우리 삶을 혁신적으로 바꾸고 있는 인공지능(Artificial Intelligence, AI). AI를 알고, 이해하고 또 활용하고 싶은 이들을 위해 <AAA – All Around AI>에서 AI 기술에 대한 모든 것을 알려드립니다. 1화에서는 인공지능의 역사적 발전 과정과 그것이 현재 우리 삶에 어떻게 녹아들었는지 살펴봅니다.
<시리즈 순서>
① AI의 시작과 발전 과정, 미래 전망
② AI 알고리즘의 기본 개념과 작동 원리
③ 머신러닝의 이해
④ 딥러닝의 이해
⑤ 스마트폰과 온디바이스(on-device) AI의 미래
⑥ 생성형 AI의 개념과 모델
인공지능을 탑재해 사람처럼 걷고 말하며 생각하는 로봇은 과거 공상과학 만화와 영화의 단골 소재였다. 인간의 상상 속에서만 존재하던 AI와 로봇은 더 이상 꿈이 아니다. 이제 현실로 구현되며 사람들의 일상을 바꾸고 있는 AI는 언제부터 시작되어 어떻게 발전해 왔으며, 앞으로 어떤 미래를 만들어 나갈까?
‘AI’의 시작과 발전 과정
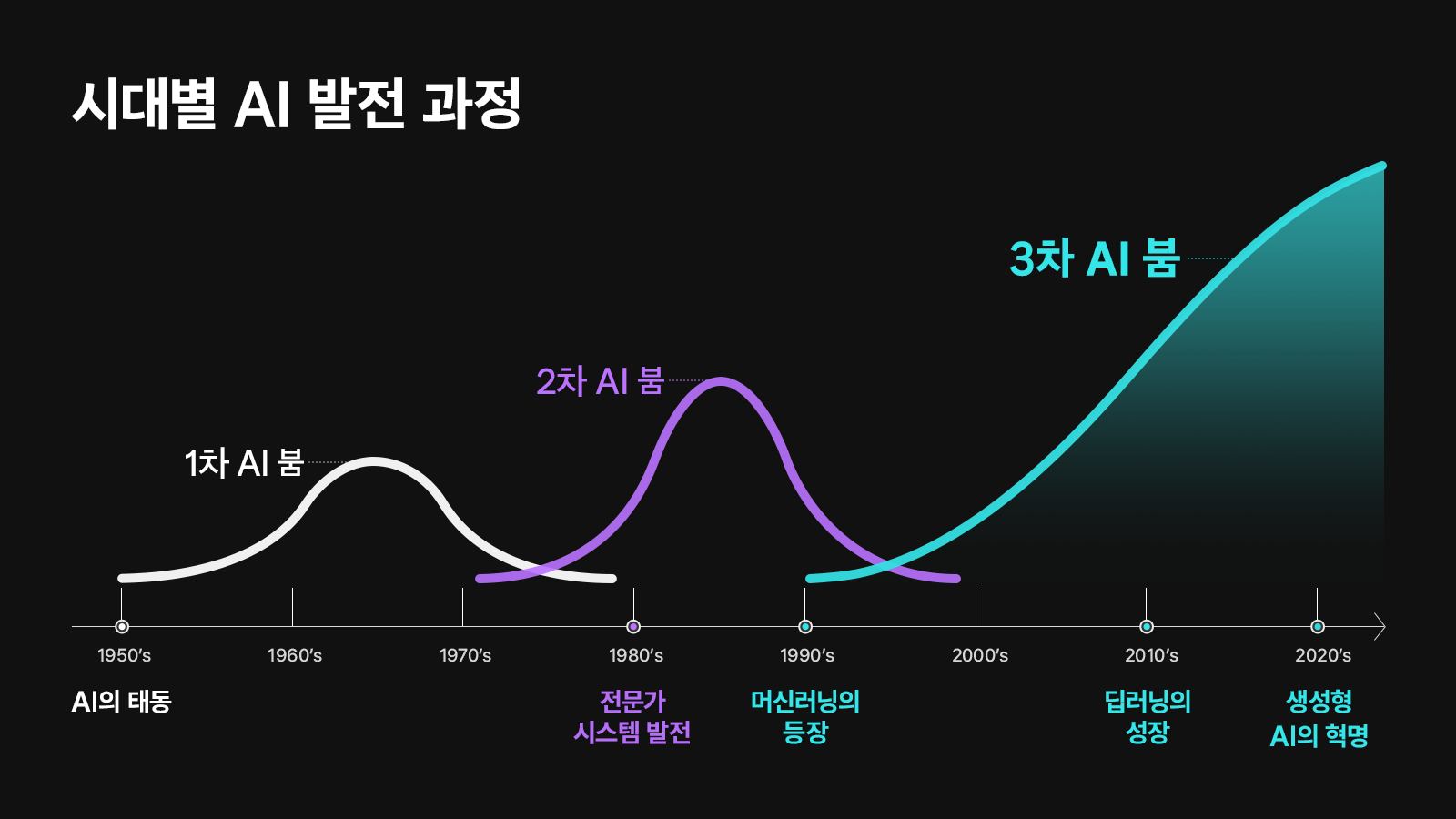
AI의 시작은 1950년대로 거슬러 올라간다. 1950년, 영국의 수학자 앨런 튜링(Alan Turing)은 기계는 생각할 수 있다고 주장하며, 이를 테스트하기 위한 방법으로 ‘튜링 테스트(The Turing Test)’를 고안했다. 이것은 AI라는 개념을 최초로 제시한 연구로 꼽힌다. 1956년에는 AI의 개념을 세상에 알린 다트머스 회의(Dartmouth Conference)가 열렸다. 이 회의에서는 기계가 인간처럼 학습하고 발전할 수 있는지에 대한 토론이 이루어졌으며, 인공지능이라는 용어가 처음 사용되었다.
