첫 순서는 전기전자컴퓨터공학과 윤종혁 교수로부터 컴퓨팅 프로세스의 발전과 이러한 발전이 인공지능(AI, Artificial Intelligence)기술에 어떤 기여를 하고 있는지를 알아보고 CPU, GPU, 그리고 메모리 반도체의 역할과 성능이 어떻게 컴퓨팅 프로세스의 발전에 기여하는지 알아볼 것이다.
※ 대구경북과학기술원(DGIST, Daegu Gyeongbuk Institute of Science and Technology): 반도체 융합기술, 뇌공학, 마이크로레이저 등 다양한 첨단 과학 기술을 연구하고 있다. 특히 반도체 분야에서는 전문적인 연구개발(R&D)과 함께 캠퍼스 내 반도체 제조 시설을 구축 운영하고 있다.
일상으로 스며든 인공지능 기술
멀게만 느껴지던 인공지능이 점차 우리에게 가까워지고 있다. 최근에 뉴스에서 끊임없이 언급되고 있는 챗GPT도 인공지능 기반의 기술이니 말이다. 하지만 20년 전만 하더라도, 인터넷을 통한 자연어 검색 등 큰 규모의 서버에서 구현한 인공지능 정도만이 그나마 유용했다(엄밀하게 말하면 이러한 것들을 인공지능이라고 부르기도 전의 시대다). 이에 비해 당시 컴퓨터, 스마트폰 등 말단 장치(엣지 디바이스*)에서의 인공지능은 아주 미흡한 수준이었다. 1990년대 말에서 2000년대 초까지 마이크로소프트 오피스(Microsoft Office) 프로그램에 등장하던 길잡이 강아지를 기억하는 사람들은 이해할 것이다. 이 길잡이는 도움말 색인에 겹치는 일부 정보만 보여주거나 전혀 다른 정보로 응답했고, 심지어 기능을 끄는 것조차 쉽지 않아 사용자들에게 도움을 주기는커녕 불편하고 귀찮은 존재로 인식되곤 했다.
* 엣지 디바이스 (Edge Device) : 데이터 처리가 네트워크 중심에 위치한 클라우드가 아닌 엣지(가장자리)에서 이루어진다는 점에서, 기존 스마트 디바이스들과 구분해 ‘엣지 디바이스’라 지칭한다.
그렇다면 현재의 인공지능 수준은 어떠한가? 스마트폰의 사진 및 카메라 앱의 사례만 들어도 쉽게 확인할 수 있다. 지금은 스마트폰에도 신경망을 모사한 NPU* 등의 인공지능 칩들이 탑재돼, 굳이 서버의 힘을 빌리지 않아도 검색어만 입력하면 관련 사진을 분류해 볼 수 있고, 손쉽게 사진 내 객체를 편집할 수 있는 기능까지 기본적으로 지원하고 있다.
과거에는 왜 이러한 진보된 인공지능 기술이 없었을까? 2016년에 인공지능의 진보를 전 세계 사람들에게 각인시킨 ‘구글 딥마인드 챌린지 매치(이세돌-알파고의 바둑 대국)’ 이전에는 사람들이 인공지능 응용 분야에 대해 생각하지 않았던 것일까? 인공지능이 숨 쉬듯 주위에 존재하는 요즘엔 많은 사람이 알고 있을 이야기지만, 인공지능의 근본 원리는 1940년대에 제안됐으며, 그 실용성은 1970년대부터 2000년대 초까지 제프리 힌턴(Geoffrey Hinton) 연구 그룹에서 발표한 제한된 볼츠만 머신*, 역전파 알고리즘* 이론 등으로 이미 확보됐다. 오래전부터 인공지능의 이론은 확립돼 있었으나 그 응용 분야가 비교적 최근에야 발전하기 시작한 이유는, 인공지능 구현을 위한 연산 기능의 한계 및 데이터(신경망 가중치 및 결과값 등) 저장에 필요한 하드웨어 리소스의 한계 때문이었다.
* NPU(Neural Processing Unit, 신경망처리장치) : 머신러닝 구동에 최적화된 프로세서. 소프트웨어를 통해 인공신경망을 만들어 학습해야 하는 GPU와 달리 하드웨어 칩 단위에서 인공신경망을 구현하고자 했다는 특징이 있다.
