‘역사상 가장 거대한 패러다임의 전환’이라 불리는 인공지능(AI)은 눈부신 속도로 일상의 중심으로 다가오고 있다. AI는 이미 인간의 지능과 학습 속도를 추월했고, 일상의 다양한 부분을 학습하며 자율주행(Automotive), AI 비서부터 인간의 뇌를 본뜬 뉴로모픽(Neuromorphic) 반도체1)까지 전 영역에서 빠르게 적용되고 있다. 이러한 AI 기술이 활약하고 있는 대표적인 응용 분야는 무엇이고 어떻게 구현되는 것일까?
1) 뉴로모픽(Neuromorphic) 반도체: 사람 뇌의 신경구조를 모방한 반도체 소자로서, 뉴로는 신경, 모픽은 형상을 의미한다. 병렬로 작용하는 인간의 뇌를 모방해 병렬 형태의 연산구조를 지니고 있다.
Cloud Computing vs Edge Computing
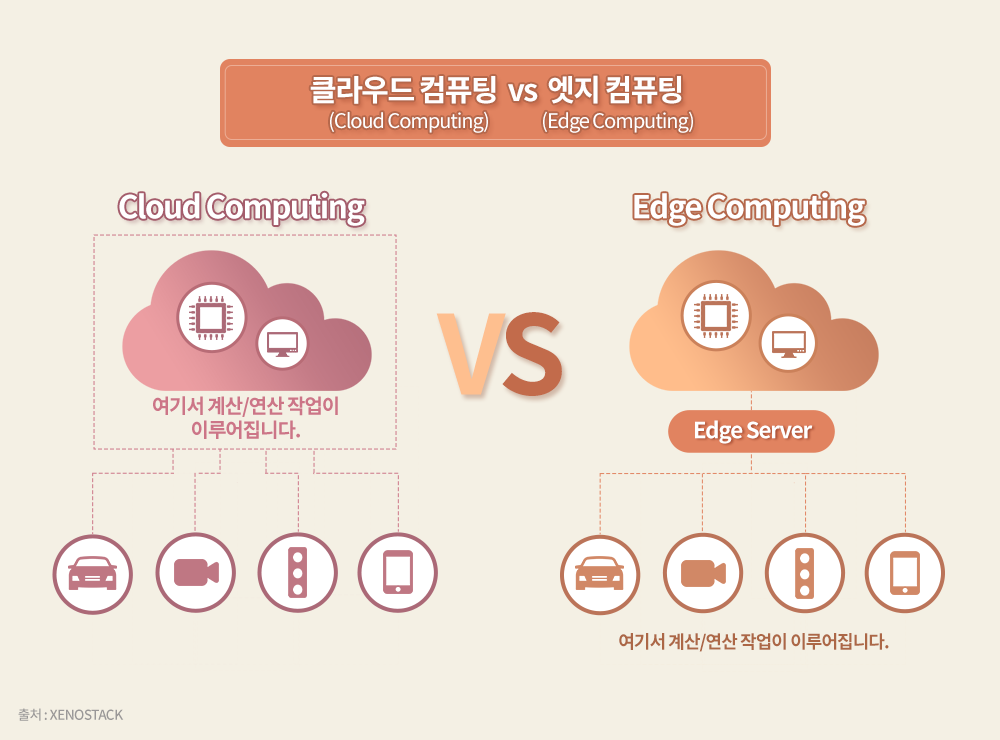
기존 클라우드 서비스(Cloud Service)와 대척점에 있는 AI 응용 분야는 엣지 컴퓨팅(Edge Computing)2)이다. 영상이나 사진과 같은 대량의 입력 데이터를 처리해야 하는 응용 분야에서는 엣지 컴퓨팅을 통해 데이터를 자체적으로 처리하거나, 데이터의 양을 줄여 유무선 통신을 통해 클라우드 서비스로 전달하는 방식을 취해야 한다.
엣지 컴퓨팅을 위한 가속기는 AI 칩 설계의 또 다른 큰 분야를 차지하고 있다. 주로 자율주행 등에 사용되는 AI 칩이 좋은 예다. 이러한 칩에서는 합성곱 신경망3)(Convolution Neural Net, CNN)을 통해 대량의 정보를 지닌 이미지를 압축하고, 여러 처리 과정을 거쳐 영상 분류(Image Classification)4), 객체 탐지(Object Detection)5)등의 작업을 수행하게 된다. 이렇게 입력 데이터가 필터를 거치며 크기가 줄어들면 확실한 특징만 남게 되는데, 이를 통해 최적의 인식 결과를 얻을 수 있다.
