우리 삶을 혁신적으로 바꾸고 있는 인공지능(Artificial Intelligence, AI). AI를 알고, 이해하고 또 활용하고 싶은 이들을 위해 에서 AI 기술에 대한 모든 것을 알려드립니다. 앞선 회차에서는 스마트폰과 온디바이스(On-device) AI의 미래에 대해 알아보았습니다. 이번 회차에서는 AI 기술 혁신의 중심에 있는 생성형 AI의 개념과 모델에 관해 살펴보겠습니다.
<시리즈 순서>
① AI의 시작과 발전 과정, 미래 전망
② AI 알고리즘의 기본 개념과 작동 원리
③ 머신러닝의 이해
④ 딥러닝의 이해
⑤ 스마트폰과 온디바이스(on-device) AI의 미래
⑥ 생성형 AI의 개념과 모델
생성형 AI의 개념
생성형 AI는 기존 데이터의 분포를 학습하여 새로운 데이터를 생성하는 기술이다. 여기서 ‘새로운 데이터’란 학습한 데이터와 유사한 속성을 가지면서도 독창적인 결과물을 말한다. 예를 들면, 생성형 AI는 ‘한 마디의 서정적 멜로디’를 학습 데이터 삼아 ‘서정적인 곡’을 만들 수 있고, 배우의 음성을 학습하여 다른 언어로 재현할 수 있다. 이처럼 생성형 AI는 이미지, 음성, 텍스트 등 다양한 분야에서 인간의 창의성을 반영한 콘텐츠를 생성할 수 있다는 점에서 큰 잠재력을 지닌다.
생성형 모델의 학습 방식
![[All Around AI 6편] 생성형 AI의 개념과 모델_그래픽_2024_01](https://skhynix-prd-data.s3.ap-northeast-2.amazonaws.com/wp-content/uploads/2024/11/All-Around-AI-6편-생성형-AI의-개념과-모델_그래픽_2024_01.png)
▲ 판별 모델과 생성 모델의 학습 방식 차이. 왼쪽은 판별 모델이 조건부 확률을 통해 분류하는 방식을, 오른쪽은 생성 모델이 데이터 자체의 확률 분포를 학습하는 방식을 보여준다.
생성형 AI 모델(Generative Model)의 특징은 판별 AI 모델(Discriminative Model)과의 차이를 통해 더 명확히 이해할 수 있다. 기존 AI 모델(판별 AI 모델)은 학습 데이터를 기반으로 새로운 데이터에 대한 결과를 예측한다. 즉 조건부 분포 ?(?∣?)* 를 학습해 입력한 X가 클래스 Y에 속할 가능성을 계산하는 것이다.
* ?(?∣?): 주어진 X가 있을 때 Y가 발생할 확률
예를 들어, 고양이와 강아지 두 클래스를 분류하는 모델이 있다고 가정해 보자. 이 모델은 학습된 데이터와 라벨(Label) 간의 경계를 학습하여, 입력된 이미지 X가 고양이인지 강아지인지를 확률적으로 출력한다. 그러나 여기서 문제가 발생할 수 있다. 만약 새로운 이미지가 학습 데이터에 없던 원숭이 이미지라면, 이 모델은 여전히 그 이미지를 고양이나 강아지로 분류하려고 할 것이다. 즉 판별 AI 모델은 학습 데이터와 다른 새로운 유형의 데이터에 대해 적절한 출력물을 내지 못할 가능성을 보여준다.
반면, 생성형 AI 모델은 학습 데이터를 바탕으로 데이터 자체의 확률 분포 ?(?)*를 학습하는 데 중점을 둔다. 가령 고양이 이미지를 학습하는 생성형 AI 모델은 고양이 이미지가 가질 수 있는 다양한 특징들(예: 고양이의 생김새, 색상, 자세, 배경 등)에 대한 확률 분포를 학습하는 식이다. 특히 라벨 사용이 필수인 판별 AI 모델과 달리, 생성형 AI 모델은 라벨 없이 데이터 학습이 가능하다. 예를 들어 이미지 데이터를 학습할 때는 이미지 자체만을 사용하고, 언어 모델의 경우 텍스트만으로 학습할 수 있다. 그래서 생성형 AI 모델은 대규모 데이터를 활용한 학습이 가능하다.
* ?(?): 조건 없이 특정 데이터 X가 발생할 확률
생성형 모델은 모든 데이터가 경쟁하며 그 확률을 예측한다. 이 과정에서 학습 데이터와 크게 다르거나 새로운 유형의 데이터를 낮은 확률로 예측하게 되며, 이를 통해 이상치(Outlier) 등을 예측하는 데 사용할 수 있다.