* 제한된 볼츠만 머신(Restricted Boltzmann Machine, RBM) : 가시층 노드와 은닉층 간에 간선이 없는 볼츠만 머신으로 입력 집합에 대한 확률 분포를 학습할 수 있는 생성 확률적 인공 신경망이다.
* 역전파 알고리즘(Backpropagation algorithm) : 다층 구조를 가진 신경망의 머신 러닝에 활용되는 통계적 기법의 하나로, 예측값과 실제값의 차이인 오차를 계산해 이를 다시 반영해 가중치를 다시 설정하는 학습 방식
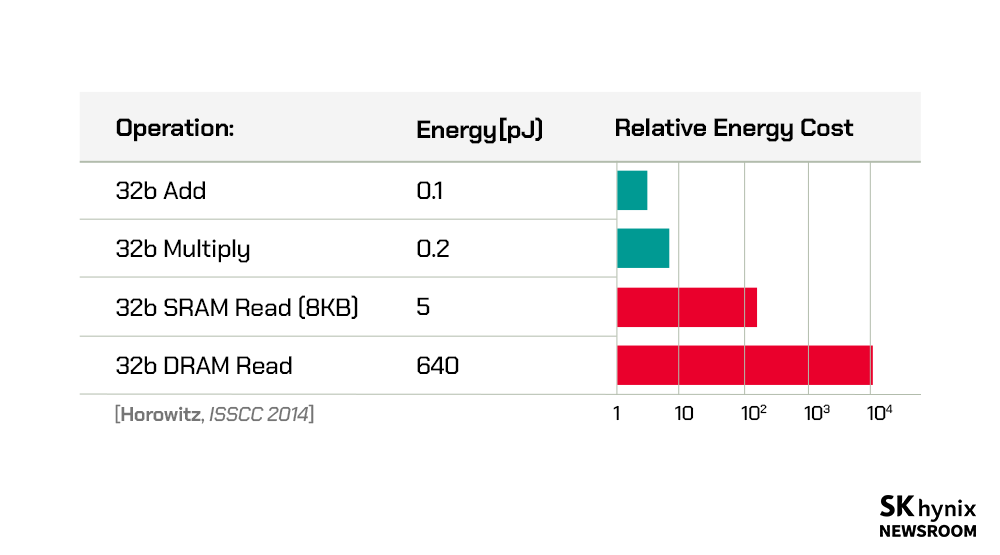
▲ 연산 및 메모리 접근에 따른 에너지 소모
우리가 흔하게 알고 있는 CPU와 GPU가 결국 최적의 MVM 연산을 지원하지 못하므로, 학계 및 산업계에서는 신속하고 에너지 효율적인 연산을 지원하기 위해 ASIC* 설계를 기반으로 한 연산 가속기들을 개발하고 있다. ASIC 칩들은 주로 디지털 연산 가속기이다. 큰 크기의 MVM에 특화된 연산 유닛을 많이 구현하고, 인공지능 네트워크 구조에 따라 가변 크기 MVM도 쉽게 지원할 수 있다.
그렇다면 디지털 연산 가속기는 인공지능 연산 하드웨어 자원을 확보할 수 있는 궁극적 해결책일까? 앞서 언급했듯, 인공지능 하드웨어의 요점은 MVM을 얼마나 효율적으로 빠르게 연산하는지에 달려있다. CPU, GPU, ASIC 기반 디지털 연산 가속기로 넘어오면서 연산 유닛의 효율성과 연산 속도는 증가했는데, 전체 시스템의 연산 효율성도 그에 정비례해 증가했을까? 이를 계산하기 위해서는 연산 전체 동작에 어떤 에너지가 얼마나 드는지 알아볼 필요가 있다.
컴퓨터의 일반적 구조인 폰 노이만 구조*에서는 연산 장치가 메모리에서 데이터를 읽어와 처리하고 다시 메모리로 보내는 방식으로 동작한다. MVM 연산은 인공지능 신경망의 입력과 메모리에 저장된 가중치 간의 곱 연산이므로, 1) 입력과 가중치를 연산 유닛까지 전달하는 에너지 및 2) 이를 이용한 연산 에너지가 전체 시스템의 연산 효율성을 결정한다. 이때, 입력은 외부에서 연산 유닛으로 직접 전달되므로 에너지 비중이 낮은 편이지만, 가중치의 경우 외부 D램에서 연산 유닛까지 데이터를 전달하는 데 연산 에너지 대비 약 500배 이상을 소모한다. 2020년 11월 미국 DARPA 워크숍에서 필립 웡(Philip Wong) 스탠퍼드대학교 교수도 메모리에서의 에너지 소모가 최대 연산 에너지 효율성을 제한한다고 했다. 즉, 우리가 연산 에너지를 줄이는 등 연산 효율성을 높이기 위해 노력했으나, 사실은 가중치를 메모리에서 읽고 쓰는 데 대부분의 에너지가 쓰이고 있었다. 이는 전체 시스템의 연산 효율성을 개선하기 위해 메모리의 읽기/쓰기 횟수가 줄어야 함을 의미한다.