2) 엣지 컴퓨팅(Edge Computing): 생성된 데이터를 중앙의 대규모 서버로 전송하지 않고 데이터가 생성된 기기 자체에서 처리하거나 데이터가 발생한 곳과 가까운 소규모 서버로 전송해 처리하는 컴퓨팅 방식을 말한다.
3) 합성곱 신경망(Convolution Neural Net): 행렬로 표현된 필터 각 요소가 데이터 처리에 적합하게 자동으로 학습되도록 하는 기법을 말한다.
4) 영상 분류(Image Classification): 이미지나 영상 속 대상이 어떤 범주에 속하는지 구분하는 작업을 말한다.
5) 객체 탐지(Object Detection): 이미지나 동영상에서 의미 있는 객체(object)의 위치를 정확하게 찾아내는 작업을 말한다.
AI와 개인정보보호

▲Amazon Alexa(왼쪽)와 SK텔레콤 NUGU(오른쪽)
아마존(Amazon)의 ‘알렉사(Alexa)’, SK텔레콤의 ‘NUGU’ 등 대화형 서비스 역시 AI 응용 분야 중 하나로 꼽힌다. 하지만 마이크 입력을 통해 집안의 대화가 끊임없이 노출되는 방식을 사용하는 지금의 대화형 서비스는 단순한 오락용 서비스 이상으로 발전되기 힘들다. 더 다양한 응용 분야에서 활용하기 위해서는 먼저 개인정보보호 문제를 해결해야 하며, 서비스 제공 기업들 역시 이를 인지하고 문제 해결을 위해 노력을 경주하고 있다.
개인정보보호 문제 해결 방안으로 최근 주목받고 있는 기술은 ‘동형 암호화(Homomorphic Encryption)’다. 동형 암호화는 사용자의 음성 또는 의료 데이터와 같은 민감 정보들을 있는 그대로 전송하지 않고, 사용자만이 풀 수 있는 암호문(Ciphertext)으로 변환해 전송하는 기술이다. 데이터를 처리할 때도 암호화된 상태로 곱셈, 덧셈 등 필요한 연산이 이뤄지며, 그 결과를 다시 사용자에게 암호화된 상태로 보내면 사용자가 이를 해독(Decrypt)해 결과를 확인한다. 따라서 사용자 이외에는 아무도 암호화 이전의 데이터를 알 수 없다.
이 같은 기술을 구현하려면 일반적인 데이터를 처리하는 심층 신경망(Deep Neural Network, DNN) 서비스에 비해 적게는 수천 배, 많게는 수만 배에 달하는 계산량이 필요하다. 이에 따라 특별히 설계한 동형 가속기(Homomorphic Accelerator)로 연산 성능을 획기적으로 높여 서비스 시간을 줄이는 것이 앞으로의 주요한 연구 과제가 될 것이다.
AI 칩과 메모리 반도체
대규모 DNN에서는 가중치(Weight)6)의 수가 늘어 프로세서 내부에 모든 가중치를 담을 수 없다. 이에 외부의 대용량 DRAM에 저장된 가중치를 필요할 때마다 읽어와 프로세서로 가져와야 한다.
이때 가져온 가중치를 한 번만 쓰고 다시 쓰지 못하면, 에너지와 시간을 소모하며 애써 가지고 온 정보가 재활용되지 못하고 버려지게 된다. 모든 가중치가 프로세서 안에 저장돼 활용되는 경우와 비교할 때, 많은 시간과 에너지가 추가로 소모돼 극히 비효율적이다.
따라서 대규모 DNN에서 막대한 수의 가중치를 활용해 많은 양의 데이터를 처리해야 하는 경우에는 병렬 처리와 함께/혹은 한 번에 같은 가중치를 여러 번 사용하는 배치(Batch)7) 방식을 활용해야 한다. 즉, DRAM이 장착된 프로세서를 여러 개 병렬로 구성하고 이를 서로 연결한 뒤, 가중치나 중간 데이터를 여러 개의 DRAM에 분산 저장하고 재사용하는 방식으로 연산을 수행해야 한다는 의미다. 이런 구조에서는 프로세서 간 고속 연결이 필수적이다. 이런 방식은 모든 프로세서가 하나의 통로를 통해 연결되는 방식에 비해 더 효율적이며, 최대의 성능을 끌어낼 수 있다.
6) 가중치(Weight): 평균치를 산출할 때 각 개별값에 부여되는 중요도를 말한다.
7) 배치(Batch): 처리해야 할 데이터를 일정 기간 모았다가 한 번에 처리하는 데이터 처리 방식을 말한다.
