20세기 초, 컴퓨터가 발명되면서 인류사에 큰 변화가 생겼다. 과거에는 수많은 사람들이 시간을 써야 했던 각종 문제들을 자동으로 처리할 수 있게 된 것이다. 인간은 컴퓨터에게 프로그램이라는 해야 할 일 덩어리를 던져 주기만 하면 되었다. 컴퓨터는 반도체 기술에 힘입어 이 작업을 매우 정확하고 빠르게 처리할 수 있었다. 이러한 변화는 인간을 삶을 충분히 편리하게 만들었다. 하지만 인간은 거기서 멈추지 않았다. 과학자들이 원한 것은 프로그램이 스스로 주변 환경에 맞춰 변하는 것이었다. 스스로 배워서 변하는 프로그램, 즉 인공지능(Artificial Intelligence, AI)이다.
인공지능을 구현하는 길은 험난했다. 의사결정나무(Decision Tree), SVM(Support Vector Machine)*, 회귀(Regression) 등 인공지능을 만들기 위한 다양한 시도가 있었지만, 원하는 수준의 인공지능을 만들지는 못했다.
* SVM : 데이터의 분류를 위해 기준 선을 정의하는 모델. 데이터가 주어졌을 때, SVM 알고리즘은 기존에 주어진 데이터 집합을 바탕으로 새로운 데이터가 어느 카테고리에 속할지 판단합니다.
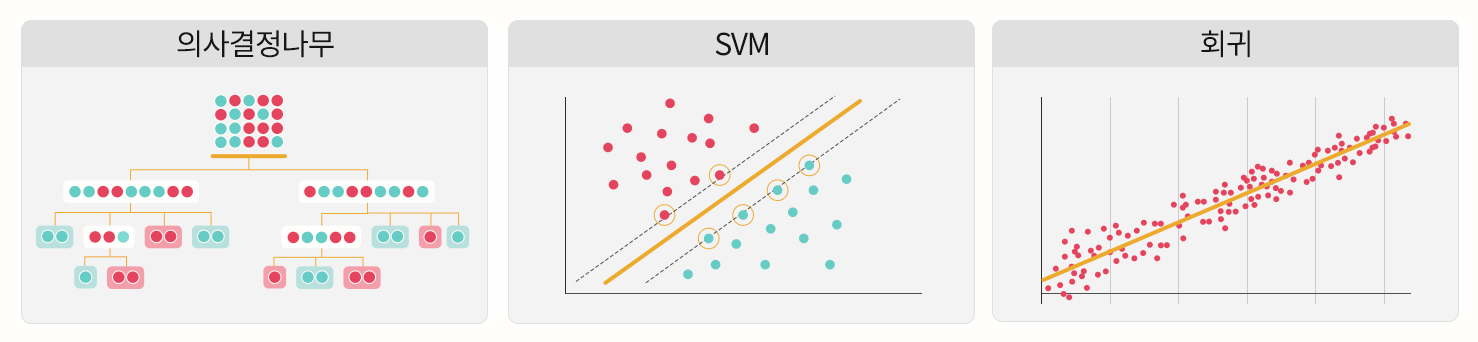
▲ 상기 이미지는 이해를 돕기 위한 참고용 이미지로 실제로는 더 복잡한 구조를 가졌다.
그러던 2012년, 이변이 일어난다. ‘이미지넷(ImageNet)’ 사물 인식 대회에서 ‘알렉스넷(AlexNet)’이라는 인공지능 기반 알고리즘이 우승한 것이다. 알렉스넷은 인간의 뇌세포 구조를 이용해 제작된 인공지능으로, 기존 프로그램이 보여주지 못한 성능을 보여주었다. 이 성공으로 전 세계는 인공지능의 가능성을 깨닫게 되었고, 지금의 인공지능 붐(Boom)에 이르게 됐다.