이 시기에는 인공신경망(Artificial Neural Network) 모델에 관한 연구도 활발히 진행되었다. 1957년, 프랑크 로젠블랏(Frank Rosenblatt)은 ‘퍼셉트론(Perceptron)’ 모델을 통해 컴퓨터가 패턴을 인식하고 학습할 수 있다는 개념을 실증적으로 보여줬다. 이는 1943년에 신경 생리학자 워렌 맥컬럭(Warren McCulloch)과 월터 피트(Walter Pitts)가 신경세포의 상호작용을 간단한 계산 모델로 정리한 ‘신경망’ 이론을 실제 테스트에 활용한 것이다. 이러한 초기 연구의 성과는 세간의 기대를 높였으나, 컴퓨팅 성능, 논리 체계, 데이터 부족 등의 한계로 AI 연구는 곧 침체기에 들어섰다.
1980년대에는 사람이 입력한 규칙을 기반으로 자동 판정을 내리는 ‘전문가 시스템(Expert System)’이 등장했다. 전문가 시스템은 의학, 법률, 유통 등 실용적인 분야에서 진단, 분류, 분석 등의 기능을 수행하며, 일시적으로 AI에 대한 관심을 다시 불러일으켰다. 그러나 이 시스템은 사람이 설정한 규칙에만 의존하여 동작하며, 복잡한 현실 세계를 이해하는 능력을 갖추지 못했다는 한계가 있었다.
인간의 명령으로만 작동하던 AI는 1990년대 들어서 스스로 규칙을 찾아 학습하게 된다. 바로 ‘머신러닝(Machine Learning, 기계학습)’ 알고리즘을 활용하면서부터다. 이것이 가능해진 이유는 디지털과 인터넷이 등장했기 때문이다. 웹에서 수집한 대량의 데이터를 활용할 수 있게 되면서, AI는 스스로 규칙을 학습하고 나아가 사람이 찾지 못하는 규칙까지 찾아낼 수 있게 되었다. AI 연구는 머신러닝을 기반으로 다시 성과를 내기 시작했다.