AI 칩의 연결구조
프로세서들을 상호 접속(Interconnection)8) 형태로 대량으로 연결할 때 문제가 되는 것은 대역폭(Bandwidth)과 지연시간(Latency)이다. N개의 가속기(Accelerator)를 병렬로 연결해 N배의 성능을 내고 싶어도, 상호 접속된 연결부의 대역폭에는 한계가 있어 지연시간이 발생하고, 이로 인해 기대한 만큼의 성능을 얻지 못하기 때문이다. 이에 DNN의 크기와 성능은 대역폭과 지연시간을 바탕으로 결정된다.
이러한 성능의 확장성(Scalability)을 효율적으로 제공하기 위해서는 각 프로세서 사이의 연결 구조가 중요하다.

▲NVIDIA’s GPU Accelerator A100
NVIDIA A100 GPU에서는 ‘NVLink 3.0’이 그 역할을 담당하고 있다. 이 GPU칩에는 12개의 NVLink 채널이 있고 각각 50GBps9)의 대역폭을 제공한다. 4개의 GPU를 서로 연결하는 경우 각 GPU당 4개 채널을 사용해 직접 연결할 수 있지만, 16개를 연결하는 경우에는 외부에 상호 연결을 전담하는 NVSwitch를 사용해야 한다.
Google TPU v2는 496GBps의 총 대역폭(Aggregate Bandwidth)10)을 가진 ICI(Inter-Core Interconnect)11)를 활용해, 2D Torus12) 구조로 서로 연결할 수 있도록 설계돼 있다.
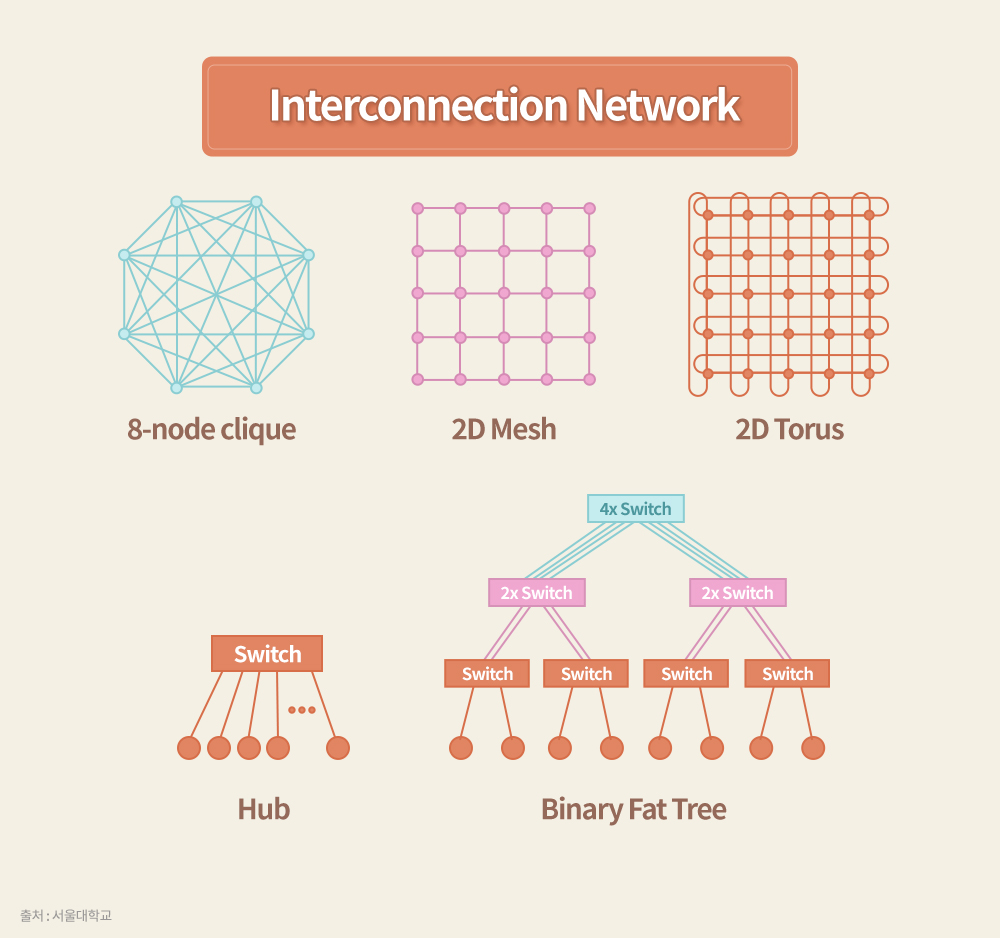
이렇듯 각 프로세서를 연결하는 방법은 전체 시스템에 큰 영향을 미친다. 예를 들어 메시(Mesh)13) 나 Torus 구조로 연결하게 되면 각 칩 간의 물리적 연결이 단순해 구성이 쉽지만, 멀리 연결된 노드(Node)14)를 여러 프로세서를 거쳐 연결해야 해 그 거리만큼 지연시간이 증가한다.