생성형 AI의 원리
생성형 AI는 새로운 데이터를 생성하기 위해, 기존 데이터를 학습하여 데이터의 분포를 파악하는 ‘학습 단계’와 이를 기반으로 새로운 데이터를 생성하는 ‘샘플링 및 생성 단계’를 거친다. 아래에서는 몇 가지 예시를 통해 대표적인 방법을 살펴보고자 한다.
(1) 잠재 변수 모델 (Latent Variable Models)
생성형 AI 모델은 데이터를 생성할 때, ‘잠재 변수’라는 개념을 사용한다. 잠재 변수는 데이터로부터 직접적으로 관찰되지 않지만, 생성형 모델을 통해 학습할 수 있으며, 이 정보를 활용하여 새로운 데이터를 생성할 수 있다. 예를 들어 사진 속 사람의 얼굴을 생성할 때, 그 사람의 눈, 코, 입의 위치와 얼굴 모양을 결정하는 것이 바로 잠재 변수다. 즉, 잠재 변수는 복잡한 데이터 분포를 단순화하고 데이터의 구조를 이해하여 맥락과 스타일을 갖춘 새로운 데이터를 생성하는 데 중요한 역할을 한다. 다음은 잠재 변수를 활용하여 데이터를 생성하는 대표적인 모델이다.
![[All Around AI 6편] 생성형 AI의 개념과 모델_그래픽_2024_02](https://skhynix-prd-data.s3.ap-northeast-2.amazonaws.com/wp-content/uploads/2024/11/All-Around-AI-6편-생성형-AI의-개념과-모델_그래픽_2024_02.png)
▲ 잠재 변수를 활용하는 대표적인 모델들. x는 입력, z는 잠재 변수를 뜻한다(출처: towardsai.net)
1) Generative Adversarial Networks (GANs)
GANs는 생성기(Generator)와 판별기(Discriminator)가 경쟁적으로 학습하여 기존의 데이터와 유사한 새로운 데이터를 생성하는 모델이다. 먼저 생성기는 무작위로 선택된 잠재 변수(z)를 사용해 가짜 데이터를 생성하고, 판별기는 생성기가 만든 가짜 데이터와 실제 데이터를 구별하도록 훈련한다. 이 두 네트워크는 상호 경쟁하며 학습을 진행하고, 그 결과 생성기는 점점 더 실제 데이터와 유사한 데이터를 생성하게 된다.
2) Variational Autoencoders (VAEs)
VAEs는 인코더(Encoder)와 디코더(Decoder)로 구성된 모델이다. 인코더는 고차원의 입력 데이터를 저차원의 잠재 변수(z)로 변환하고, 디코더는 이 잠재 변수를 다시 원래의 고차원 데이터로 복원하여 새로운 데이터를 생성한다. 인코더는 잠재 변수의 평균과 표준 편차를 예측하며, 이를 바탕으로 잠재 변수를 정규 분포에서 샘플링하여 출력한다. 이 과정을 통해 VAEs는 데이터의 저차원 표현을 학습하게 된다.
3) 확산 모델 (Diffusion Model)
확산 모델은 데이터에 노이즈를 추가하고 다시 복원하는 방식으로 새로운 데이터를 생성한다. 이 과정은 순방향 확산(Forward Diffusion)과 역방향 확산(Reverse Diffusion)을 통해 이루어진다. 순방향 확산에서는 데이터를 점진적으로 노이즈화하여, 원래의 입력 데이터(x0)를 완전히 노이즈화된 상태(xT)로 변환한다. 이후 역방향 확산에서 이 노이즈화된 상태를 단계적으로 원래의 입력 데이터와 유사한 새로운 데이터로 복원한다. 이 과정은 여러 번 반복되며 특히 이미지 생성에 유리하다. 최근에는 Latent Diffusion Model(LDM)span style=”color: red;”>*처럼 확산 모델과 VAE를 결합해 고품질의 이미지를 생성하기도 한다.
* Latent Diffusion Model(LDM): 인코더를 통해 실제 픽셀 공간이 아닌 잠재 공간에서 확산 작업을 수행하여, 빠르게 학습 및 이미지를 생성하는 모델

▲ LDM을 기반으로 개발한 Stable Diffusion (출처: stability.ai )
(2) 자기회귀 모델(Autoregressive Model)
자기회귀 모델은 과거에 입력한 데이터를 기반으로 미래의 값을 예측하는 모델이다. 이 모델은 시간 이나 순서에 따라 나열된 시퀀스 데이터 간의 확률적 상관관계를 분석하여 예측을 수행한다. 현재 값이 과거 값에 의존한다고 가정하기 때문에, 날씨나 주가 예측 뿐만 아니라 텍스트 데이터 예측에도 활용될 수 있다. 예를 들어, 여러 영어 문장을 학습한 자기회귀 모델이 ‘I’ 다음에 ‘am’이 자주 오는 패턴을 발견하면, ‘I am’이라는 새로운 시퀀스를 생성할 수 있다.
