요즘 인공지능(AI) 기술이 다양한 분야에서 활용되고 있다. 우리가 알지 못하는 사이 번호판 인식, 음성인식, 번역, 자연어 대화, 자율주행, 게임은 물론, 인간만이 가능하다고 여겨졌던 작곡, 회화 등 창의의 영역에서도 주목할만한 성과를 내고 있다. 심지어 20년 내로 인간의 지능을 뛰어넘는 AI가 등장해 인류를 위협할 것이라는 전망도 나온다.
AI가 이렇게 뛰어난 문제 해결 성과를 거두기 시작한 것은 기존의 컴퓨터에서 수행하던 것과는 전혀 다른 계산 방식인 신경망 회로(Neural Network)1)덕분이다. 현재 많은 연구자들이 기존의 방법으로는 해결이 어려웠던 문제들을 신경망 회로로 풀어내려 시도하고 있고, 21세기 들어 양자 계산기(Quantum Computing)2)와 함께 새로운 문제해결 방식으로 크게 주목받고 있다. 전통적인 컴퓨터는 부울대수(Boolean Alegebra)3)에 입각한 수학적인 모델을 바탕으로, 폰 노이만(Von Neumann) 구조의 컴퓨터를 통해 고안한 알고리즘을 실행하는 방식으로 문제를 해결했다. 하지만 이제는 전혀 다른 방식으로 새로운 능력을 보여주는 AI의 시대가 도래했다.
1) 일반적으로 ‘인공 신경망(Artificial Neural Network)’으로 불리는 ‘신경망(Neural Network)’은 동물의 뇌를 구성하는 생물학적 신경 네트워크에 영감을 받아 만들어진 컴퓨팅 시스템을 의미함.
2) 양자 계산기(Quantum Computing): 계산을 수행하기 위해 중첩, 간섭 및 얽힘과 같은 양자 상태의 집합적 특성을 이용하는 계산의 한 유형.
3) 부울대수(Boolean Alegebra): 변수들의 값이 참과 거짓인 대수학의 한 분야로, 보통 각각 1과 0으로 표시됨.
‘인식 모델부터 합성곱 신경망까지’ 신경망 회로의 역사

현재 대부분의 AI 분야에서 채택하고 있는 신경망 회로가 처음 등장한 지는 오래됐지만, 실제로 응용되기 시작한 시기는 비교적 최근이다. AI 연구 초창기에는 기존의 지식들을 표현하고 나열해 해답을 제시하는 전문가 시스템(Expert System), 컴퓨터와의 대화를 가능하게 하는 스크립트 기반(Script-Based) 대화형 에이전트(Agent) 등 인간의 사고를 모사하는 여러 인공 지능 기술이 혼재해 있었다. 신경망(Neural Network)도 문제 해결 방법 중 하나로 여겨졌지만, 실용화 단계에 이르기에는 너무 원시적이고 한계가 뚜렷했다.