AI의 핵심 기술, ‘딥러닝’의 발전
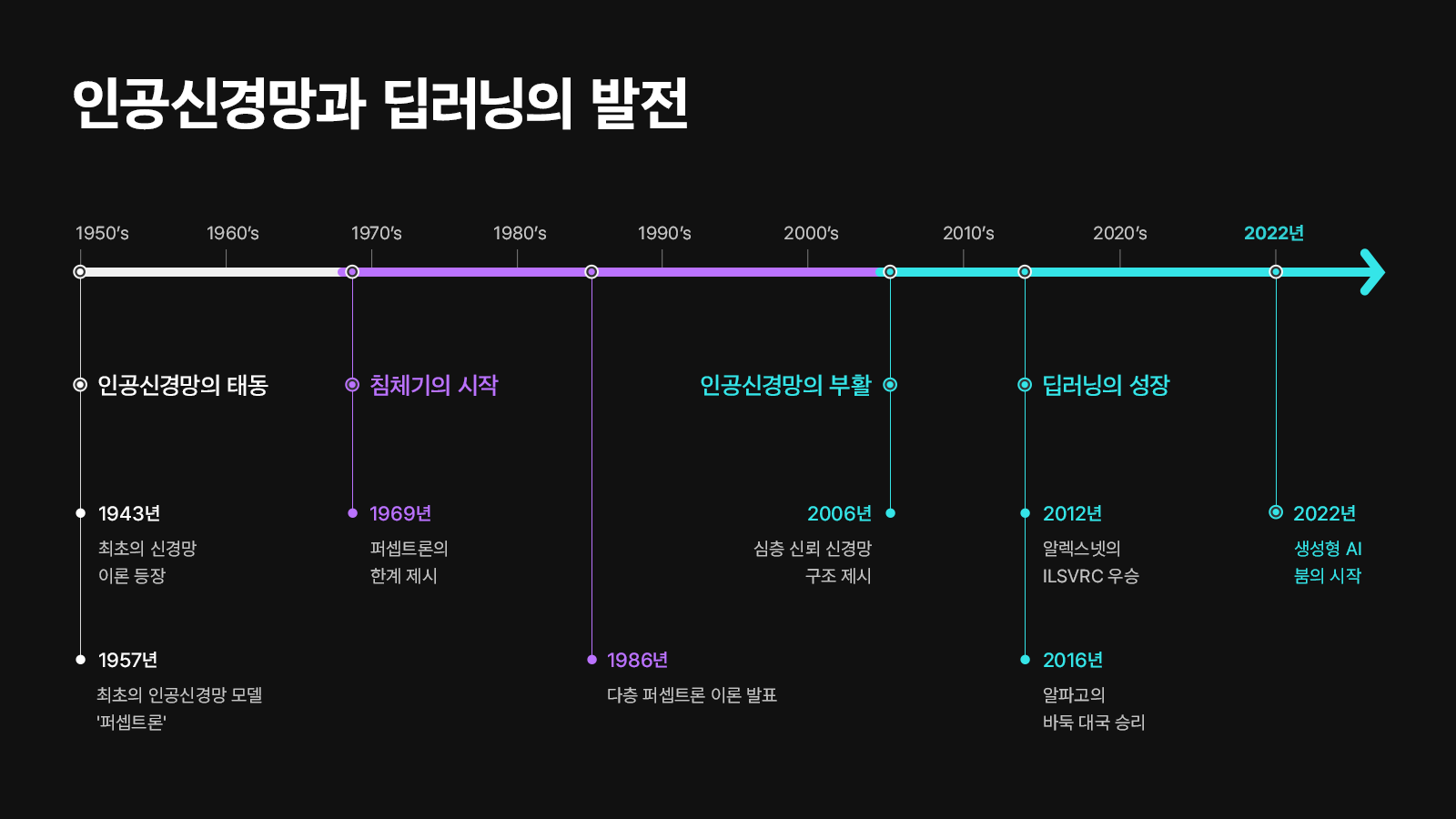
인공신경망 초기 연구는 1969년, 앞서 언급했던 퍼셉트론 모델이 비선형 문제를 해결할 수 없다는 것*이 밝혀지면서 긴 침체기에 접어들었다. 이후, 인공신경망 연구를 다시 수면위로 끌어올린 인물은 ‘딥러닝의 대부’로 불리는 제프리 힌튼(Geoffrey Hinton, 이하 힌튼)이다.
1986년, 힌튼은 인공신경망을 여러 겹 쌓은 다층 퍼셉트론(Multi-Layer Perceptrons) 이론에 역전파* 알고리즘을 적용하여 퍼셉트론의 기존 문제를 해결할 수 있음을 증명했다. 이를 계기로 인공신경망 연구가 다시 활기를 되찾는 듯했지만, 신경망의 깊이가 깊어질수록 학습 과정과 결과에 이상이 나타나는 문제가 발생했다.
2006년, 힌튼은 ‘A fast learning algorithm for deep belief nets’라는 논문을 통해 다층 퍼셉트론의 성능을 높인 ‘심층 신뢰 신경망(Deep Belief Network, DBN)’을 제시했다. 심층 신뢰 신경망은 비지도학습*을 통해 각 층을 사전 훈련한 후, 전체 네트워크를 미세 조정하는 방식으로 신경망의 학습 속도와 효율성을 크게 높였다. 또한 AI 기술을 대표하는 알고리즘인 ‘딥러닝(Deep Learnning)’의 기초 개념을 정립했다.