* ASIC (Application Specific Integrated Circuit) : 일반적인 집적회로와 달리 특정한 제품에 사용할 목적으로 설계된 비메모리 반도체 칩
* 폰 노이만 구조 (Von Neumann Architecture) : 주기억 장치, 중앙 처리 장치, 입출력 장치의 전형적인 3단계 구조로 이루어진 프로그램 내장형 컴퓨터 구조. 오늘날 사용하고 있는 대부분의 컴퓨터가 이 기본 구조를 따르고 있지만, 병목 현상으로 인해 고속 컴퓨터의 설계에서 한계를 보인다.
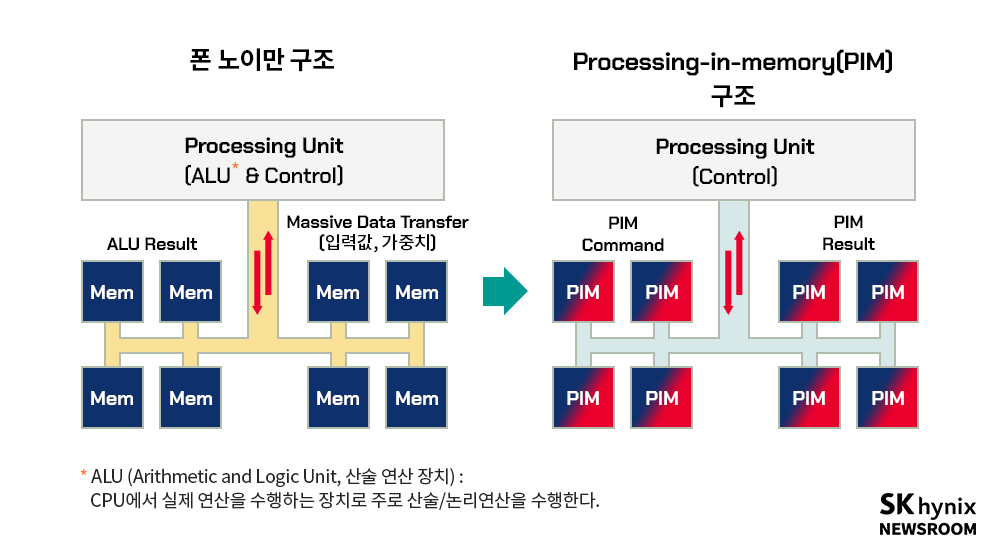
▲ 폰 노이만 구조에서 PIM 연산 구조로의 변화
연산 효율성을 위한 PIM 기반 가속기의 두 가지 구조: IMC, NMC
이에 착안해 등장한 것이 폰 노이만 구조를 탈피한 PIM(Processing In Memory) 기반 연산 가속기다. PIM은 메모리 내에서 연산을 수행하는 구조로, 가중치는 메모리 내에 그대로 존재하고 입력이 전달돼, 연산을 메모리에서 수행 후 그 결괏값만을 출력해주는 방식이다. 그리고 이러한 방식은 크게 메모리 내 연산(IMC)*과 메모리 인접 연산(NMC)*으로 나뉜다. 이는 PIM의 의미를 메모리 회로 내 연산으로 볼 것이냐, 메모리 모듈 내 연산으로 볼 것이냐의 차이로 구분할 수 있다. IMC는 메모리 회로를 연산이 가능하도록 수정 설계해 ASIC으로 구현하는 것이고, NMC는 메모리 모듈(메모리 칩을 포함한 반도체 기판) 내에서 HBM* 등 가중치를 위한 고집적 메모리와 MVM에 특화된 ASIC이 같이 집적된 것을 말한다. 참고로 설명하자면, 학계에서 PIM은 주로 IMC의 의미로 사용하며, 산업계에서는 NMC의 의미로 사용된다.