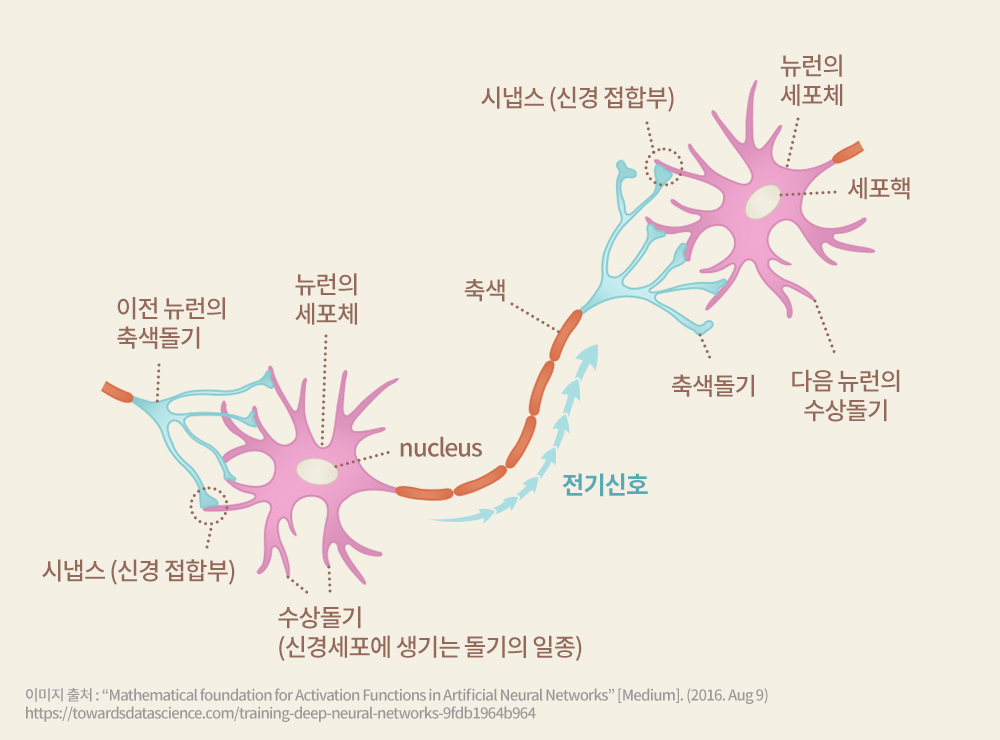
▲ 인공신경망의 활성화 기능을 위한 수학적 기초
신경망 회로는 생명체의 두뇌가 작동하는 원리를 본 따 만들어진 계산 방식이다. 신경망이 신경세포(Neuron)와 신경세포 간의 시냅스(Synapse)로 연결돼 있다는 사실이 신경해부학적으로 밝혀진 이후, 이 동작에 대한 수학적인 모델이 1943년 워렌 맥컬로치(Warren McCulloch)와 월터 피츠(Walter Pitts)에 의해 확립됐다. 이 모델은 ‘퍼셉트론 모델(Perceptron Model)’이라고 불리며, 뇌를 구성하는 신경세포의 동작을 모사해 다양한 논리적인 연산을 할 수 있음을 보여줬다.
그러나 1969년 저명한 수학자인 마빈 민스키(Marvin Minsky)와 시모어 페퍼트(Seymour Papert)가 ‘퍼셉트론 모델은 선형 함수 정도의 문제만 풀 수 있을 뿐, 단순한 배타적 논리합(XOR) 계산4)도 불가능하다’고 폄하한 이후에는 관심 밖으로 밀려났다. 또한 신경망 계산의 핵심을 이루는 시냅스 가중치(Synapse Weight)5)를 학습해 결정하는 방식도 어려워 실용화되지 못하고 있었다.
4) 배타적 논리합(XOR, exclusive OR) 계산: 두 개의 입력값이 서로 다를 때 결과값을 ‘참(True)’으로 도출하는 계산.
5) 시냅스 가중치(Synapse Weight): 전기 신호를 인접한 뉴런으로 전달하는 신호 전달 능력.
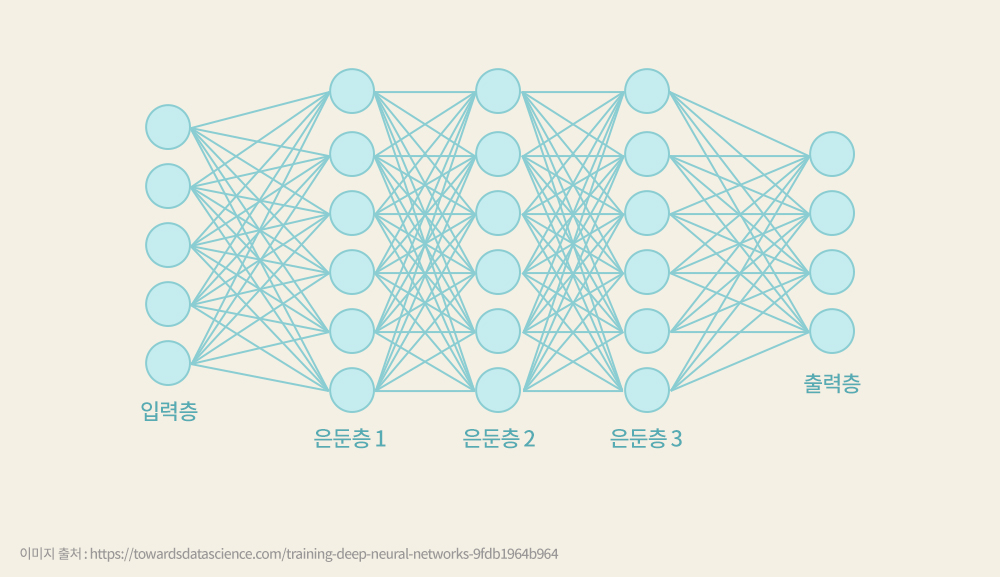
▲ 신경망 회로
그러던 중 2010년 토론토 대학교의 제프리 힌턴(Geoffrey Hinton) 교수가 ‘ReLU(Rectified Linear Unit)’라고 명명한 활성화 함수(Activation Function)를 채택한 것이 신경망 회로에 대한 연구에 또 한 번의 전기를 마련했다. ReLU를 활용해 시냅스 가중치가 멀티 레이어를 뚫을 때, 즉 출력에서 입력 방향으로 정보를 역전파(Back Propagation)할 때 학습의 정확도를 높일 수 있다6)는 단순하지만 획기적인 방법을 제시한 것.
