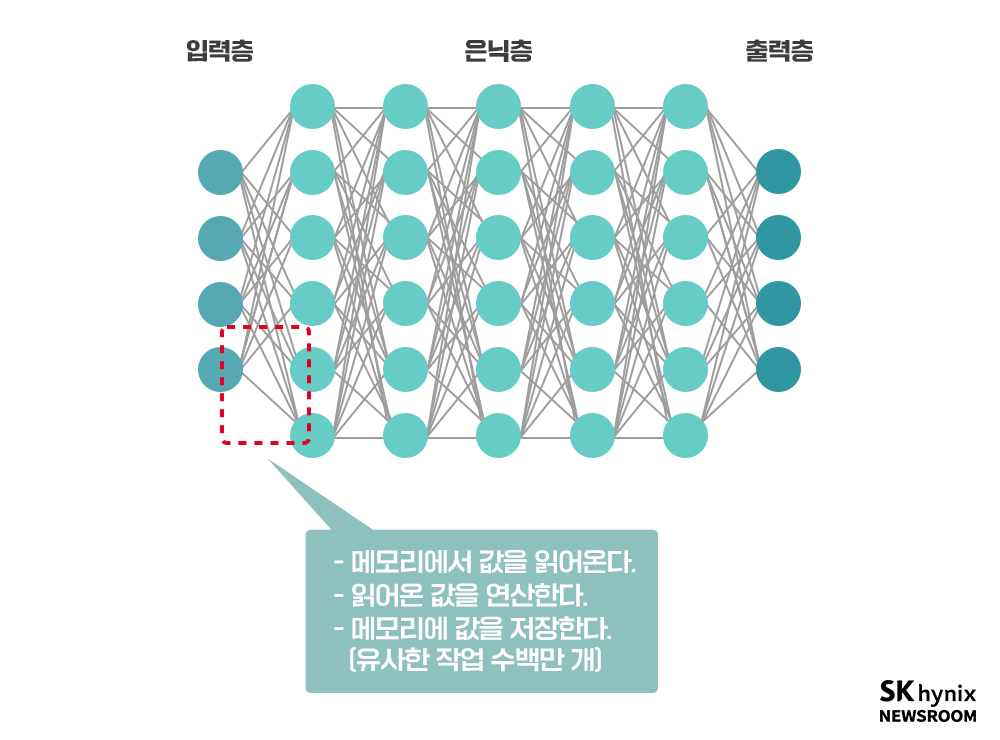
하지만 인간은 사진을 보면 ‘척 보면 딱’ 개와 고양이를 구분해낸다. 스스로 어떻게 구분했는지는 잘 모르지만, 할 수 있다. 그렇다면, 인간과 비슷한 구조의 프로그램을 만든다면 어떻게 동작하는지는 몰라도, 개와 고양이를 잘 구분할 수 있게 될 것이라는 가정이 가능하다. 따라서 아래의 구조와 같은 프로그램을 만들어 보게 된다. 이제 프로그램에는 순서도가 없고, 수 없이 연결된 인공적인 신경세포가 가득하다. 이를 ‘인공신경망’이라 부른다.
인공신경망의 입력 부분에 사진을 투입하면, 출력 부분에서는 개인지 고양이인지가 출력되는 것이다. 이제 프로그래머가 해야 하는 일은 저 수많은(수백만~수백억 개) 신경세포들 사이의 연결 강도를 지정해 주는 것이다. 하지만 순서도가 없으니 각 세포가 뭘 하는 것인지 하는지 알 수가 없다. 개와 고양이를 구분하기위해 첫 번째, 두 번째… 백만 번째 인공 뇌세포는 무엇을 해야 하는 건지 어떻게 알 수 있겠는가? 이 문제로 인해 인공신경망이라는 개념은 1960년대에 처음 등장했음에도 50년 가까운 세월 동안 빛을 보지 못했다. 우리가 학습이라고 부르는 것은 일종의 프로그래밍 방법이다.