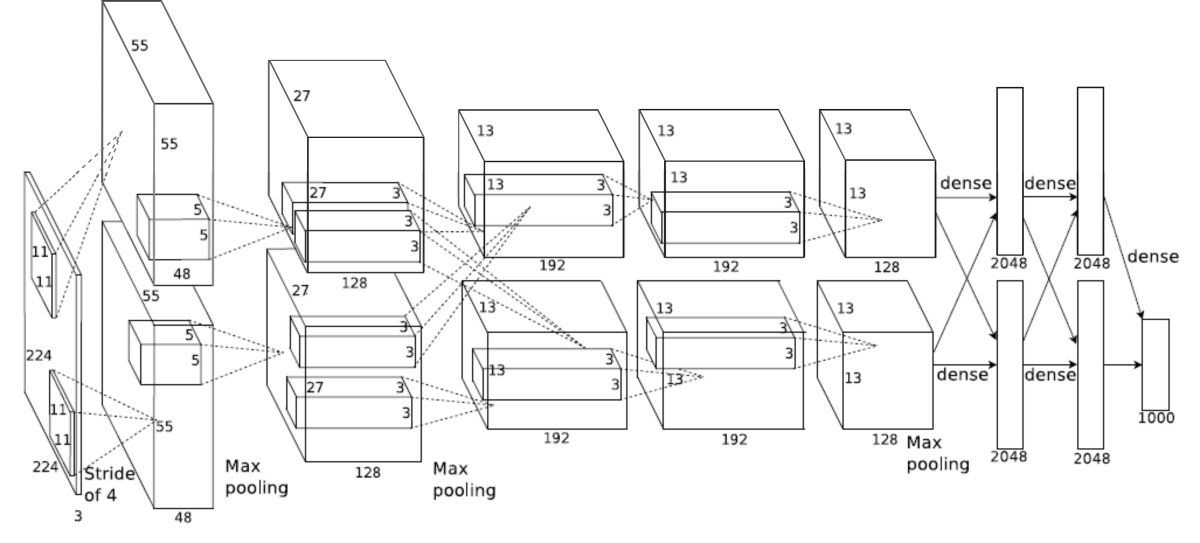
▲ 알렉스넷의 구조도. 병렬적인 구조로 설계되었다는 점이 가장 큰 특징이다.(출처 : 원문 확인)
그런데 뭔가 이상하다. 인공지능을 만들려고 했으면 당연히 ‘인간’ 신경망을 본 뜬, 즉 ‘인공’ 신경망을 제일 먼저 만들어 봐야 했던 것 아닐까? 왜 60년이라는 먼 길을 돌아 이제서야 인공지능이 빛을 보게 된 것일까?
인공신경망, 반도체와 만나다
과학자들도 수십 년간 인간의 신경망을 따라 하려 시도했다. 문제는 인공신경망(Artificial Neural Network, ANN) 관련 이론적 발전이 더디고, 원리상 엄청난 연산 능력이 필요하다는 점이었다.
인공신경망 내에는 인간의 뇌세포에 해당하는 수백만 개에서 최대 수조 개의 값이 필요하다. 인공신경망을 학습시킨다는 것은 이 수많은 신경망 내의 값들을 하나하나 바꿔준다는 의미이다. 문제는 이 조정을 매우 자주 반복해야 한다는 것이다. 학습 1회(배치)마다 최대 수백만~수조개의 값을 바꿔줘야 하는데, 학습 횟수도 수만 회가 넘는 경우가 있다. 이러한 연산 능력 부족 문제는 1980년대까지 해결되지 않은 문제였다. 이 때문에, 2,000년대 이전까지는 당시 CPU 수준에서도 작동 가능한 SVM과 같은 대안 기술에 과학자들이 몰리게 되었다. 하지만 SVM과 같은 기술은 인공지능 기술 발전에 큰 성과를 내지 못했고, 인공지능 전반에 대한 관심이 줄어들었다. 연구비 또한 줄어들면서, 인공지능을 연구하는 사람들은 정부가 전폭적으로 인공지능 연구를 지원하는 캐나다로 이동하게 된다.