힌턴 교수의 연구 그룹은 2012년 컴퓨터 비전(Computer Vision)7) 분야에서 가장 어려운 문제로 꼽히는 이미지 분류에 심층 신경망(Deep Neural Network, DNN)의 학습 방법을 적용한 ‘알렉스넷(AlexNet)’을 발표했다. 알렉스넷은 고양이의 눈이 망막에 맺힌 이미지를 처리하는 방식을 모사해 합성곱 신경망(Convolutional Neural Net, CNN) 구조를 도입했고, 그 결과 기존 기술의 한계를 크게 뛰어넘어 사람의 이미지 분석 능력에 필적하는 성능을 낼 수 있었다.
심층 신경망은 보통의 신경망이 4-5개 정도의 층(Layer)을 가지는 데 비해 10개 이상의 은닉층(Hidden Layer)을 가진 깊은 수직 구조로 이루어져 있다. 이 과정에 필요한 계산량을 기존의 컴퓨터로 감당하기에는 너무 많은 시간이 소요돼, 실용화가 어려웠다. 그러나 엔비디아(NVIDIA)가 대량 병렬 연산 기능을 가진 GPU를 활용해 기존 방법으로 해결이 어려웠던 문제에 대해 심층 신경망을 구성하고 신경망이 시냅스 가중치를 빠르게 학습하도록 해, 실용 가능성을 크게 높였다.
이제 심층 신경망은 다양한 응용 분야에 적용되고 있고, 많은 연구자들이 심층 신경망의 새로운 구조를 경쟁적으로 연구하고 있다. 이에 따라 AI의 문제 해결 능력도 급속도로 발전하고 있으며, 응용 분야도 확대되고 있다. 이제는 신층 신경망 구조의 AI가 어려운 문제를 해결하는 데 있어 만병통치약처럼 여겨지기 시작했다.
6) 역전파 알고리즘(Back Propagation Algorithm): 다층 구조를 가진 신경망의 머신 러닝(Machine Learning)에 활용되는 통계적 기법 중 하나로, 예측값과 실제값의 차이인 오차를 계산해 이를 다시 반영해 가중치를 다시 설정하는 방식의 학습 방식을 의미함.
7) 컴퓨터 비전(Computer Vision): 컴퓨터를 활용해 인간의 시각적인 인식 능력을 재연하는 기술 분야.
인간의 능력을 넘어서기 위해, 차세대 AI 반도체의 미래
이렇게 심층 신경망이 이론적인 기초를 넘어 응용에 이를 수 있었던 것은 GPU로 대표되는 하드웨어의 데이터 처리 성능이 발전한 덕분이다. 방대한 양의 데이터를 빠르게 처리할 수 있는 GPU가 등장하지 않았다면, AI 기술의 발전은 지금보다 훨씬 늦어졌을 것이다. 궁극적으로 인간의 능력을 뛰어넘는 AI를 만들기 위해서는 당연히 지금보다 훨씬 더 높은 컴퓨팅 성능(Computing Power)이 필요하다. 그리고 이를 구현하기 위해서는 현재의 GPU 성능을 훨씬 능가하는 차세대 AI 반도체가 필요하다.