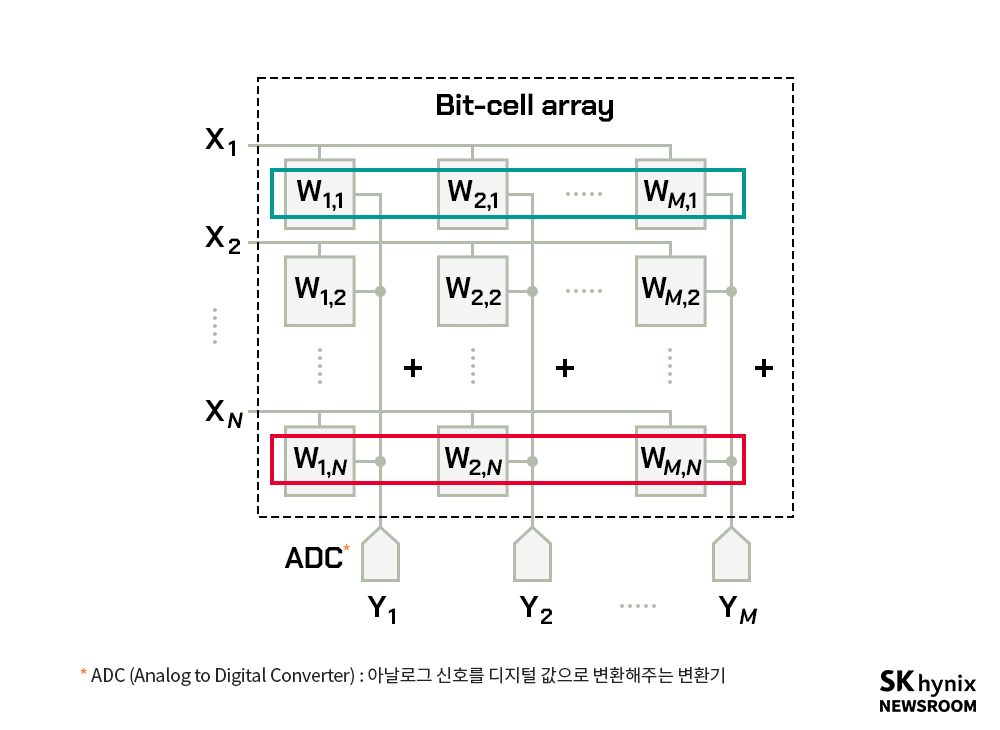
▲ 메모리 내 연산(IMC, In-Memory Computing) 모델 예시
기존 폰 노이만 구조의 경우 CPU와 메모리 간 연결이 메인보드-커넥터-메모리 모듈(DIMM)* 등 다수의 PCB*로 구성돼 있다. 반면 NMC의 경우 SiP*, 3D IC 등을 활용해 PCB 레벨이 아닌 단일 패키지 내에서 메모리와 연산 ASIC이 연결돼 가중치 접근을 위한 메모리 읽기/쓰기에 소모되는 에너지 및 지연시간을 크게 줄였다. IMC의 경우 NMC 방식에서 더 나아가 메모리 내에서 연산을 수행함으로써 앞서 말한 에너지 소모와 지연시간을 획기적으로 줄인 연산 방식이다.
그렇다면 IMC 방식이 더 효율적으로 보이는데 왜 IMC와 NMC 방식은 공존하고 있을까? 여기에는 연산 크기의 가변성, 연산 및 메모리 집적도, 대역폭 등의 이유가 작용한다. NMC는 한국의 강점인 고집적 메모리 반도체를 그대로 활용하면서 MVM 크기를 가변적으로 지원하는 연산 ASIC을 인접 배치 및 추가하는 것만으로 PIM 연산 구조를 지원할 수 있다. 반면 IMC는 효율성은 뛰어나지만 기존 메모리 회로를 연산에 용이하도록 수정 설계할 필요가 있어 높은 연산 효율성 대비 집적도 면에서 손해를 보고, 이는 가중치 저장 용량의 손실 및 대역폭의 하락으로도 이어진다.