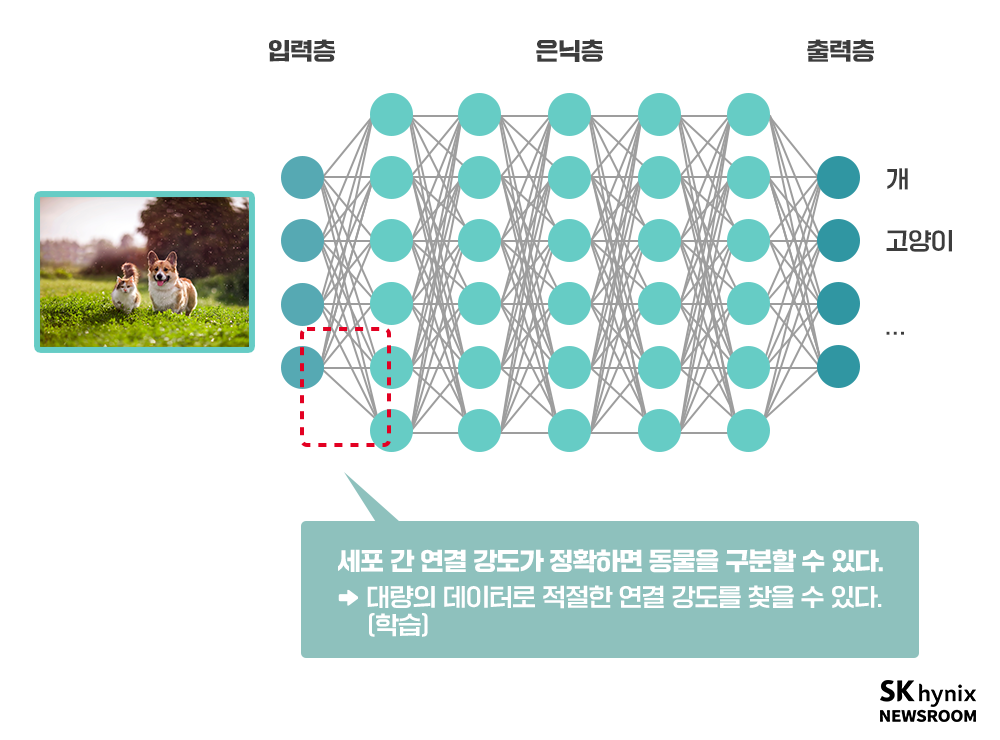
▲ 그림 6 : 인공신경망이 동작하는 방식
* 입력층 : 입력을 받아들이는 층
* 은닉층 : 입력층으로부터 입력값을 받아 가중치를 계산하는 부분으로 가중치의 수정으로 인한 학습이 진행되는 층
* 출력층 : 결과를 출력하는 층
오랜 연구 끝에, 과학자들은 역전파(Backpropagation)*, 초깃값 세팅 등 다양한 방법을 개발했다. 위 방법들과 함께 대량의 학습 데이터를 투입할 경우, 우리들이 개별 세포들의 역할을 모르더라도 잘 동작하는 프로그램, 즉 인공지능을 만들 수 있게 된 것이다. 이렇게 해서 새로운 세상이 열리게 됐다. 새로운 이론들을 통해 신경망을 학습시키자, 신경망 내 다양한 은닉층은 각자의 역할을 가질 수 있게 됐다.
* 역전파(Backpropagation) : 맨 마지막 층의 값부터 비교하는 방법으로 학습하면서 차례차례 역으로 원하는 곳까지의 결과값을 얻어내는 과정
이 대목에서 우리는 반도체 엔지니어들이 인공지능 기술을 어떻게 접근해야 하는지 알 수 있다. 예를 들면, 우리가 인공지능의 ‘학습’이라고 부르는 것은 결국 수백만 개가 넘는 인공 뉴런 사이의 연결 세기를 ‘제대로’ 지정해 주는 일이었을 뿐이다. 반도체 엔지니어가 인공지능에 접근하는 방법에 대해 다음 예를 통해 설명해보겠다.