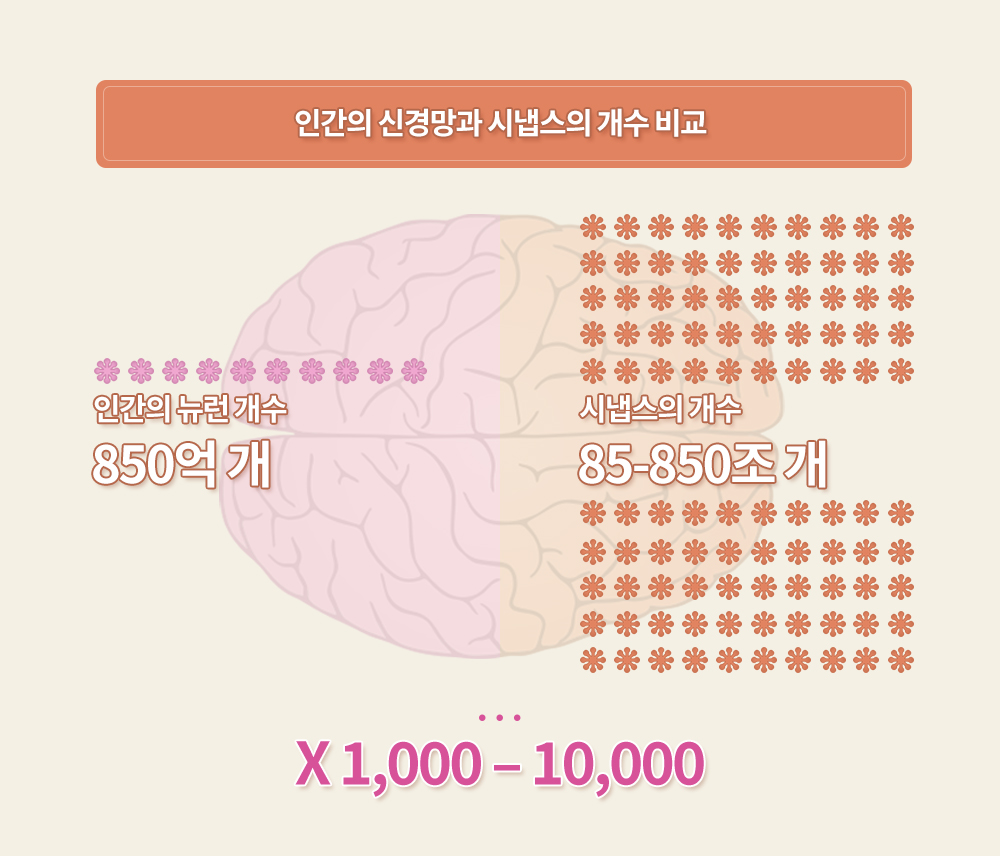
인간의 신경세포 개수는 약 850억 개 정도로 알려져 있고, 이들 사이를 연결하는 시냅스의 개수는 신경세포 개수의 약 1,000~1만 배에 달한다. 따라서 사람의 두뇌를 모사하기 위해서는 85조에서 850조 개 정도의 시냅스 가중치와 이 값을 저장할 수 있는 대용량 저장장치가 필요하다. 이처럼 방대한 규모의 계산은 현재의 반도체 기술 수준으로는 감당하기 어렵지만, 전문적으로 설계된 AI 반도체가 등장하면 감당할 수 있을 것으로 예상된다.
AI 기술의 응용 분야가 지속적으로 확대되고 있는 만큼, AI 반도체의 성능은 급격히 개선되고 관련 시장도 폭발적으로 성장할 것이다. 기업들의 투자 규모 역시 2024년 약 52조 원 수준에서 2030년까지 약 140조 원으로 크게 확대될 것으로 전망된다.