가장 극단적인 해결책은 모든 프로세서를 1:1로 연결하는 클리크(Clique) 구조를 채택하는 것이다. 하지만 칩의 핀(Pin)15) 수가 프로세서 개수만큼 급격하게 증가하고 인쇄회로기판(Printed Circuit Board, PCB) 상의 정체(Congestion)가 허용할 수 없는 범위를 넘어, 실제 설계에서는 최대 4개의 프로세서밖에 연결할 수 없다.
이로 인해 일반적으로는 NVSwitch와 같은 크로스바 스위치(Crossbar Switch)16)를 이용하는 매력적인 방법이 활용된다. 하지만 이 역시 스위치에 모든 연결이 수렴돼, 연결하려는 프로세서가 많으면 스위치에 신호선이 몰려 PCB 상의 레이아웃을 잡기가 어려워진다.
가장 좋은 방법은 전체 네트워크를 2진 트리(Binary Tree)17)로 구성하는 방법이다. 이 경우 최말단에 프로세서를 연결하고 최상단에 가장 많은 대역폭을 할당해야 하므로, 팻 트리(Fat Tree)18) 형태로 구성하는 것이 확장성과 함께 최고의 성능을 발휘하기에 가장 이상적이다.
8) 상호 접속(Interconnection): 병렬 처리를 위한 컴퓨터 구조에서 복수 개의 프로세서와 기억 장치 모듈 간에 데이터 및 제어 신호를 전달하기 위한 연결 구조를 말한다.
9) GBps: 초당 얼마나 많은 데이터를 전송할 수 있는지를 나타내는 단위. 1GBps는 1초에 대략 10억 bit의 데이터를 전송할 수 있음을 의미한다.
10) 총 대역폭(Aggregate Bandwidth): 여러 개의 통신 채널이 병렬로 연결될 때 개별 채널들의 대역폭을 다 합한 것을 가리킨다.
11) ICI(Inter-Core Interconnect): 코어 간 연결선을 가리킨다.
12) 2D Torus: 행과 열의 노드들은 기본적으로 그물망 구조로 연결되며 같은 행과 열의 노드들은 별도의 링으로 한 번 더 접속한다.
13) 메시(Mesh): 노드들을 2차원 배열로 연결하여 각 노드가 4개의 주변 노드들과 직접 연결되는 그물망 구조를 말한다.
14)노드(Node): 네트워크상 연결점 또는 종점을 뜻한다.
15) 핀(Pin): 부품과 부품을 고정하는 기계요소를 말한다.
16) 크로스바 스위치(Crossbar Switch): 세로 및 가로로 교차하는 여러 개의 신호선의 교차점에서 접점을 여닫으며 접속 여부를 결정하도록 하는 스위치를 말한다.
17) 2진 트리(Binary Tree): 하나의 노드에 두 개의 노드가 연결되고 연결된 노드에 계속 두 개씩 노드가 연결되며 아래로 확장되는 크리스마스트리 형태의 연결 구조를 말한다.
18) 팻 트리(Fat Tree): 모든 층위가 연결된 노드 수에 상관없이 동일한 대역폭을 가진 형태의 2진 트리 구조. 이러한 조건을 만족하려면 노드 수가 적은 최상단의 연결부에 할당된 대역폭을 최하단으로 내려갈수록 노드 수만큼 나눠 배분해야 한다.