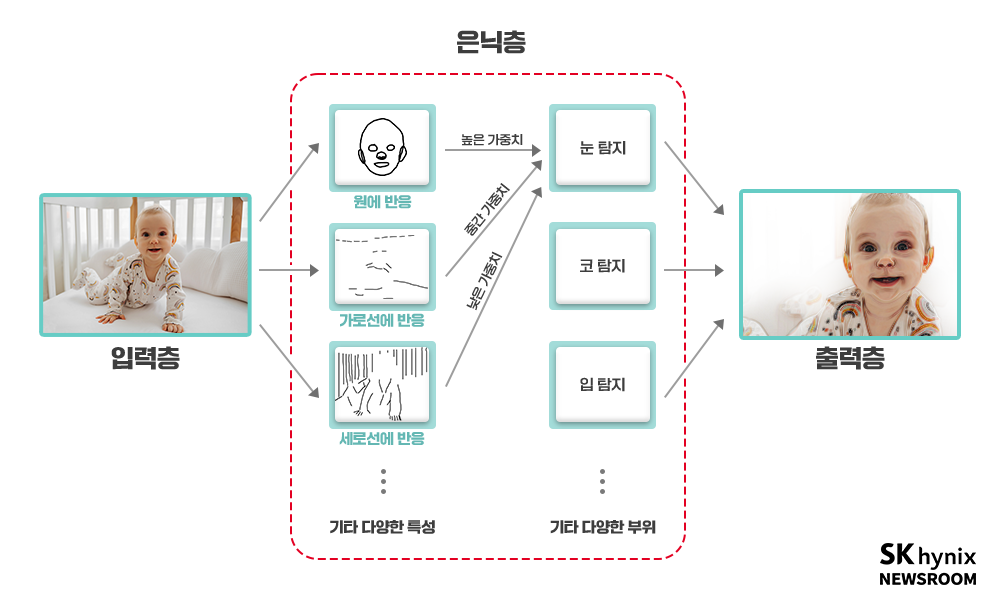
▲ 그림 7 : 인간의 얼굴을 찾아내는 가상의 인공신경망 예
<그림7>의 예는 사람의 얼굴만을 골라내 출력하는 가상의 인공신경망이다. 우리가 이 신경망을 구성한 뒤 학습시키게 되면, 각 층은 대략 위와 같은 역할을 가지게 된다. 일단 입력층에 가까운 은닉층이 원, 가로선, 세로선, 대각선 등 특정 도형들에 활성화가 되게 학습된다. 그다음 은닉층은 인간의 얼굴을 찾기 위해, 눈 코 입 등을 찾으려 한다. 이때 사진 원본 대신 그 전 단계 은닉층이 제공해준 정보를 사용하는 것이다.
눈을 탐지하는 은닉층은 눈이라는 신체 부위의 특징상, 원에는 크게 반응해야 하지만, 세로선에는 거의 반응하지 않아야 할 것이다. 만약 입을 찾아야 한다면, 가로선이 가장 중요하고 세로선은 별로 중요하지 않을 것이다. 과학자들이 발견한 학습 방법론의 의의는 사람이 일일이 눈, 코, 입 등을 얼굴 구분에 중요한 요소를 지정해주지 않아도 데이터만 투입해 주면 자동으로 내부의 신경망이 층을 나눠 위와 같은 역할을 가지게 만들 수 있다는 것이었다.
당연하지만 인공신경망을 키우고 은닉층이 깊어질수록 더욱 세밀한 분석을 할 수 있게 된다. 더 많은 은닉층이 있다면, 대각선에 반응하는 선이 학습 과정에서 생겨날 수 있고, 눈과 코 출력 결과를 또 모아서 눈과 코 사이의 거리를 확인하는 세 번째 은닉층이 생길 수도 있다. 이 과정에서 점점 인간 얼굴을 구성하는 더 많은 요소를 고려할 수 있게 되며, 정확도가 높아지게 되는 것이다.
‘현재 인공지능의 학습이란 것은 수많은 소수점을 변경하고 저장하는 것을 반복하는 것이다.’