자기회귀 모델은 고품질의 생성물을 출력하지만, 이전 시퀀스에 의존해 한 단계씩 순차적으로 생성하기 때문에 병렬로 출력물을 생성할 수 없다는 단점이 있다. 그리고 이로 인해 생성 속도가 느릴 수 있다.
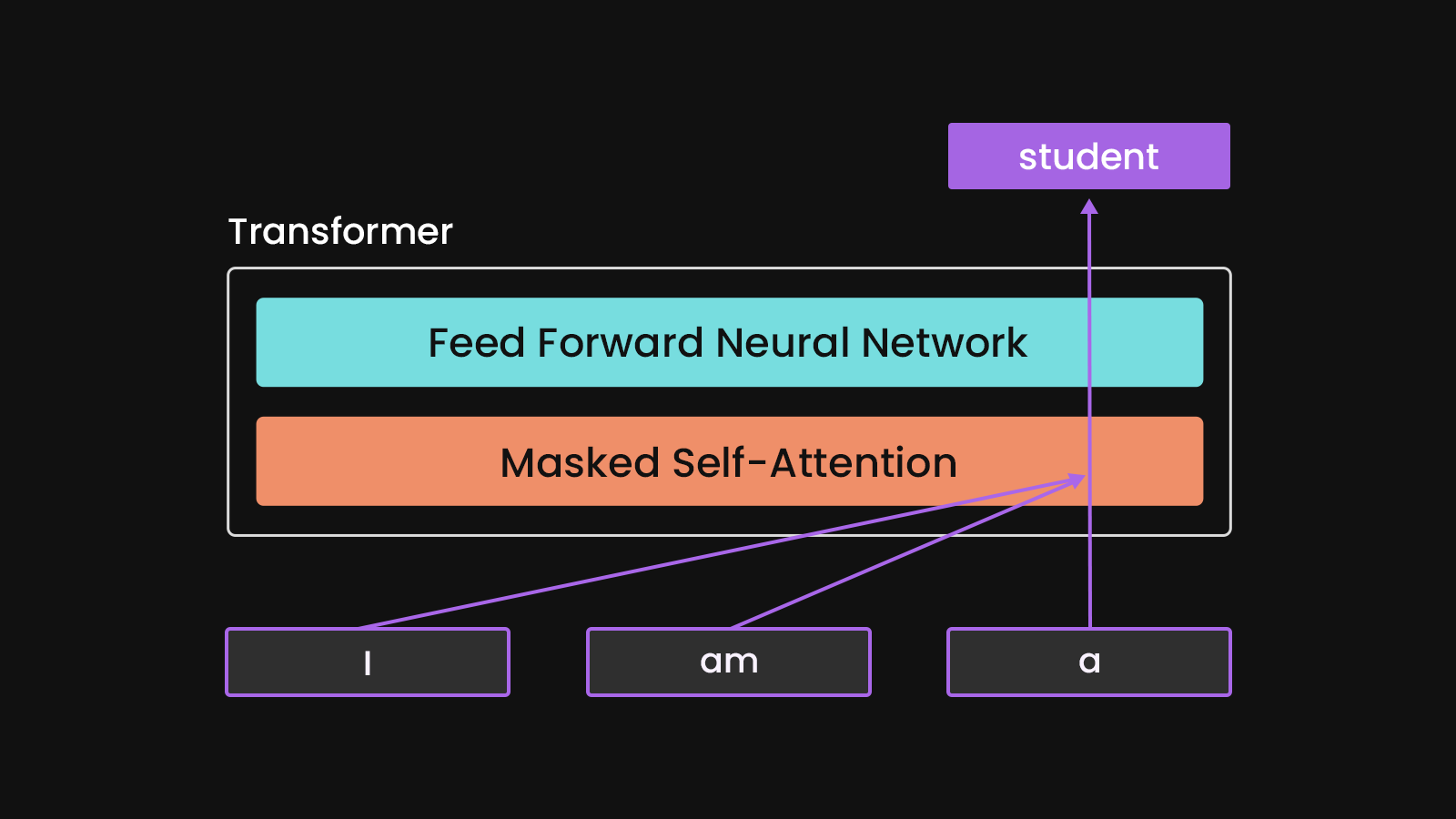
▲ Masked Self-Attention을 이용한 자기회귀 모델 예시. 현재까지 나온 단어 ‘I am a’를 기반으로 다음에 올 단어 ‘student’를 예측한다.