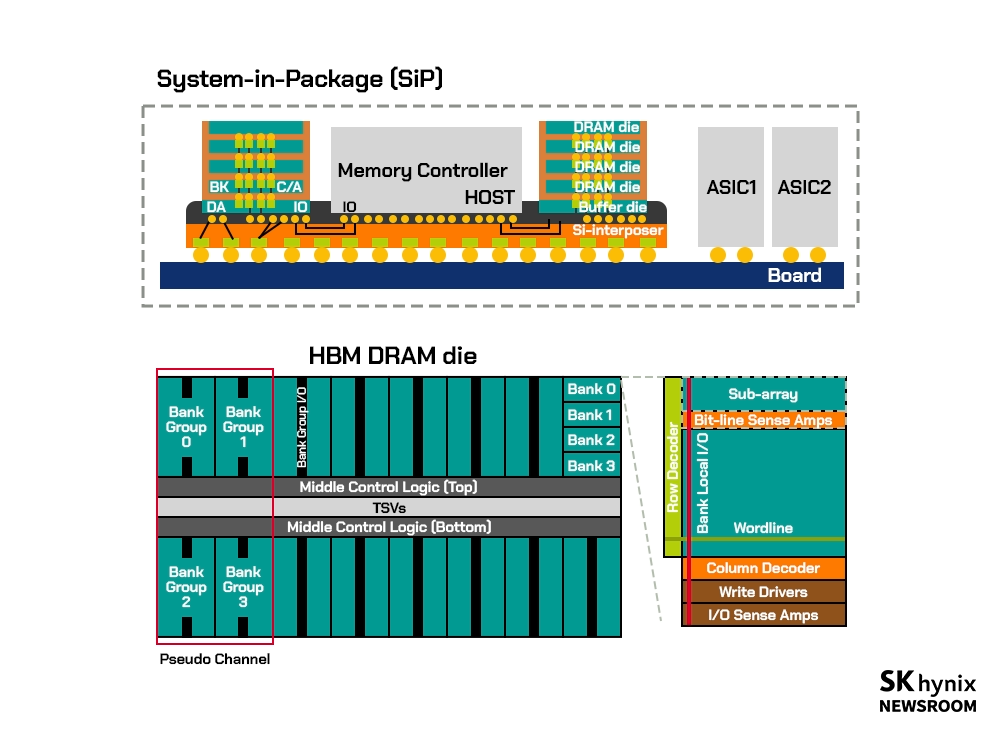
▲ 메모리 인접 연산(NMC, Near-Memory Computing)의 모델 예시
* 메모리 내 연산(IMC, In-Memory Computing) : 메모리가 직접 연산하는 기술, 주 연산 장치로 데이터를 이동하지 않고도 연산이 가능하기 때문에 매우 빠른 데이터 처리가 가능하며, 방대한 데이터를 빠르게 처리하고 분석하는 데 유리하다.
* 메모리 인접 연산(NMC, Near-Memory Computing) : IC패키지에 메모리와 연산 장치를 통합해 더 빠른 데이터 처리를 가능하게 하는 방법
* HBM(High Bandwidth Memory) : 여러 개의 D램을 수직으로 연결해 기존 D램보다 데이터 처리 속도를 혁신적으로 끌어올린 고부가가치, 고성능 제품
* 메인보드-커넥터-메모리 모듈(Dual In-line Memory Module, DIMM) : 여러 개의 DRAM 칩을 회로 기판 위에 탑재한 메모리 모듈로, 컴퓨터의 주기억 메모리로 쓰인다.
* PCB((Printed Circuit Board) : 전자 회로로 구성된 반도체 기판. 대부분의 전자 기기에 사용된다.
* SiP(System in Package) : 여러 블록을 개별적인 칩으로 구현한 후 수동 소자들까지 한꺼번에 단일 패키지에 결합한 하나의 완전한 시스템
PIM 성능을 결정짓는 가중치 용량과 이에 따른 연산 가속기 개발
한편, 연산 효율 외에도 저장 용량은 PIM에서의 중요한 성능 지표 중 하나다. 최근 오픈AI에서 GPT-3.5를 기반으로 개발한 챗GPT는 1,750억 개 이상의 가중치로 구성돼 있다. 그리고 각 가중치가 16비트 부동소수점(FP16)을 사용하므로 가중치 저장 용량에만 350GB 정도가 필요하다. 연산에 필요한 350GB의 가중치를 동시에 로드한 채로 연산할 수 없으므로, 결국 NMC의 연산 ASIC 또는 IMC 회로에서 많은 가중치를 활용할 수 있어야 가중치 업데이트 및 중간 결괏값 저장 횟수를 줄일 수 있다. 이에 따라 전체 동작 중 연산 동작을 수행하는 비율이 높아지고, 데이터 전송에 쓰이는 에너지는 줄어들게 되는 것이다. 이것만 고려하면 고집적 HBM을 활용한 NMC 기반 PIM 시스템이 더 주효한 접근으로 보인다.