뉴로모픽 방식의 AI 칩
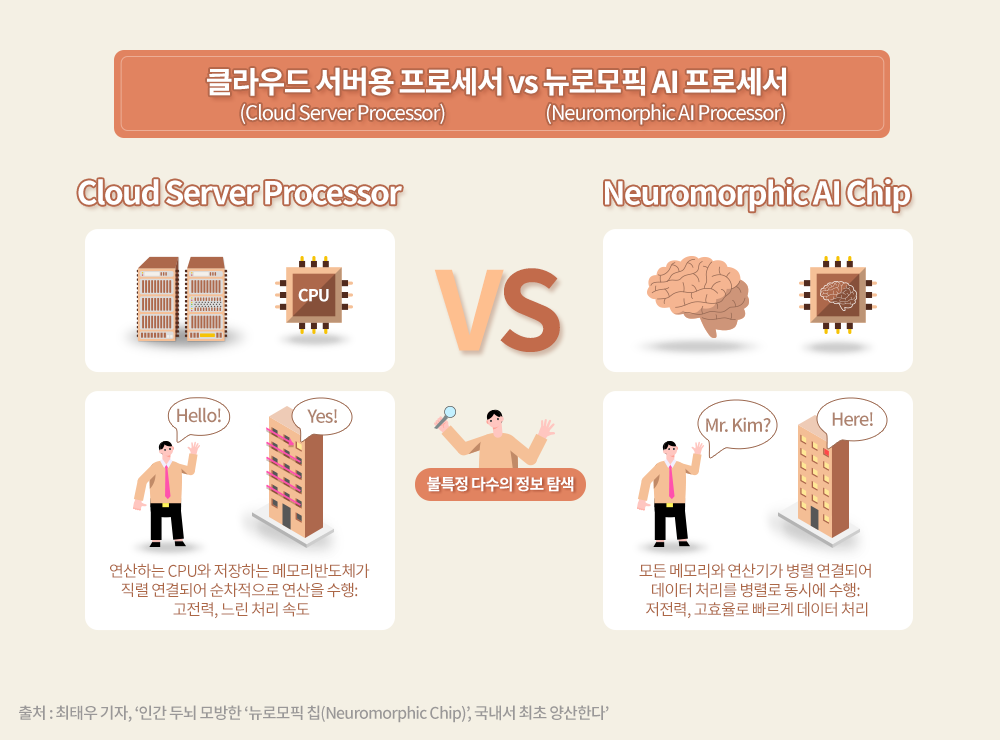
DNN을 가속하는 클라우드 서버용 프로세서는 모든 데이터의 표현과 처리 방식이 디지털로 이뤄져 있으며, 연산은 하드웨어의 바탕 위에서 소프트웨어로 시뮬레이션하는 방식으로 진행된다. 최근에는 이러한 시뮬레이션 방식과 달리 생명체의 신경망 회로와 그 신호를 그대로 아날로그 전자 회로로 직접 가져와 동일하게 처리하는 뉴로모픽 AI 칩도 활발히 연구되고 있다.
뉴로모픽 방식을 활용하는 실제 응용 분야에서는 원래의 데이터 표현이 아날로그 방식을 따르므로 한 개의 신호는 한 개의 노드에 표현된다. 또한 연결 상태는 소프트웨어로 결정되지 않고 하드웨어로 연결되어 있으며, 가중치는 아날로그 형태의 고정된 상태로 저장되게 된다. 이러한 구조는 매우 적은 에너지로 한 번에 많은 정보를 처리할 수 있다는 장점이 있다.
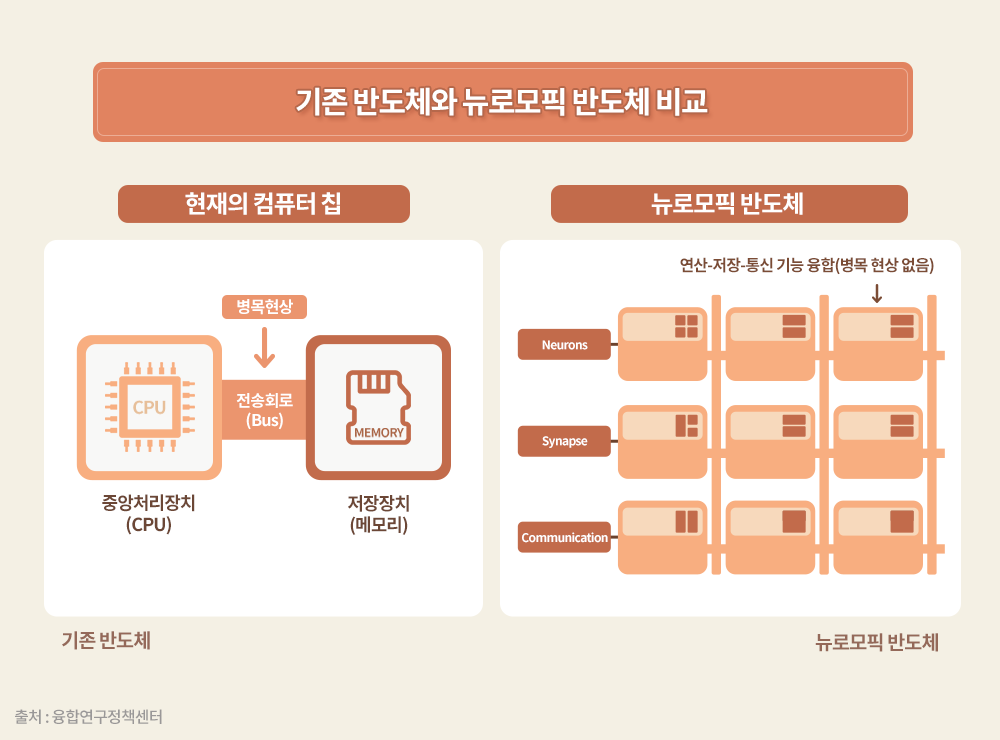
뉴로모픽 AI 칩은 구조가 고정돼 있어 ‘프로그램화할 수 있는 가능성(Programmability)’은 낮지만, 규모가 작은 특정 엣지 응용 분야에서는 장점이 크다. 실제로 뉴로모픽 프로세서는 높은 에너지 효율을 발휘해, 사물인터넷(Internet of Things, IoT)에서 사용하는 센서의 AI 신호 처리나 대량의 영상 입력 데이터를 고정된 가중치의 CNN으로 처리해야 하는 영상 분류와 같은 응용 분야에 유용하다.