▲ Kien Nguyen, Arun Ross. “Iris Recognition with Off-the-Shelf CNN Features: A Deep Learning Perspective”, IEEE ACCESS SEPT(2017), p.3
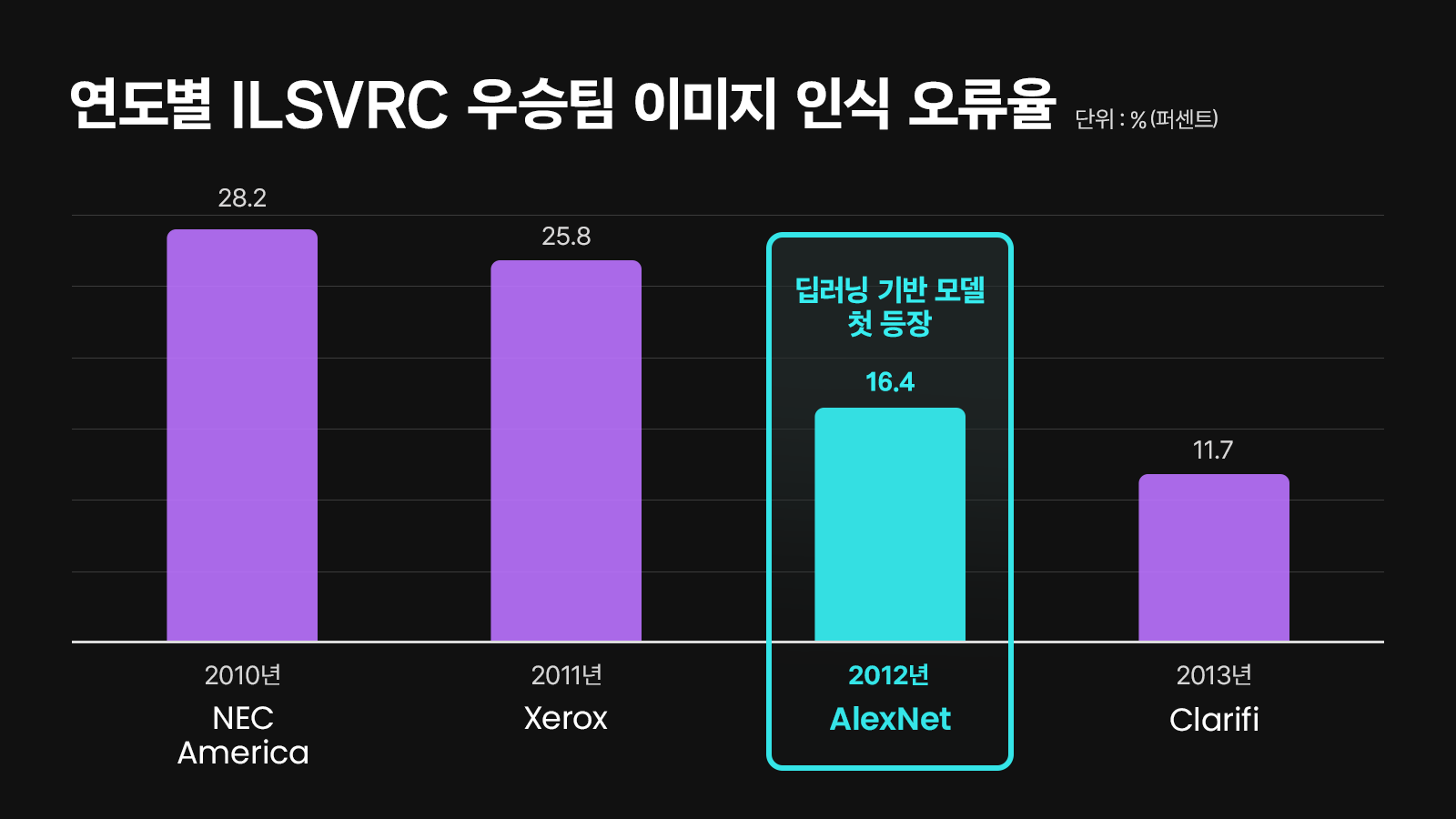
그리고 2012년, 딥러닝의 압도적인 성능을 증명한 역사적인 사건이 발생한다. 바로 이미지 인식 경진대회인 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)에서 힌튼이 이끄는 팀의 알렉스넷(AlexNet)이 우승을 차지한 것이다. 딥러닝 기반의 모델인 알렉스넷은 이미지 인식률 84.7%를 기록했는데, 이는 다른 모델과 비교했을 때 월등히 높은 수치였다. 특히, 전년도 우승팀의 오류율 25.8%를 무려 16.4%까지 낮추는 기염을 토했다.