이것이 여러분이 반도체를 알기 위해서 프로그램을 이해해야 하는 이유다. 위와 같은 이해를 해야만 이후 중요한 변화가 생겼을 때 대응할 수 있다. 만약 인공지능 기술의 트렌드가 바뀌어, 신경망의 크기가 매우 작아지면? 역전파를 대체할 학습 방법론이 생겨나면? 이런 세세한 트렌드 변화는 프로그램들이 원하는 반도체의 특성을 바꾼다. 만약 ‘인공지능은 큰 메모리가 필요하다’라고 암기식으로 접근한다면, 이때 잘못된 결론을 내리게 될 것이다.
프로그램을 위해 진화해 온 CPU
반도체 입장에서의 프로그램을 조금 더 자세하게 살펴보자. 앞서 우리는 순서도 기반으로 만들어진 프로그램을 살펴봤다. 이런 프로그램들은 그 자체로는 의미가 없으며, CPU(Central Processing Unit, 중앙처리장치)가 있어야만 의미를 가진다. 프로그래머는 앞서 만든 순서도를 컴퓨터가 이해하는 기계어로 변환한 뒤, 메모리에 저장한 다음 CPU에 프로그램을 실행해 달라고 요청하는 것이다.
위 예에서 알 수 있지만, 프로그램을 수행하기 위해서는 크게 세 가지의 연산 종류가 필요함을 알 수 있다. 하나는 덧셈, 뺄셈 등의 사칙연산, 메모리 입출력, 비교와 분기다. 분기라는 것은 조건에 맞춰 선택지를 택하는 것을 의미한다. 인간 입장에서 ‘1부터 5까지 더한다’라는 작업은 컴퓨터 입장에선 아래와 같이 보이게 된다. 일반적으로 CPU 내부에 레지스터라는 고속 저장소가 있으므로, 변수 2개(N, S) 정도는 메모리 접근 없이 처리할 수 있지만 설명을 간단히 하기 위해 이런 부분은 과감히 생략하겠다.
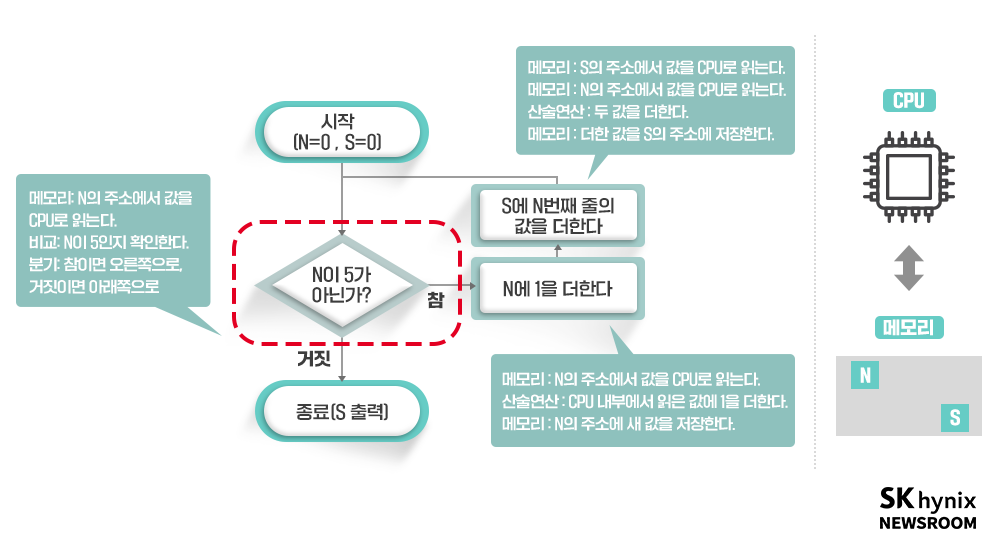
▲ 그림 8 : 연산 칩 입장에서 1에서 5까지 더하는 프로그램의 흐름과 CPU와 메모리의 역할
위 작업을 분석해 보면 메모리 접근과 산술 연산이 매우 빈번하지만, 분기 역시 자주 발생함을 알 수 있다. 이와 마찬가지로 현대 컴퓨터 프로그램의 상당 부분은 분기 처리로 이뤄져 있다. “ESC 버튼을 입력하면 → 현재 프로그램을 종료하라”와 같은 간단한 명령조차 분기다. “출금 버튼을 누르고 대상 계좌가 입력되면, 돈을 송금하라”와 같은 명령도 분기가 필요하다.