하지만 가중치가 고정돼 있어 지속적인 학습이 필요한 응용 분야에는 사용되기 어려울 것으로 예상된다. 또한 구조의 한계로 여러 개의 칩을 동시에 연결하는 병행성(Parallelism)19)을 활용하기도 어렵다. 이에 따라 실제 응용 분야는 엣지 컴퓨팅 분야에 한정될 것으로 전망된다.
뉴로모픽 구조를 IBM의 ‘트루노스(TrueNorth)’와 같이 아날로그 형태가 아닌 디지털 형태로 구현하는 것도 가능하다. 하지만 확장성이 좋지 않은 것으로 알려져 있어 유용한 응용 사례를 찾기는 어렵다.
19) 병행성(Parallelism): 컴퓨터 시스템의 여러 부분이 동시에 작동하거나 여러 컴퓨터 시스템이 동시에 작동하는 것을 의미한다.
AI 칩 기술의 현주소
사용자가 생성하는 막대한 데이터를 처리하는 메타(Meta, 구 페이스북)에서는 인간과 대화할 수 있는 AI 비서를 구현하기 위해 세상에 대한 기본 지식과 상식을 가진 특화된 AI 칩을 설계하고 있다. 또한 페이스북(Facebook)에 게재되는 수많은 영상의 게재 허용 여부를 판정하기 위한 AI 칩도 자체 개발하고 있다.
이커머스(E-commerce)와 클라우드 서비스에 주력하고 있는 아마존에서도 AI 비서 ‘알렉사’ 구현을 위해 ‘인퍼런시아(Inferentia)’라는 AI 가속기를 자체 개발해 사용 중이다. 이 가속기는 음성 신호를 인식하는 목적으로 사용된다. 클라우드 서비스를 제공하는 AWS는 인퍼런시아 칩을 사용하는 기반(Infrastructure)을 갖추고, 구글(Google)의 TPU처럼 클라우드 서비스 사용자에게 딥 러닝 워크로드(Deep-learning Workload)를 가속할 수 있는 기능을 서비스하고 있다.
마이크로소프트(Microsoft)는 현재뿐만 아니라 미래의 응용 분야에도 최적화된 AI 칩을 만들기 위해 FPGA(Field Programmable Gate Array)20)를 데이터 센터에 탑재하고 응용 알고리즘에 따라 그 정밀도(Precision)와 심층 신경망 구조를 재구성(Reconfigure)하는 방식을 시도하고 있다.
하지만 이 방식은 최적의 구조를 찾아냈다 하더라도 그 구조와 논리 회로로 재구성하기 위해 큰 비용이 소요된다. 결과적으로 특정 목적을 위해 특별히 설계된 ASIC(Application Specific Integrated Circuit)21)보다는 에너지와 성능 면에서 크게 불리할 수밖에 없어, 실제 이익이 있을지 확실하지 않다.
또한 한정된 응용 분야에 특화되지 않고 다양한 용도로 사용할 수 있는 가속기를 개발해 엔비디아(NVIDIA)에 대항하려는 여러 팹리스(Fab-less) 스타트업들도 등장하고 있다. 이미 세레브라스(Cerebras Systems), 그래프코어(Graphcore), 그로크(Groq) 등 많은 회사가 시장에서 치열하게 경쟁하고 있다.

▲SK텔레콤의 AI반도체 SAPEON X220
국내에서는 SK하이닉스가 올해 초 SK텔레콤에서 분사한 AI 반도체 전문 기업 사피온(SAPEON)과 협력해 AI 반도체 ‘사피온’을 개발하고, 이를 데이터 센터에 사용할 예정이다. 더 나아가 PIM 기술이 적용된 SK하이닉스의 반도체(GDDR6-AiM)와 ‘사피온’이 결합된 기술도 선보일 계획이다. 또한 퓨리오사 AI(Furiosa AI)에서는 ‘워보이(Warboy)’를 개발해 상업화하고 있다.