AI 연구의 대세가 된 딥러닝은 2010년대부터 급속도로 성장하게 되는데, 이러한 성장에는 두 가지 배경이 있다. 첫째, GPU(Graphics Processing Unit, 그래픽처리장치)를 비롯한 컴퓨터 시스템의 발전이다. GPU는 본래 컴퓨터의 그래픽을 처리하기 위해 만들어졌다. CPU(Central Processing Unit, 중앙처리장치)와 비교할 때, GPU는 유사하고 반복적인 연산을 병렬로 처리하여 훨씬 속도가 빠르다. 2010년대에 들어서며, GPU가 CPU의 역할까지 대신할 수 있게 보완한 GPGPU(General-Purpose computing on GPU) 기술이 등장했다. GPU의 쓰임새가 늘어났고, 인공신경망의 학습에도 적용되며 딥러닝의 발전이 크게 가속화되었다. 방대한 학습 데이터를 분석해 특성을 추출하는 딥러닝은 반복적인 계산이 필수인데, GPU의 병렬 계산 구조는 이에 아주 적합했기 때문이다.
두 번째는 데이터(Data)의 증가다. 인공신경망 학습에는 대량의 데이터가 필요하다. 과거의 데이터는 컴퓨터에 입력된 정보 수준에 그쳤다. 하지만 1990년대 이후, 인터넷이 보급되고 검색엔진이 발전하며, 가공할 수 있는 데이터의 범위가 기하급수적으로 늘어났다. 2000년대 이후에는 스마트폰과 사물인터넷(Internet of Things, IoT)이 발전하며 빅데이터(Big Data)의 개념이 등장한다. 현실 세계의 곳곳에서 셀 수 없이 많은 데이터가 실시간으로 수집되는 것이다. 많은 데이터를 학습한 딥러닝 알고리즘은 더욱 정교하게 구축된다. 데이터 패러다임의 변화는 딥러닝 기술 발전의 큰 기반이 되었다.
▲ 2016년 3월 9일 진행된 알파고와 이세돌의 대국을 그린 다큐멘터리 영화 ‘AlphaGo – The Movie’ (Google DeepMind)
그리고 2016년, 딥러닝은 또 한 번 세상을 바꾼다. 구글 딥마인드가 개발한 AI 알파고(AlphaGo)가 4승 1패로 바둑기사 이세돌 9단을 꺾으며 승리, 전 세계에 AI의 존재를 각인한 것이다. 알파고는 딥러닝 알고리즘과 강화학습*, 몬테카를로 트리 탐색* 알고리즘을 결합해 탄생했다. 이를 통해 수만 번의 자가 대국을 진행하여 스스로 학습하고, 인간의 직관을 모방하여 수를 예측하고 전략까지 세울 수 있었다. ‘인간을 꺾은 AI’의 탄생은 본격적인 AI 시대의 시작을 알린 신호탄이었다.
* 강화학습(Reinforcement Learning): AI가 행동을 학습하는 방식 중 하나. 행동에 따른 결과를 보상의 형태로 알려주면서, 주어진 상태에서 최적의 행동을 선택하는 전략을 찾게 한다.
* 몬테카를로 트리 탐색(Monte Carlo tree search, MCTS): 일련의 난수를 반복적으로 생성하여 함수의 값을 수리적으로 근사하는 확률적 알고리즘의 일종. 현 상황에서 선택 가능한 행동들을 탐색 트리로 구조화하고, 무작위적 시뮬레이션을 통해 각 행동의 득실을 추론하여 최적의 행동을 결정하는 기능을 한다.