그렇다면 CPU가 계속 활용되기 위해서는 어떻게 해야 할까? 위 순서도에 따르면 세 가지 성능이 개선되면 된다. 산술 연산 속도, 분기 처리 속도, 메모리 접근 속도가 높아지면 된다. 위 예에서는 연산을 한 바퀴 돌 때 메모리 접근 6회, 산술 연산 2회, 비교 및 분기 1회가 포함돼 있다. 여기서 만약 메모리 접근과 산술 연산이 회당 1의 시간이 필요하고, 비교 및 분기에 10의 시간이 필요하다고 가정하면, 현재 작업 한 바퀴 수행에 걸리는 시간은 18(6*1+2*1+1*10)이다. 그런데 CPU가 비교 및 분기에 시간이 5로 개선된다면, 이 시간은 13으로 줄어 30% 가까이 빨라질 것이다.
CPU는 다양한 연산 종류와 분기 등이 섞여 있는 프로그램을 처리해야 했기 때문에 이 3가지 능력을 골고루 발전시키는 방향으로 발전했다. CPU 회사들은 미세화의 힘으로 얻어낸 새로운 트랜지스터들을 이런 능력을 향상하기 위해 아낌없이 투자했다. 기존 프로그램이 CPU만 바꾸면 빨라지게 되니, 새로운 수요는 계속 창출될 수 있었다. 지난 수십 년간 인텔의 CPU가 세계를 지배한 이유가 이것이다.
GPU의 등장과 인공지능
하지만 인공지능 기술이 크게 발전하면서 완전히 다른 형태의 프로그래밍이 생겨났다. 인공지능, 정확하게는 인공신경망 기반의 프로그램은 아래와 같은 구조로 움직인다. 과연 프로그램과 반도체의 입장에서 인공지능은 어떤 모습으로 보일까?
▲ 그림 9 : 연산 칩 입장에서 인공신경망의 구성
이 안에는 분기라는 것이 없다. 대신 산술 연산과 메모리 접근이 압도적으로 많다. 위에서 살펴본 CPU 기반 프로그램의 경우, 고작 몇 번의 연산과 분기만 처리하면 결괏값이 출력됐다. 하지만 인공신경망은 수백~수억 번의 연산을 거쳐야 결괏값을 출력할 수 있다. 실제로 인공신경망은 CPU 기반의 일반적 프로그램보다 코드의 크기가 매우 크다. 이런 인공신경망을 빠르고 효율적으로 동작시키기 위해서는 당연히 수천 개의 숫자 연산을 동시에 수행할 수 있으면서, 큰 메모리에 빠르게 접근할 수 있는 능력이 중요시된다. 따라서 위와 같은 프로그램은 CPU에서는 효율이 매우 낮다.
이는 인공지능 과학자들에게 큰 문제였다. 1970년대 인공지능 시도가 좌절된 원인 중 하나이기도 했다. 만약 위 문제가 해결되지 않으면, 이론적 돌파가 생겨도 무용지물이 될 것이다. 이 문제는 반도체 기술의 발전이 해결했다. GPU(Graphics Processing Unit, 그래픽처리장치)가 등장한 것이다.
GPU는 본래 컴퓨터의 그래픽 처리를 전담하기 위해 설계된 반도체 칩이다. GPU는 우리가 보는 화면에 그림을 빠르게 그려주는 일을 한다. 그래픽 작업의 경우, 분기가 필요치 않고 픽셀과 픽셀의 선후관계 없이 위치마다 각각의 색상 값을 계산해서 그려주면 된다. 이처럼 분기 없이 동시에 여러 작업이 가능한 GPU는 그래픽을 구현하는 작업에서 CPU보다 압도적인 효율을 보이며, 빠르게 발전했다. 이 과정에서 우리가 아는 NVIDIA가 떠오르게 된다.