AI 반도체는 응용 분야에 따라 크게 중앙 서버에서 데이터를 처리하는 클라우드 서비스용 반도체와 네트워크 말단인 기기에서 데이터를 처리하는 엣지 컴퓨팅(Edge Computing)용 반도체로 구분할 수 있다. 각각 요구되는 특성은 매우 다르지만 시장의 크기는 서로 비슷할 것으로 예상된다.
또한 AI 반도체는 기능에 따라 크게 2가지 전문 분야로 구분할 수 있다. 하나는 추론(Inference), 다른 하나는 학습(Training)이다. 이때, 학습 기능은 일반적으로 추론 기능을 포함한다.
추론은 이미 학습된 내용을 바탕으로 입력에 알맞은 출력을 해내는 일방향성 계산으로, 주로 8bit 이하 정밀도를 가진 행렬-벡터(Matrix-Vector) 곱셈 방식이 활용된다. 반면, 학습이 목적이라면 16~32bit 수준의 높은 정밀도가 필요하고, 신속한 학습을 위해 방대한 양의 데이터를 일괄적으로 처리할 수 있어야 한다. 이를 위해 행렬-행렬(Matrix-Matrix) 연산이 주로 사용되는데, 단순한 추론에 비해 많은 계산이 필요한 탓에 소모되는 에너지도 크다. 다행히 학습은 한 번만 수행하면 되고, 시냅스 가중치가 결정되면 그 이후에는 추론만 전문적으로 하는 저전력 AI 반도체를 대량으로 사용하게 된다.
‘더 유용하게, 더 효율적으로’ 구글, TPU로 AI 전용 반도체 시대를 열다
구글은 클라우드 서비스의 최강자인 동시에, 경쟁자들에 비해 AI 서비스를 더 효율적으로 운용할 수 있도록 하는 데 많은 관심을 갖고 있다. 특히 딥 러닝(Deep Learning)8)을 진행할 때, 데이터를 더 빠르고 경제적으로 처리하는 데 특화된 전용 프로세서(Processor)의 필요성도 인식하고 있다.
가장 현실적인 방법은 엔비디아의 GPU를 사용하는 것이지만, GPU의 본래 용도는 영상 이미지 합성이다. GPU는 광선 추적(Ray Tracing)9) 계산을 위해 프로그램 방식의 ‘단일 명령 다중 데이터 처리 구조(Single-instruction Multiple Data Processor)’10)를 채택하고 있다. 하나의 프로그램 안에서 데이터를 처리할 수 있는 ‘Programmable Processor’인 만큼 고속 게임용 그래픽 처리에는 최적화돼 있지만, 딥 러닝과 같은 머신 러닝을 수행할 심층 신경망에 활용하기에는 또한 지원하는 데이터 유형이 그래픽에 맞춰져 있어 연산 방식이 다르고, 기능이 다양한 만큼 에너지 효율도 좋지 않다.
이에 구글은 AI 서비스에 특화된 자체 프로세서를 만들기 위해 지난 2013년 기업 내 ‘Processor Architecture Team’을 구성해 데이터 분석과 딥 러닝을 위한 TPU(Tensor Processing Unit) 개발에 착수했고, 2015년부터 클라우드 서비스에 활용하기 시작했다.
TPU의 자세한 기능과 구성은 베일에 싸여 있다가 2017년 공개됐는데, 이 반도체 칩 내부에는 심층 신경망의 추론 기능을 효율적으로 구현하기 위해 시냅스 가중치를 담고 있는 거대한 행렬과 각 층의 입력에 해당하는 벡터를 곱하는 기능이 장착됐다. 필요한 계산을 병렬 구조로 시간 낭비 없이 겹쳐 계산하는 ‘파이프라인’ 방식의 시스톨릭(Systolic)11) 구조를 채택해, 처리 성능도 크게 개선했다.
1세대 TPU는 28nm(나노미터) 공정으로 만든 주문형 반도체(Application Specific Integrated Circuit, ASIC)12)다. 인공지능이 인간을 이기기 어렵다고 여겨지던 바둑 분야에서 인간에게 승리를 거둔 AI 바둑 프로그램 ‘알파고(AlphaGo)’에도 TPU가 탑재돼 있다. 알파고는 2016년 3월 개최된 ‘Google Deepmind Challenge’에서 이세돌 9단에게 총 전적 4승 1패로 승리하며, AI의 능력이 인간의 능력을 넘어설 수 있음을 보여줬다.