1) 언어 생성을 위한 자기회귀 모델
초기 언어 생성 모델(Language Recurrent Model)은 순환 신경망(Recurrent Neural Network, RNN)을 기반으로 했다. RNN은 텍스트나 음성 같은 시퀀스 데이터를 처리하는 데 적합하며, 이전 단계의 정보를 고려해 현재 단계의 출력을 생성함으로써 데이터 간의 관계를 파악한다. 그러나 RNN 모델은 시퀀스가 길어질수록 성능이 저하되는 장기 의존성(Long-Term Dependency) 문제*를 겪는다. 이를 해결하기 위해 최근에는 트랜스포머(Transformer)*와 같은 Self-Attention* 기법이 사용되고 있다.
* 장기 의존성(Long-Term Dependency) 문제: 시퀀스가 길어질수록 과거의 정보를 점점 잊어버리는 현상. 이로 인해 모델은 긴 시퀀스에서 예측 성능이 저하되는 문제를 겪는다.
* 트랜스포머(Transformer): 자연어 처리 분야에서 처음 제안되어 챗GPT(ChatGPT)를 비롯한 거대 언어 모델(Large Language Model, LLM) 등 최신 AI 모델의 근간이 되는 딥러닝 모델이다.
* Self-Attention: 데이터의 각 요소가 다른 요소들과 얼마나 관련이 있는지를 계산하여, 문맥을 더 잘 이해하고 출력을 생성할 수 있다. 예를 들어 ‘The cat sat on the mat’에서 ‘cat’이 ‘sat’과 얼마나 관련 있는지를 계산해, 문장의 의미를 더 잘 이해하도록 돕는 식이다.
특히, ‘Masked Self-Attention’ 기법을 통해 미래의 시퀀스를 보지 않도록 마스킹을 적용하여, 이전 시퀀스와의 관계만을 파악해 중요한 정보에 가중치를 부여한다. 이를 통해 모델은 과거 정보만을 바탕으로 다음 출력을 생성하게 되며, 긴 시퀀스에서도 중요한 정보를 잃지 않고 처리할 수 있어 정확한 예측이 가능하다. 이 방식은 RNN이 긴 시퀀스를 처리할 때 겪는 장기 의존성 문제를 해결하는 데 효과적이다.
2) 이미지 생성을 위한 자기회귀 모델
이미지 생성 모델인 PixelCNN은 이미지를 순차적으로 한 픽셀씩 생성하며, 각 픽셀은 이전에 생성된 픽셀들에 따라 결정된다. PixelCNN은 합성곱 신경망(Convolutional Neural Network)을 사용하며, Masked Convolution 기법을 통해 현재 생성 중인 픽셀이 이후에 생성될 픽셀에 영향을 주지 않도록 한다. 이는 언어 모델에 사용되는 Masked Self-Attention 기법과 비슷한 원리이다. PixelCNN은 픽셀 간의 복잡한 관계를 잘 포착해 고해상도의 이미지를 생성하는 데 뛰어난 성능을 발휘한다.
최근에는 LlamaGen과 같은 모델이 언어 모델에서 이용되는 트랜스포머를 이용해 이미지 생성 모델을 구현했다. 텍스트의 토크나이저(Tokenizer)* 대신 새로운 이미지 토크나이저를 제시하여 디퓨전(Diffusion) 모델*에 사용되는 VAE 등의 토크나이저보다 더 좋은 품질과 효율적으로 이미지를 생성할 수 있다.
* 토크나이저(Tokenizer): 텍스트를 문장, 단어, 혹은 토큰 단위로 나누는 과정 또는 도구로 자연어 처리(NLP)에서 문맥을 이해하기 위해 필수적으로 사용한다.
* 디퓨전(Diffusion) 모델: 데이터를 점진적으로 노이즈화하고 이를 역과정으로 복원하며 학습하는 생성 모델로 이미지 생성, 복원 등에서 높은 성능을 보인다.
생성형 AI의 데이터
생성형 AI에서 사용하는 데이터는 생성 결과물의 품질을 결정하는 핵심 요소다. 생성형 모델은 웹에서 수집한 대용량 데이터를 사용해 성능을 높일 수 있다. 하지만 웹에서 얻은 데이터는 노이즈나 저작권 등의 위험 요소도 있다. 따라서 데이터의 수집, 정제, 준비 과정에서 신중한 접근이 필요하다.