챗GPT를 필두로 시작된 ‘생성형 AI’ 붐

▲ 생성형 AI 개념도
2022년 말, 인류는 AI 기술로 거대한 변혁을 맞이했다. 오픈AI가 LLM(거대 언어 모델)* GPT(Generative Pre-trained Transformer) 3.5를 탑재한 ‘챗 GPT’를 출시하면서 생성형 AI(Generative AI)의 시대를 연 것이다. 생성형 AI는 인간의 고유 영역으로만 여겨지던 ‘창작’의 영역에 침투하여 다양한 포맷의 수준 높은 콘텐츠를 생성한다. 데이터를 바탕으로 예측하거나 분류하는 딥러닝의 수준을 넘어 사용자의 요구에 따라 LLM이나 다양한 이미지 생성 모형(예: VAE, GAN, Diffusion Model 등)을 활용해 스스로 결과물을 생성하는 것이 특징이다.
* LLM(Large Language Model, 거대 언어 모델): 방대한 양의 데이터를 통해 얻은 지식을 기반으로 다양한 자연어 처리 작업을 수행하는 딥러닝 알고리즘
생성형 AI의 시작은 2014년 이안 굿펠로우(Ian Goodfellow)가 발표한 ‘GANs(Generative Adversarial Networks, 생성적 적대 신경망)’ 모델이다. GANs는 두 신경망이 서로 경쟁하면서 학습하는 구조다. 한 신경망은 실제 데이터와 구분하기 어려운 새로운 데이터를 생성하고 다른 신경망은 이를 실제 데이터와 비교하여 판별하는데, 이 과정을 반복하며 점점 더 정교한 데이터를 완성한다. GANs 모델은 이후 변형과 개선을 통해 현재까지 이미지 생성 및 변환 등 다양한 응용 분야에서 활발하게 사용되고 있다.
2017년에는 자연어처리(Natural Language Processing, NLP) 모델 ‘트랜스포머(Transformer)’가 발표된다. 트랜스포머는 데이터 간의 관계를 중요 변수로 고려한다. 특정 정보에 더 많은 ‘주의’를 기울여 데이터 사이의 복잡한 관계와 패턴까지 학습할 수 있으며, 더 중요한 정보를 포착해 이를 기반으로 더 나은 품질의 결과물을 생성할 수 있다. 트랜스포머 모델은 언어 이해, 기계 번역, 대화형 시스템 등의 자연어 처리 작업에 혁신을 가져왔다. 특히, 앞서 언급했던 GPT 등의 LLM의 출현에 크게 영향을 미쳤다.
2018년 처음 출시된 GPT는 매년 더 많은 매개변수와 학습 데이터를 사용해, 빠른 속도로 성능을 개선해 왔다. 그리고 2022년, GPT-3.5를 탑재한 대화형 인공지능 시스템 챗GPT가 출시됐고, AI의 패러다임을 완전히 바꿔놓았다. 챗GPT는 사용자와의 대화에서 맥락을 잘 이해하고 적절한 반응을 제시할 수 있으며, 답변할 수 있는 영역 또한 광범위했다. 출시 일주일 만에 사용자 수 100만 명을 돌파했으며 두 달 만에 활성 이용자 수 1억 명을 넘기는 등 전세계적으로 폭발적인 인기를 끌었다.
2023년, 오픈 AI는 기술적으로 한 단계 도약한 GPT-4를 출시했다. GPT-4는 GPT-3.5보다 약 500배 더 큰 데이터 셋을 활용한 모델로, 텍스트를 넘어 이미지와 오디오, 비디오 등 다양한 입력 데이터를 동시에 처리하며, 데이터 포맷 역시 다양하게 생성하는 LMM(멀티 모달 모델)*으로 진화했다. 챗GPT가 촉발한 생성형 AI 붐을 타고, 기업들은 너나 할 것 없이 다양한 생성형 AI 서비스를 출시하고 있다. 텍스트, 이미지, 오디오 등을 동시에 인식하고 이해할 수 있는 구글의 제미나이(Gemini)와 이미지 내 특정 객체를 정확하게 인식하고 분리할 수 있는 메타의 샘(SAM), 텍스트 프롬프트 기반으로 영상을 제작하는 오픈AI의 소라(Sora) 등이 대표적이다.
생성형 AI 시장은 이제 시작이다. 글로벌 시장 조사업체인 IDC(International Data Corporation)의 보고서에 따르면 2024년 생성형 AI 시장은 전년 대비 2.7배나 높은 401억 달러 규모로 성장할 전망이다(AI타임즈, 2023). 또한, 매년 성장을 가속화하여 2027년에는 1,511억 달러 수준으로 성장할 것이라 예측했다. 앞으로 생성형 AI는 소프트웨어를 넘어서 하드웨어, 인터넷 서비스 등 다양한 포맷에 도입될 것이다. 기능은 상향 평준화될 것이며, 더 많은 사람들이 손쉽게 이용할 수 있도록 편의성은 확장될 것이다.