이렇게 개발된 인공지능 하드웨어는 구동하는 소프트웨어가 얼마나 최적화돼 있는지에 따라 그 성능이 크게 좌우된다. 수천, 수만 개의 연산 회로를 시스톨릭 배열(Systolic Array)22)을 통해 동시에 구동하고 그 결과를 효율적으로 취합하는 일은 고도의 계산에 따라 조직화(Coordination)하는 과정이 필요한 작업이다. 특히 제작된 AI 칩에 있는 수많은 연산 회로가 쉬지 않고 번갈아 동작하도록 데이터의 공급 순서를 정하고 계산 결과를 다음 단계로 보내는 일은 특화된 저장장치(Library)를 통해 이뤄져야 해, 효율적인 저장장치와 컴파일러(Compiler)23)를 개발하는 것이 하드웨어 설계 못지않게 중요하다.
엔비디아의 GPU도 그래픽 엔진에서 출발했다. 하지만 쿠다(Compute Unified Device Architecture, CUDA)24)라는 개발 환경을 통해 사용자가 쉽게 프로그램을 작성하고 GPU 위에서 효율적으로 작업을 수행할 수 있도록 해, AI 관련 커뮤니티에서 널리 사용될 수 있었다. 또한 구글에서는 자체 TPU를 활용하는 소프트웨어 개발을 돕기 위해 ‘텐서플로(TensorFlow)’라는 개발 환경을 제공하고 사용자가 더 쉽게 TPU를 활용할 수 있도록 지원하고 있다. 앞으로도 이러한 개발 환경이 더욱 다양하게 제공돼야 AI 칩의 활용도가 점점 더 높아질 것이다.
20) FPGA(Field Programmable Gate Array): 회로 변경이 불가능한 일반 반도체와 달리 용도에 맞게 회로를 다시 새겨넣을 수 있어 프로그램이 가능한 비메모리 반도체를 말한다.
21) ASIC(Application Specific Integrated Circuit): 특정 목적으로 설계된 비메모리 반도체를 의미한다.
22) 시스톨릭 배열(Systolic Array): 같은 기능을 가진 셀로 연결망을 구성해 전체적인 동기 신호에 맞춰 하나의 연산을 수행할 수 있도록 설계된 특수한 처리장치를 뜻한다.
23) 컴파일러(Compiler): 고급 언어로 쓰인 프로그램을 컴퓨터에서 즉시 실행될 수 있는 형태의 목적 프로그램으로 변환해주는 프로그램을 가리킨다.
24) 쿠다(Compute Unified Device Architecture, CUDA): 엔비디아에서 개발한 기술로 그래픽 처리 장치(GPU)에서 수행하는 (병렬 처리) 알고리즘을 C 프로그래밍 언어를 비롯한 산업 표준 언어를 사용하여 작성할 수 있도록 하는 GPGPU 기술을 말한다.
AI 칩과 전력소모
앞으로 AI 서비스는 서비스 질의 향상과 함께 전력소모를 절감하는 방향으로 전개될 것이다. 이를 위해 AI 칩 자체의 전력소모를 줄이려는 노력과 더불어 이를 위한 DNN 구조의 개발도 가속될 것으로 예상된다.
실제로 이미지넷(ImageNet)에서 오류(Error) 확률을 5% 이내로 줄이기 위해서는 1019의 부동소수점 연산이 필요하다고 알려져 있으며, 이는 뉴욕 시민이 한 달 동안 사용하는 전력의 양과 같다. 2016년 이세돌 9단과의 대국에 사용된 ‘알파고(AlphaGo)’의 경우 바둑을 두기 위한 인터페이스에 1,202개의 CPU와 176개의 GPU가 사용됐다. 이때 소모한 전력은 약 1MW로 이는 인간 두뇌의 전력 소모량인 20W와 비교하면 엄청나게 큰 차이라 볼 수 있다.
이후 개발된 ‘알파고 제로(AlphaGo Zero)’는 단 4개의 TPU를 사용하는 ‘Re-enforcement Learning’ 기법을 사용해 겨우 72시간의 학습 후 AlphaGo의 성능을 능가했다. 이는 신경망의 구조와 학습 방법에 따라 전력소모를 얼마든지 줄일 수 있음을 보여주는 사례로, 에너지 절약형 DNN 구조를 계속 연구·개발할 필요가 있다.