그렇다면 큰 규모의 인공지능 시스템 외에, 엣지 AI에서는 어떨까? 엣지 AI에서는 단일 칩 내 모든 가중치를 탑재할 수 있는 응용 분야가 많이 존재한다. 엣지 AI는 배터리 기반으로 동작하는 경우가 많으며 초저전력 동작을 요구하기 때문에 메모리-연산 유닛 간의 데이터 이동에 소모되는 전력을 수용할 수 없는 경우가 많다. 따라서 말단 장치에서는 IMC와 같이 연산 에너지 효율이 높은 회로에 모든 가중치를 선탑재한 말단 엣지 AI 구현이 필요하다. 이때, 엣지 AI의 고도화를 위해서는 IMC 기반 PIM 시스템의 연산 효율성과 더불어 선탑재가 가능한 가중치 용량이 중요한 역할을 한다.
업계에서의 고도 인공지능을 위한 NMC 기반 PIM 시스템 연구 개발에 발맞춰, 학계에서는 엣지 디바이스 및 인공지능의 고도화를 위해 SRAM*, eDRAM*, D램 등의 휘발성 메모리 기반 PIM 연산 가속기와 RRAM*, PCRAM*, MRAM* 등의 차세대 비휘발성 메모리 기반 PIM 연산 가속기 설계 연구를 진행하고 있다. 휘발성 메모리 중 SRAM의 경우 CMOS 공정의 접근 용이성으로 인해 활발한 연구가 수행되고 있다. 전류 방식 연산부터 저항비, 전하 공유(Charge Sharing), 용량성 결합(capacitive coupling) 방식 등이 활용되고 있으며, 그중 커패시터*의 낮은 공정 편차를 활용하는 전하 공유 및 용량성 결합 방식이 SRAM-PIM 연산 가속기의 주된 연구 흐름이라고 할 수 있다.
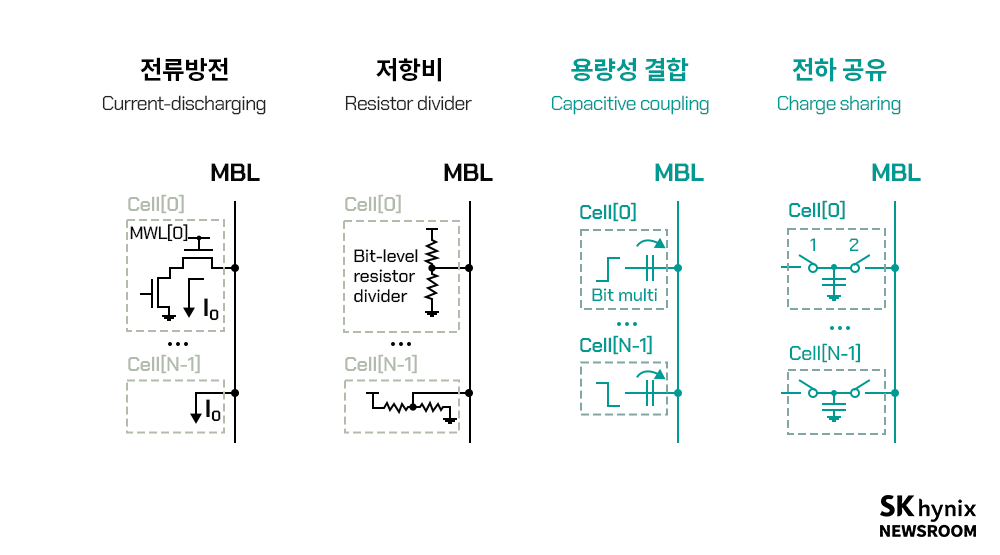
▲ SRAM 기반 PIM 연산 가속기의 연산 방식 종류 (출처: B. Zhang et al., “PIMCA: A Programmable In-Memory Computing Accelerator for Energy-Efficient DNN Inference” IEEE Journal of Solid-State Circuits, pp. 1–14, 2022, doi: 10.1109/JSSC.2022.3211290)
비휘발성 메모리는 휘발성 메모리 대비 높은 집적도와 연산 효율성을 가지고 있고, 가중치 유지를 위한 전원 유지의 필요가 없어, 초저전력 엣지 디바이스에 더 적합하다. 비휘발성 메모리 중 MRAM은 다른 비휘발성 메모리 대비 낮은 ON/OFF Ratio(1과 0을 표현할 때의 저항값 비율)로 인해 다중 비트 인코딩 등에 불리한 편이어서, RRAM과 PCRAM 등의 높은 ON/OFF Ratio를 활용한 PIM 연산 가속기들이 많이 연구되고 있다. 다만 비휘발성 메모리는 소자별 저항값 편차가 크다는 점 등의 낮은 기술 성숙도로 인해 부속 회로 구현이 추가로 필요하다. 이 때문에 PIM 연산 가속기의 전체 면적당 집적도 및 연산 효율성 면에서 SRAM 등 휘발성 메모리 기반 PIM 연산 가속기에 뒤처지고 있으나, 소자의 기술 성숙도 측면에서 발전 가능성이 높다. 이를 반영해 한국에서도 많은 연구개발(R&D) 사업을 진행 중이다.