8) 딥 러닝(Deep Learning): AI에 데이터를 학습시키는 머신 러닝의 한 분야로, 빅데이터를 컴퓨터가 처리할 수 있는 형태인 벡터나 그래프 등으로 표현하고 이를 학습하는 추상화 모델을 구축하는 기술 또는 시스템(알고리즘).
9) 광선 추적(Ray Tracing): 그래픽이 표시하고자 하는 사물과 주변의 광원 상태를 인지해, 광원에서 나오는 광선이 물체에 끼치는 영향(현상)을 연산(시뮬레이션)을 통해 이미지화하는 기법.
10) 단일 명령 다중 데이터 처리 구조(Single-instruction Multiple Data Processor): 하나의 명령어로 여러 데이터를 동시에 처리하는 병렬 구조의 처리장치.
11) 스톨릭(Systolic): 반도체 내부의 셀(Cell)들이 연결망(Network)을 구성해 전체적인 동기 신호에 맞춰 하나의 연산을 수행하는 구조.
12) 주문형 반도체(Application Specific Integrated Circuit): 특정 목적으로 설계된 시스템 반도체.
AI 반도체 성능 향상의 열쇠는 ‘메모리 반도체’…구글, TPU에 HBM 채택해 학습 가속화
TPU에서 Tensor는 2차 이상의 다차원 행렬(Matrix)을 지칭한다. 구글에서 개발한 1세대 TPU는 추론을 위해 제작된 AI 반도체 칩으로, 2차원의 추론 기능만 할 수 있었다. 이후 구글은 2세대 TPU를 2017년 공개했는데, 여기에는 다차원 함수를 계산하는 기능이 탑재돼 추론과 더불어 학습도 가능해졌다.
구글은 이후 2018년 3세대 TPU, 2020년 4세대 TPU를 차례로 선보였는데, 외부 메모리로는 기존의 DDR(Double Data Rate) DRAM이 아닌 2.5차원(2.5D) 시스템 구성이 가능한 차세대 고대역폭 메모리 반도체인 HBM(High-Bandwidth Memory)을 채택했다.

▲ SK하이닉스가 업계 최초로 출시한 HBM3
HBM은 기존 서버에서 주로 사용되던 DDR DRAM에서 크게 발전된 형태를 갖추고 있다. HBM은 4개 또는 8개의 DRAM 칩을 수직으로 적층해 더 많은 저장 용량을 확보했다. 또한 입출력 성능을 획기적으로 개선하기 위해 2,000개 이상의 많은 연결선을 할당했고, 이를 기존에 주로 사용하던 인쇄회로 기판(Printed Circuit Board, PCB) 대신 미세회로 기판인 ‘실리콘 인터포저(Si Interposer)’로 연결했다. 그 결과 HBM은 고성능 시스템 구성을 위한 필수 메모리 반도체로 각광받고 있다.
SK하이닉스는 현재 HBM2E 시장을 선도하고 있으며, 최근 업계 최초로 차세대 표준인 HBM3 개발에 성공하며 관련 시장의 주도권을 놓치지 않고 있다.
AI 반도체에 가장 효율적인 구조를 찾기 위해서는 시스템 운용 관련 데이터가 필요한데, 구글은 자체적으로 대규모 클라우드 서비스 센터를 운용하고 있어 정보 획득도 용이하다. AI 서비스를 효율적으로 운영하기 위한 실사용 데이터는 물론, 서비스 효율화를 가로막는 장애물이 무엇인지 파악할 수 있는 다양한 데이터를 확보할 수 있어, 이를 바탕으로 최적화된 AI Accelerator13)를 지속적으로 개발할 수 있는 체계를 갖출 수 있다. 구글은 이러한 강점을 활용해 앞으로도 다양한 응용 분야에 대응할 AI 반도체 칩을 지속적으로 선보일 전망이다.