일상을 바꾸는 AI와 미래 전망
AI는 2000년대의 구글 검색, 2010년대의 모바일 SNS처럼 사회 전반에 새로운 변화와 기회를 제공하는 구심점으로 기능하고 있다. 기술의 발전 속도는 비슷한 사례를 찾아보기 힘들 정도로 빠르며, 그 과정에서 인류의 도전과 고민 역시 커지고 있다.
그렇다면 ‘Next 생성형 AI 기술’은 무엇일까? 현재 가장 주목받는 미래 AI 기술은 단연 ‘온디바이스(On-Device) AI’다. 일반적으로 AI 서비스를 이용하기 위해서는 대규모 클라우드 서버와 통신하여 엣지 디바이스로 데이터를 끌어와야 한다. 하지만 온디바이스는 휴대폰, PC 등의 전자기기에 AI 칩셋과 sLLM(Smaller LLM)을 설치해서 자체적으로 AI 서비스를 구동할 수 있다. AI 구동에 따른 보안이나 자원 문제를 해결할 수 있는 대안이며 동시에 더욱 개인화된 AI 서비스까지 제공할 수 있다.
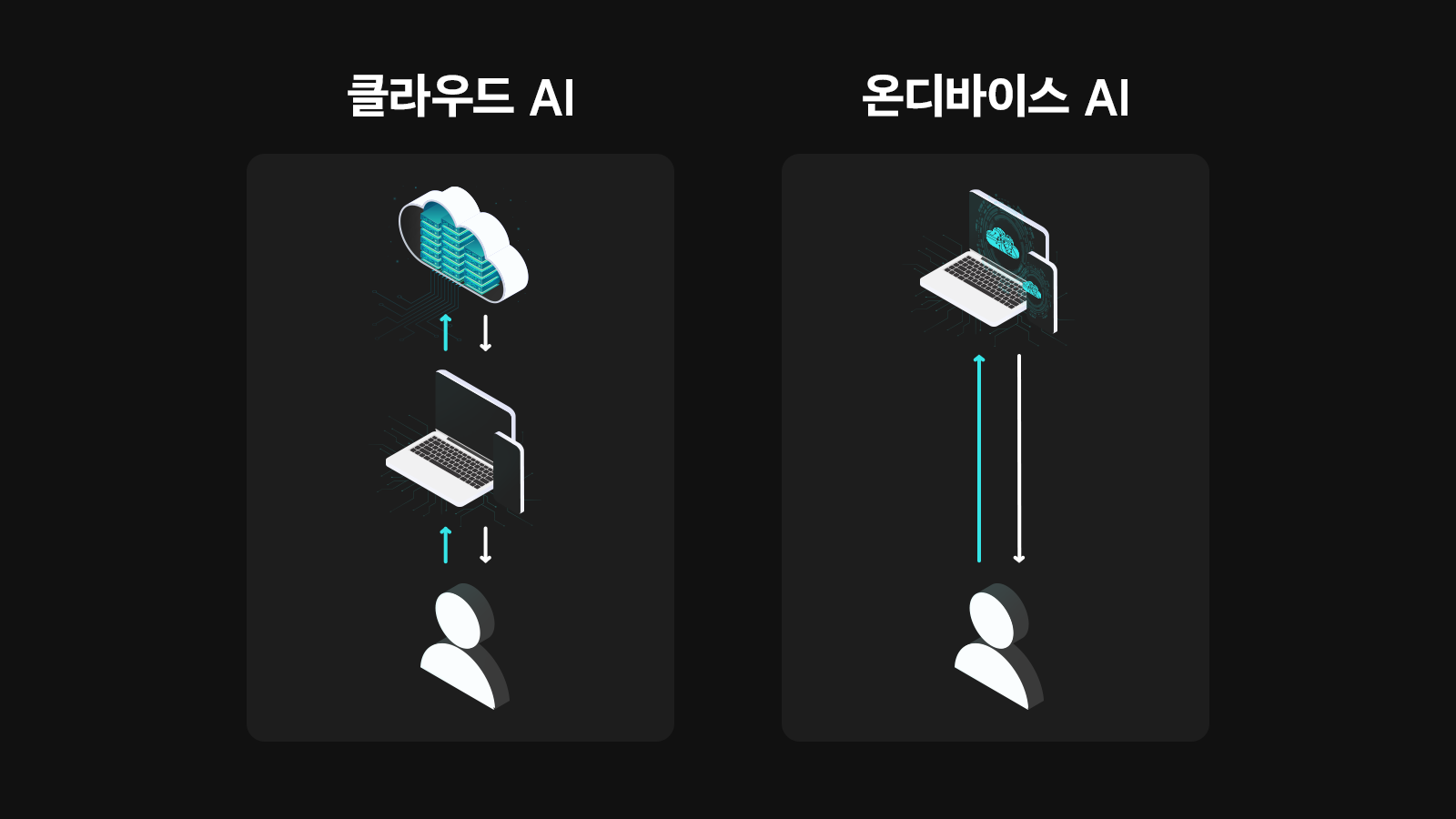
▲ 클라우드 기반 AI와 온디바이스 AI 구조 비교
온디바이스 AI와 같이, 앞으로 AI는 더 많은 기기에 탑재될 것이며 그 형태는 계속해서 진화할 것이다. 이미 영화에서나 볼 수 있었던 혁신적인 아이템이 시장에 출시됐다. 2023년 미국 AI 스타트업 휴메인(Hamane)이 출시한 AI Pin은 사용자의 손바닥에 메뉴를 투영하는 레이저 잉크 디스플레이를 탑재한 웨어러블 AI 디바이스다. CES 2024에서 소개되며 화제를 모았던 래빗(Rabbit)의 R1, 브릴리언트 랩스(Brilliant Labs) Frame 역시 AI 기술을 탑재한 혁신적인 웨어러블 디바이스다. 또한, 애플의 비전 프로(Vision Pro), 메타의 퀘스트(Quest)와 같이 AI 기술을 적용한 혼합현실(Mixed Reality, MR) 헤드셋은 기존의 가상현실(Virtual Reality, VR) 과 메타버스를 넘어선 새로운 시장을 창조하고 있다.