연산력 문제가 해결된 것은 2,000년대 후반 인공신경망이 반도체와 만나면서부터다. 특히, GPU(Graphics Processing Unit)가 연산 속도 개선에 중요한 역할을 한다. GPU는 원래 그래픽을 표시하는데 사용된다. 그래픽 연산은 CPU가 수행해야 하는 복잡한 연산들보다는 단순했으나, 대신 유사한 작업을 매우 반복해야 했다. 이런 이유 때문에 GPU는 CPU에 필요한 많은 회로들을 덜어내고, 대신 더 많은 연산 코어를 집적하는 방식으로 발전하였다. 연구자들은 이러한 GPU의 연산 능력이 인공신경망의 연산에 활용될 수 있음을 눈치챘다. 때 마침, GPU 제조사였던 엔비디아는 GPU 기반 프로그래밍을 도와주는 프레임워크 CUDA(Compute Unified Device Architecture)를 제공하고 있었다. CUDA는 GPU의 메모리 모델을 추상화해 좀 더 편하게 GPU를 이용할 수 있도록 도왔고, 과학자들은 GPU를 도입해 인공신경망을 수십 배 빠르게 구동할 수 있게 된 것이다.
▲ 인공신경망은 수백만 개의 인공 연결을 시뮬레이션 해야 한다
메모리 반도체 역시 인공신경망 발전에 큰 역할을 한다. 인공신경망 자체는 GPU에 들어갈 수 없으며, 반드시 메모리에 담아야만 한다. 하지만 인공신경망의 크기는 기존 소프트웨어들보다 거대하다. 게다가 빠른 인공지능 학습을 위해서는 신경망과 가까운 곳에 학습 데이터가 저장되어 있어야 한다. 메모리 반도체 회사들이 인공지능을 위한 고용량, 고대역폭 메모리를 제공했다.
반도체가 인공지능 기술의 동반자로 나선 것이다. GPU는 인공신경망 학습과 구동 속도를 높이고, 메모리 반도체는 더 많은 데이터를 담아 더 큰(깊은) 인공신경망을 만들어 볼 수 있게 된다. 이 같은 환경 변화의 결실이 2012년에 나타난 것이다.
인공지능 기술의 발전은 현재진행형이다
인공지능의 첫 성과 후 10년, 인공지능 기술은 우리 삶 곳곳에 자리 잡았다. 이제는 일상화된 안면 인식, 목소리를 통한 스마트폰 제어, 광학 문자판독(OCR), 실시간 번역 모두 인공지능 기술 덕분에 가능했다. 자율주행 자동차 상용화도 마찬가지다. 인공지능 기술의 발전은 여기에 머무르지 않고 창작의 영역에 도전 중이다. 네이버는 웹툰 자동 채색 서비스를 시범적으로 선보이기도 했으며, 오픈AI(OpenAI)는 인간이 요청한 대로 그림을 그릴 수 있는 인공지능 엔진 DALL-E를 공개했다.

▲ 유저가 요청한 “수프 한 그릇 + 괴물처럼 생긴 + 양털로 짠” 내용에 맞춰 그림을 그려 주는 DALL-E 2 (출처: openai.com/dall-e-2)
이처럼 인공지능이 우리 삶에 깊이 파고들자, 다양한 반도체 분야가 인공지능 산업에 뛰어들었다. GPU는 인공지능 성능 향상의 핵심으로 자리 잡으며, 인공지능 반도체 분야에서의 입지를 더욱 키웠다. 현재, 메모리 반도체 회사들은 HBM(High Bandwidth Memory)과 같이 GPU의 잠재력을 끌어낼 수 있는 고용량 고대역폭 메모리 반도체를 만들고 있다. 엔비디아는 로드맵을 확장하여 감시용 카메라 등 더 작은 기기(Edge device)에 들어갈 인공지능 반도체도 만들기 시작했다. 인텔은 자신들이 점유한 CPU 시장 점유율을 바탕으로 CPU와 GPU의 장점을 결합해 연산력을 높인 단일칩을 출시해 시장에 도전장을 내밀기 시작했다.