엔비디아의 경우, ‘Programmable Processor’로의 정체성은 유지하면서도 그래픽뿐 아니라 AI Accelerator로 효율적인 새로운 GPU 모델이 계속 개발되고 있다. 구조 역시 다양한 응용 분야에 대응하기 위해 유연하게 설계돼 있다. 그러나 특정 응용 분야에 대해 최적화되어 있는 구글의 TPU에 비해서는 성능과 에너지 효율이 떨어질 수밖에 없다.
엔비디아 입장에서는 계속 경쟁력 있는 GPU를 내놓기 위해 구글을 비롯한 페이스북(Facebook), 아마존(Amazon), 마이크로소프트(Microsoft)와 같은 클라우드 서비스 운영 기업들로부터 다양한 응용 분야에서의 실사용 데이터를 비롯해 더 효율적인 운용을 위한 데이터를 수집하는 것이 중요하다. 또한 계속 변화하는 응용 분야에 대응해 경쟁력을 유지하려면 반드시 AI 반도체 칩 개발을 지속해야 한다.
13) AI Accelerator: AI를 위한 데이터 처리와 연산에 특화된 하드웨어 또는 프로세서.
맞춤형 AI 반도체 칩 제작 트렌드는 앞으로도 지속될 전망
최근 프로세서 설계와 제작은 더 이상 인텔(Intel)이나 AMD, 삼성전자 등 시스템 반도체 제조 기업만의 전유물이 아니다. 누구든 고도로 발달한 설계 자동화 도구(Design Automation Tool)를 이용해 효율적인 설계가 가능하고, 최첨단 공정을 제공하는 파운드리(Foundry, 반도체 위탁생산 업체)를 통해 자체 응용 분야에 최적화된 기능을 가진 프로세서를 맞춤형으로 제작할 수 있다.
실제로 애플(Apple)은 아이폰(iPhone)에 사용되는 모바일용 프로세서(Application Processor, AP)에 자사가 설계한 반도체 칩을 사용하는 것에서 한 걸음 더 나아갔다. PC의 CPU를 자체 설계해 인텔 칩을 사용하던 맥(Mac PC)의 성능과 에너지 효율을 크게 향상시킨 것. 애플이 설계한 ‘M1’칩의 최상위 모델인 M1Max 프로세서는 3.2GHz에서 570억 개의 트랜지스터, 10개의 코어를 갖추고 동작하며, 인텔의 최신 프로세서인 11세대 i9에 비해 성능과 에너지 효율 면에서 크게 앞선 성능을 자랑한다.
반면, 인텔의 경우 기존 프로세서와의 명령어 호환성 때문에 최적의 프로세서 구조를 채택하기 어려운 것이 단점으로 작용하고 있다. 특정 응용 분야에 최적화된 고유의 프로세서를 개발하는 추세는 앞으로도 계속될 것이며, 특히 클라우드 서비스를 운영하는 기업은 심층 신경망에 일반 프로세서를 사용하는지, 특화된 프로세서를 사용하는지에 따라 서비스의 질에서 큰 차별성이 나타날 것으로 보인다. 다만 반도체 칩을 자체적으로 설계하기에는 많은 자본과 인력이 소요되기 때문에, 그 이득이 비용을 상쇄할 수 있는 소수의 대형 클라우드 서비스 운영 기업만이 AI 반도체 칩 제작에 뛰어들 수 있을 것이다.
이러한 추세와 더불어 현재 많은 반도체 설계 전문 회사들이 GPU를 능가하는 클라우드 서비스용 범용 AI 반도체 칩을 목표로 개발을 진행하고 있다. 하지만 다양한 응용 분야에서의 실사용 데이터를 확보해야만 경쟁력 있는 AI 반도체 칩 개발이 가능한 만큼, AI 반도체 전문 팹리스(Fabless, 반도체 설계 전문 업체)들은 클라우드 서비스 운영 기업과의 공동 개발이 반드시 필요할 것이다.
※ 본 칼럼은 반도체/ICT에 관한 인사이트를 제공하는 외부 전문가 칼럼으로, SK하이닉스의 공식 입장과는 다를 수 있습니다.