* SRAM (Static Random-Access Memory) : 전원이 공급되는 동안 데이터를 온전히 저장하는 메모리, 단 몇 초 만에 데이터가 사라지는 DRAM과 차이점이 있다.
* eDRAM (Embedded DRAM) : ASIC 또는 마이크로프로세서의 동일한 다이 또는 멀티 치프 모듈 (MCM)에 통합된 DRAM
* RRAM (Resistive Random-Access Memory, 저항성 메모리) : 유전체 고형 상태 재료에 대한 저항을 변경해 작동하는 비휘발성 RAM의 유형
* PCRAM (Phase-Change RAM, 상변화메모리) : 일부 재료의 변화를 이용해 데이터를 저장하는 반도체 메모리. PCM은 플래시 메모리와 DRAM의 특성을 모두 갖추고 있으며, 플래시 메모리와 마찬가지로 비휘발성이므로 전원이 차단돼도 정보가 손실되지 않는다. DRAM과 마찬가지로 PCM은 데이터를 빠르게 처리하고 전력 효율이 높다는 특징이 있다.
* MRAM (Magnetoresistive Random-Access Memory, 자기저항성 메모리) : 데이터 저장에 대한 자기 저항을 이용하는 비휘발성 반도체 메모리의 일종. 플래시 메모리처럼 MRAM은 전원이 차단돼도 정보가 손실되지 않고, DRAM처럼 데이터를 빠르게 처리해 전력 효율이 높다.
* 커패시터 (capacitor): 메모리 반도체에서 데이터가 저장되는 장치를 지칭하며, 데이터가 담기는 방이라고 볼 수 있다.
더 나은 인공지능 실현을 위한 과제
과거 인공지능 개발은 앞서간 이론과 그것을 실현하기에는 부족한 하드웨어 간의 간극에 의해 발목이 잡혔다. 시간이 지남에 따라 하드웨어에서 CPU, GPU, 구글의 TPU* 등의 디지털 연산 가속기가 개발돼 오면서 인공지능 실현에 걸림돌이 되던 연산량 부분에서 획기적인 개선이 이뤄졌다. 여기에 더 나아가 PIM 연산 가속기의 등장으로 기존에 데이터 저장만을 담당하던 메모리가 이제는 연산을 포함한 두뇌의 역할에 다가서고 있다. 하지만 연산 분해능, 저장 용량, 지연 시간, 전력 소모 등 회로의 특성이 명확하지 않아, 지금까지 PIM 연산 가속기 연구는 갈 길이 멀다. 이를 극복하기 위해 앞으로는 하드웨어 영역에서 인공지능 알고리즘 지원을 위한 성능 개선 연구가 꾸준히 이뤄져야 한다. 또한 알고리즘 영역에서도 PIM 연산 가속기 특성을 고려한 인공지능 신경망의 최적화가 필요하며, 이를 기반으로 회로와 알고리즘의 결합이 PIM 연산 가속기 연구에서의 중요한 축이 될 것이다.
* TPU(Tensor Processing Units) : 구글이 자체 개발한 인공지능 전문 칩으로, 구글의 AI 기계 학습 엔진인 텐서 플로우에 최적화돼 있다. 2016년 1세대, 2017년 2세대 TPU가 공개됐다.
※ 본 칼럼은 반도체에 관한 인사이트를 제공하는 외부 전문가 칼럼으로, SK하이닉스의 공식 입장과는 다를 수 있습니다.