▲ 세계 최초로 양산에 돌입한 SK하이닉스의 HBM3
인공지능 반도체에 직접적으로 관련이 없던 회사들의 진출도 시작되었다. 스마트폰 AP 회사들은 NPU(Neural Processing Unit)*라고 부르는 인공지능 연산 전용 부위를 추가해, 영상·이미지·음성 인식 등 스마트폰에 활용되는 인공지능 서비스를 고도화시켰을 뿐 아니라, 이미지 합성, AI 지우개 기능 등 기존 스마트폰에서는 가능하지 않던 재미있는 앱 개발을 가능하게 만들었다. 자동차 회사 테슬라는 자체 연산 칩을 설계하여 반(半)자율주행 알고리즘인 오토파일럿* 기능을 구현하였으며, 인공지능 학습에 사용될 자체 슈퍼컴퓨터 도조(Dojo)까지 만들었다.
* NPU : AI 기반 기술이 스마트폰에 필수적으로 쓰이게 되어 도입된 인공지능 처리 전문 반도체, 혹은 특정 칩에서 인공지능 연산을 담당하는 부분을 지칭하는 용어. 모바일 외에도 음성이나 영상 인식, 스마트 공장, 스마트 빌딩, 스마트 시티 등 다양한 곳에서 사용됩니다.
* 오토파일럿 : 테슬라에서 사용되고 있는 ADAS(Advanced Driver Assistance Systems, 첨단 운전자 지원 시스템) 시스템으로서, 자율주행 5단계인 ‘운전자 없는 자동차를 주행’ 하는 것을 목표로 하고 있습니다. 현재 자율주행 2단계에 속해 테슬라의 주행보조기능을 수행하고 있으며, 사람이 기능이 잘 작동하고 있는지 감시하는 단계의 자율주행 기술입니다.
또 다른 동반자를 찾아
반도체 기술과 인공지능 기술은 선순환의 관계를 가지게 되었다. 반도체의 도움으로 인공지능 기술이 꽃 필 수 있었다. 반도체 산업 역시, 인공지능의 가능성을 알게 된 수많은 플레이어들이 뛰어들며 산업 자체의 파이를 키울 수 있었다.
이러한 선순환 관계는 지속되어야 한다. 현재 인공지능 기술에서의 이슈 중 하나는 전력을 최소화할 수 있는 컴퓨팅을 실현하는 것이다. 이 분야에서도 반도체 회사들의 대결이 뜨겁다. 인텔은 현재의 인공신경망보다 좀 더 인간 신경망에 가까운 SNN(Spiking Neural Network)* 기반의 뉴로모픽 칩을 개발하였으며, 메모리 회사들은 AI 개발 속도는 높이면서 전력 소모를 줄이는 PIM 반도체 개발에 나서고 있다.
* SNN : 인간 두뇌의 생물학적 동적 구조를 모방한 컴퓨팅 기술. 뇌를 구성하는 뉴런(neuron) 과 시냅스(synapse)로 이루어진 신경망 구성방식으로 두뇌에서 정보가 전달, 가공, 출력되는 과정을 인공지능으로 구현하는 방식을 말합니다.
위의 수많은 대안 기술들 중, 혁신가가 어떤 정답을 찾을지는 모른다. 하지만 수많은 경쟁자 사이에서 우리의 반도체가 미래의 혁신가들에게 선택받기 위해서는, 엔비디아와 메모리 회사들이 어떻게 인공지능 연구원들을 도와주었는지 되새길 필요가 있다. 날이 갈수록 반도체를 사용하는 방법은 어려워지고 있다. 따라서 앞으로 반도체의 완성은 사용자가 ‘보고 따라 할 수 있는 매뉴얼과 소통 창구’ 등을 갖추는 것을 포함하게 될지도 모른다. 긴 이야기였지만, 결국 역지사지해야 한다는 이야기이다.
※ 본 칼럼은 반도체/ICT에 관한 인사이트를 제공하는 외부 전문가 칼럼으로, SK하이닉스의 공식 입장과는 다를 수 있습니다.