AI 반도체 시장의 미래
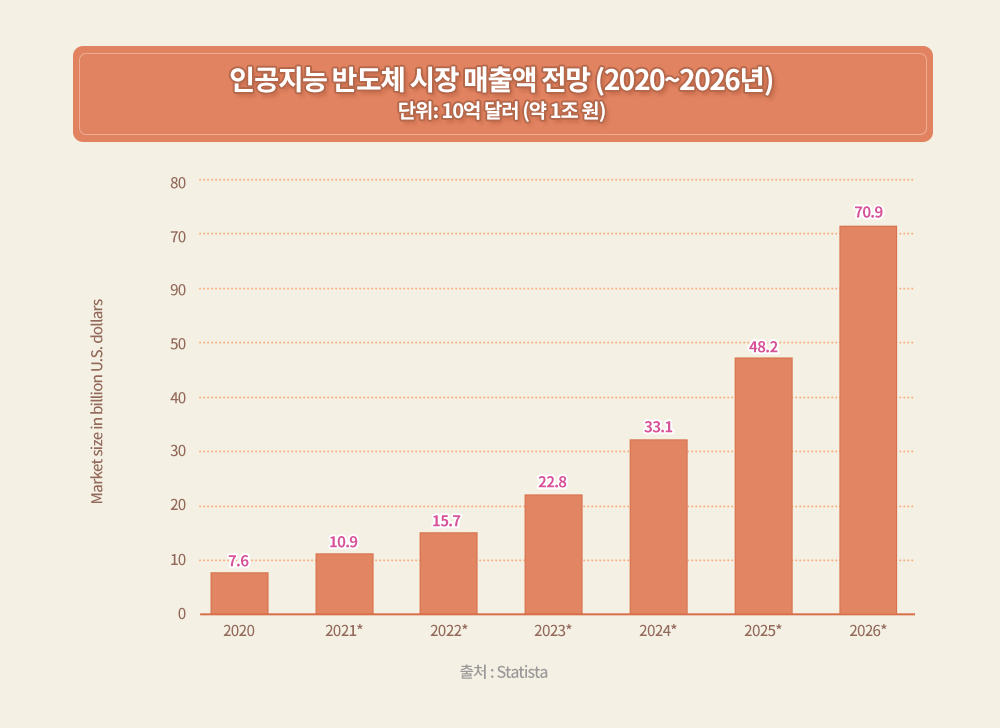
AI의 응용 분야가 확대되고 성과가 나타나면서 관련 시장 규모도 크게 확대될 것으로 전망된다. 일례로 SK하이닉스는 최근 메모리 반도체에 연산 기능을 더해 AI와 빅데이터 처리 분야에서 데이터 접근의 정체 현상을 해결할 수 있는 차세대 지능형 메모리반도체인 PIM(Processing-In-Memory) 개발 소식을 전했다. SK하이닉스는 이러한 PIM이 적용된 첫 제품으로 ‘GDDR6-AiM(Accelerator in Memory)’ 샘플을 선보였고, 지난 2월 말 미국 샌프란시스코에서 열린 반도체 분야 세계 최고 권위 학회인 ‘ISSCC 2022’에서 PIM 개발 성과를 공개했다.

▲SK하이닉스가 개발한 차세대 메모리반도체 PIM이 적용된 ‘GDDR6-AiM’
결국 AI 시장은 응용 시스템이 견인하며 계속 새로운 분야를 창출할 것이다. 또한 신경망 회로 구조에 따른 인터페이스 품질에 의해 서비스 질이 차별화될 것이다. 이러한 AI 시스템의 근간을 이루는 하드웨어인 AI 칩의 경우, 추론과 학습을 얼마나 빠르고, 정확하게, 적은 전력 소모로 구현하는지에 따라 경쟁우위가 결정될 것이다.
지금까지의 연구 결과로는 AI 칩의 전력 효율이 떨어지는 것으로 판명됐다. 따라서 향후 기능의 관점과 더불어 전력 효율의 관점에서도 새로운 신경회로망 구조를 연구할 필요가 있다. 하드웨어 측면에서 전력 효율의 핵심 요소는 메모리 접근 방식을 개선하는 것이다.
이에 따라 앞으로는 메모리 내에서 정보를 처리하는 PIM(Processing-In-Memory)과 시냅스 가중치(Synapse Weight)25)를 아날로그 메모리에 저장해 신경회로망을 뉴로모픽으로 모사하는 방식이 중요한 연구 주제로 다뤄질 것이다.
25) 시냅스 가중치(Synapse Weight): 전기 신호를 인접한 뉴런으로 전달하는 신호 전달 능력을 의미한다.
※ 본 칼럼은 반도체/ICT에 관한 인사이트를 제공하는 외부 전문가 칼럼으로, SK하이닉스의 공식 입장과는 다를 수 있습니다.