NVIDIA는 그래픽 시장을 장악한 뒤에도 지속해서 GPU의 새로운 용도를 찾아다녔다. 이런 과정의 일환으로 2007년, CUDA 등 GPU 기반 프로그램 개발을 도와주는 도구를 만들어왔다. 그리고 인공지능 기술의 이론적 돌파가 진척되자, 과학자들은 더 빠르게 인공지능 개발을 도와줄 수 있는 칩을 찾아 나섰다. 그들은 GPU를 적극적으로 채용했고, GPU를 사용할 경우 5배 이상의 성능 향상을 이룰 수 있음을 확인했다. 인공지능을 구현하기에 CPU는 분기 예측 등 필요치 않은 곳에 트랜지스터를 낭비하는 비효율적인 칩이었다. 이렇게 이론적 돌파와 새로운 반도체가 만나 세상을 바꿀 인공지능(AI) 혁명*이 시작된다.
그리고 이 국면에서 빼놓을 수 없는 반도체가 또 있다. 바로 메모리다. 인공신경망의 크기는 기존 CPU 기반 프로그램보다 매우 거대하다. 인공신경망은 어딘가 저장돼 있어야 하므로, 인공지능에 사용되는 GPU는 큰 메모리가 필요하다. 이 때문에 인공지능 시대에 메모리 반도체 기업들 역시 주목받는 것이다.
* 출처 : Large-scale Deep Unsupervised Learning using Graphics Processors, Stanford Univ, 2009
프로그래밍 방법론에서 반도체까지
이번 편에서는 새로운 프로그래밍 방법론이 반도체 입장에서 어떻게 보이는지를 개략적으로 알아봤다. 프로그램은 인간이 생산적인 일을 하기 위한 수단이다. 프로그램은 순서도를 이용한 전통적인 방법으로도 만들 수 있고, 인공신경망 학습 방식으로 만들 수 있다. 그리고 사용자들은 순서도를 이용해 만든 프로그램과 인공신경망 중, 자신이 원하는 프로그램을 잘 돌리는 반도체를 택하는 것뿐이다. 만약 사용자가 엑셀과 같은 기존의 프로그램을 돌리고 싶다면 고성능 CPU를 이용할 것이고, 인공지능 기반의 언어 생성 등을 하고 싶다면 GPU를 이용하면 될 것이다.
이 글을 통해 후배, 동료 여러분에게 하고 싶은 말은 기술과 기술의 관계를 이해하며 나아갔으면 한다는 것이다. 캐나다의 연구원들은 기존 순서도 형태의 프로그램으로 해낼 수 없던 수많은 일을 인공신경망으로 해냈다. 그리고 인공신경망 구동은 기존 프로그램과 비교해 더 많은 사칙연산 횟수와 메모리가 필요했던 것일 뿐이다. 이러한 개선은 결국 위에서 살펴본 분기 속도를 2배로 올렸더니 전체 프로그램이 수십 퍼센트(%) 빨라졌던 것과 다르지 않다. 이런 사실을 잊지 않는다면, 이후에 새로운 프로그래밍 기술이 생겨났을 때 그 프로그램이 어떤 연산을 요구할지, 어떤 형태의 메모리를 요구할지도 알 수 있을 것이다.
다음 편부터는 인공지능 기술과 그 주변을 이루는 생태계를 살펴볼 것이다. 그리고 그 생태계들이 가지고 있는 한계와 어려움을 찾아보고, 반도체가 이를 어떻게 도와줄 수 있을지 살펴볼 것이다.
※ 본 칼럼은 반도체에 관한 인사이트를 제공하는 외부 전문가 칼럼으로, SK하이닉스의 공식 입장과는 다를 수 있습니다.