(1) 데이터의 종류
1) 텍스트 데이터
위키피디아, 뉴스 기사, 문학 작품, 블로그 포스트 등 다양한 형식의 텍스트가 포함된다. GPT 같은 언어 모델은 대규모 텍스트 말뭉치(Corpus)를 학습하여 문법, 어휘, 문장 구조 등 언어의 패턴을 이해하고 학습한다.
2) 이미지 데이터
웹에서 수집된 사진, 그림 등 시각적 데이터를 말한다. 이미지 생성 모델은 대규모 이미지 데이터 세트를 학습하여 이미지의 패턴, 스타일, 구성을 학습한다. 이 외에도 유튜브(YouTube) 등의 플랫폼에서 비디오 데이터를 대량으로 수집하여 비디오 생성 모델을 만드는 데에 사용하기도 한다.
3) 멀티모달(Multi Modal) 데이터
이미지-텍스트 멀티모달 모델을 학습하기 위해서는 이미지와 해당 이미지에 대한 텍스트 데이터를 쌍으로 필요로 한다. 이러한 데이터는 웹에서 수집될 수 있지만, 노이즈가 많을 수 있다. 실제로 웹에서 수집된 데이터의 노이즈를 제거하는 것을 목표로 하는 DataComp Challenge가 NeurIPS*에서 개최된 적이 있다. 이 외에도, 비디오-텍스트 멀티모달 데이터는 유튜브 등의 영상에서 얻어진 내레이션 등이 활용되기도 한다.
* NeurIPS: 인공지능(AI), 기계 학습(ML), 신경 과학 분야의 최신 연구를 다루는 세계적인 학술 대회. 학회에서는 연구 논문 발표 외에도 다양한 워크숍과 챌린지 대회가 열리는데, DataComp Challenge와 같은 대회도 개최되어 실질적인 문제 해결을 위한 연구와 실험이 이루어진다.
(2) 데이터 수집과 정제
생성형 AI 모델의 성능은 데이터 세트의 크기가 커질수록 향상되기 때문에, 데이터를 수집하고 정제하는 방법이 매우 중요하다. 일반적으로 생성형 모델은 웹 크롤링을 통해 초기 데이터를 수집한 후, 필터링과 정제 과정을 거쳐 학습에 적합한 데이터를 확보한다. 이를 통해 고품질의 데이터 세트가 완성되며, 대표적으로 Pile, LAION 등이 있다.
1) Pile 데이터 세트
대규모 언어 모델 학습을 위해 설계된 고품질의 대규모 텍스트 데이터 세트다. Pile 데이터 세트는 최소 825GB(기가바이트)의 텍스트 데이터로 구성되어 있으며, 중복 제거, 에러를 포함한 텍스트 제거, 텍스트 길이를 이용한 필터링 등 전처리 과정을 거친다.
2) LAION 데이터 세트
LAION 데이터 세트는 이미지-텍스트 쌍으로 구성된 공개 데이터 세트로, 생성형 AI와 컴퓨터 비전 분야에서 널리 사용된다. LAION 데이터 세트는 이미지와 텍스트의 유사도, 이미지 해상도, 불안전한 콘텐츠 등을 필터링하여 정제된 데이터를 제공한다.
3) DataComp-1B 데이터 세트
DataComp-1B 데이터 세트는 1억 개의 데이터로 구성된 세트로, LAION 데이터의 노이즈를 제거하기 위해 개발되었다. ImageNet과 유사한 고품질의 이미지를 포함하며, CLIP 모델이라는 기술을 사용해 이미지-텍스트 쌍의 유사도를 평가하는 방식으로 필터링한다. DataComp는 판별 AI 모델에서 성능이 검증되었으며, 생성형 모델에도 긍정적인 영향을 줄 수 있다.
4) Recap-DataComp1B 데이터 세트
기존의 데이터 정제 방식은 주로 노이즈를 제거하는 것에 중점을 두어 고품질의 데이터를 확보하는 데는 한계가 있었다. 최근 제안된 Recap-DataComp1B는 Llama3 모델을 사용해 이미지를 설명하는 새로운 텍스트를 자동으로 생성한다. 즉, AI가 더 정확하게 이미지를 설명하는 고품질의 텍스트를 만들어 기존 데이터를 대체하는 방식이다.

▲ Recap-DataComp1B 데이터 예시. 웹에서 얻은 텍스트(Original) 보다 고품질의 텍스트를 생성하여 좋은 학습 데이터를 만들어 낼 수 있다.
※ 본 칼럼은 반도체/ICT에 관한 인사이트를 제공하는 외부 전문가 칼럼으로, SK하이닉스의 공식 입장과는 다를 수 있습니다.