빠른 기술 발전은 새로운 기회를 만들어내지만, 동시에 사회적 문제를 야기하기도 한다. AI 기술의 빠른 발전 속도를 따라가지 못하는 사회 전반에서 여러 가지 우려의 목소리가 나오기 시작했다. 특히, 상상 속에서만 존재하던 AI가 실체를 가지고 현실 공간으로 들어오며, 이를 악용한 사례들이 등장했다. AI가 만들어낸 정교한 허위 콘텐츠는 가짜 뉴스를 양산하며 사회적 혼란을 조장한다. 최근 미국 대선 등 대형 선거를 앞둔 여러 국가들을 중심으로 가짜 영상, 이미지 등의 딥페이크(Deepfake) 콘텐츠에 대한 우려가 커지고 있는 상황이다.

▲ 생성형 AI가 묘사한 딥페이크 기술로 인한 사회적 불안과 혼란(DALL·E)
AI 개발 및 활용 과정에서 발생할 수 있는 위험 요소도 존재한다. 생성형 AI가 사전 학습을 위해 웹상에 공개된 자료들을 크롤링하고, 재조합하는 과정에서 수많은 창작물이 표절의 대상이 될 수 있다는 점이다. 또한, 동일한 생성형 AI 프로그램과 비슷한 프롬프트로 생성한 콘텐츠 간의 저작권 다툼 우려도 있다. AI가 사람들의 업무 진행에 도움을 주고 생산성을 높이는 것을 넘어 일자리를 대체하고 노동시장 구조의 변화를 본격화할 것이라는 전망도 마냥 반가운 이야기만은 아니다.
이제 AI가 만드는 세상은 이제 인류의 상상력을 넘어섰다. 한 번도 경험하지 못한 세상이 너무 빠르게 다가오고 있다. 우리는 예상치 못한 미래의 변혁을 어떻게 대비해야 할까? 이에 대한 올바른 대처 방안을 수립하기 위해서는 AI에 대한 깊은 이해와 분석을 바탕으로 보다 구체적인 고민과 사회적 논의가 필요하다.
※ 본 칼럼은 반도체/ICT에 관한 인사이트를 제공하는 외부 전문가 칼럼으로, SK하이닉스의 공식 입장과는 다를 수 있습니다.



