AI가 일상이 된 ‘대 AI 시대’, 그 무한한 가능성을 해독하기 위해 SK하이닉스 뉴스룸이 야심 차게 선보이는 [DECODE AI] 시리즈! 각 분야의 최고 전문가들과 함께, 우리 삶 곳곳에 스며든 AI를 샅샅이 파헤칩니다.
6편에서는 AI를 혁신할 미래 반도체 기술, 뉴로모픽 반도체와 AI에 대해 알아보겠습니다. 국내 최고의 뉴로모픽 반도체 전문가, 서울대학교 공과대학 재료공학부 황철성 석좌교수가 알려주는 뉴로모픽 반도체와 AI의 모든 것 지금부터 함께 살펴봅시다.

2016년, 구글의 알파고(AlphaGo)가 바둑을 제패했을 때, 놀라웠지만 그냥 ‘그런 것이 있구나!’ 하는 정도였던 인공지능(Artificial Intelligence, AI)이 이제는 우리의 일상을 바꾸고 있다. 특히 챗GPT로 대변되는 생성형 AI(Generative AI)의 놀라운 발전은 일상생활의 편리를 증대시키는 차원을 넘어 튜링 테스트*를 통과할 일반인공지능*이 머지않아 구현될 것임을 강력하게 시사하고 있다.
* 튜링 테스트(Turing Test): 1950년 앨런 튜링이 제안한 개념으로, 기계가 인간과 구별되지 않는 대화를 할 수 있는지를 평가하는 실험. 인간 심사자가 사람과 기계 중 누가 대화 상대인지 구분하지 못하면, 그 기계는 ‘지능을 가졌다’고 간주한다.
* 일반인공지능(Artificial General Intelligence, AGI): 특정 작업에 국한되지 않고, 인간처럼 다양한 영역의 문제를 이해하고 학습하며 해결할 수 있는 범용 인공지능을 의미한다. 현재 상용화된 AI는 주로 특정 분야에 특화된 AI(ANI)인 반면, AGI는 인간 수준의 지능과 적응력을 목표로 한다.
AI를 위한 위대한 첫걸음, 인공신경망의 등장
오늘날의 AI를 구성하는 신경망에 대한 기본 이론은 이미 1950년대에 제시되었으나 실제로 의미 있는 결과를 얻지 못해 큰 주목을 받지 못했다. 그러나 1980년대 등장한 존 홉필드(John Hopfield) 교수의 홉필드 네트워크*와 이를 변형한 제프리 힌턴(Geoffrey Hinton) 교수의 볼츠만 머신* 덕분에 신경망을 이용한 연산이 다시 관심을 끌게 되었다.
* 홉필드 네트워크(Hopfield Network): 모든 노드가 상호 연결된 완전 연결 신경망으로, 연관 기억을 구현하기 위해 고안된 모델
* 볼츠만 머신(Boltzmann Machine): 제프리 힌턴이 제안한 확률적 신경망 모델, 가시 노드와 은닉 노드가 상호작용하며 에너지 함수를 최소화하는 방향으로 학습하고, 확률 분포를 기반으로 복잡한 패턴을 표현할 수 있다.

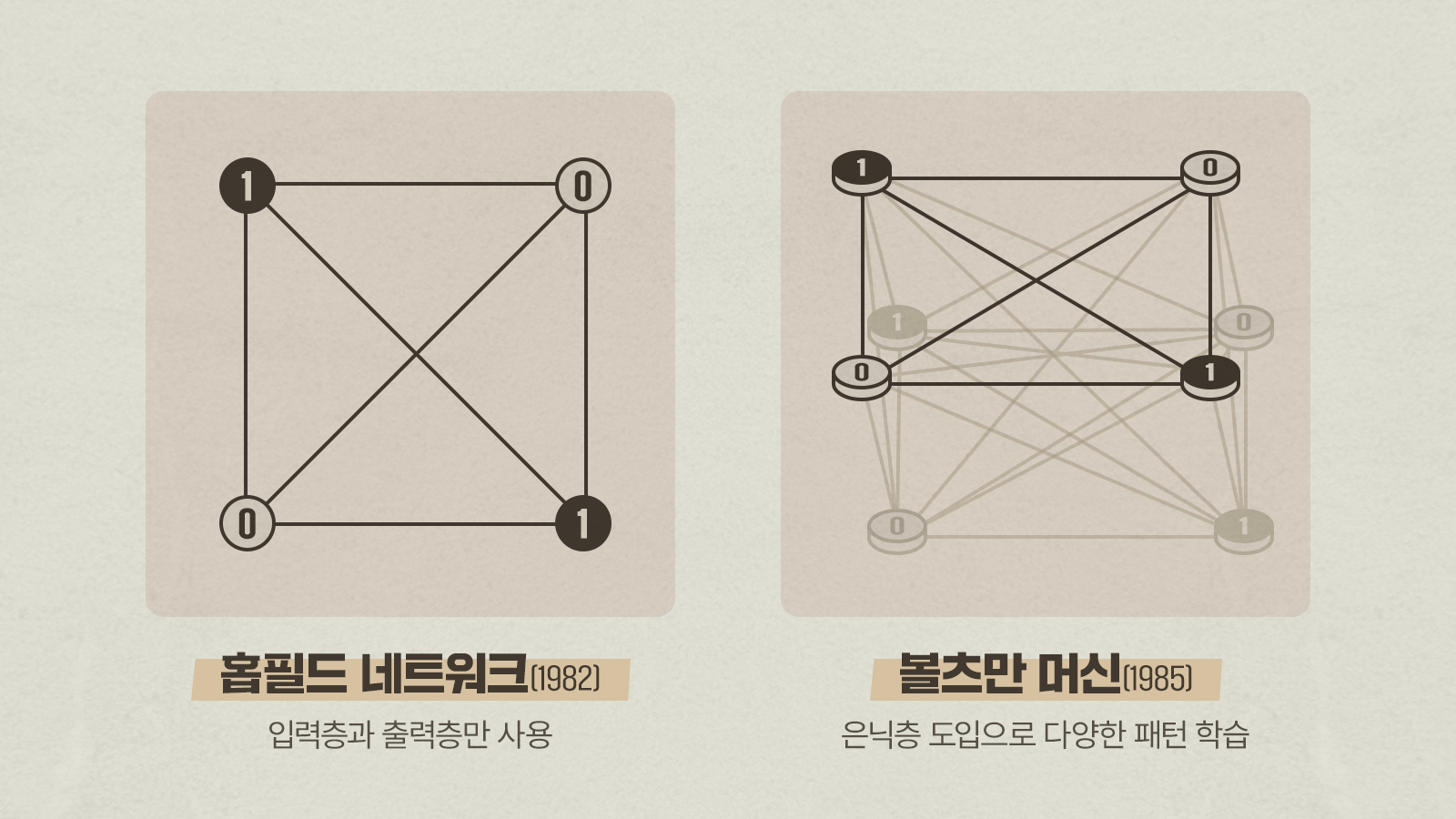
홉필드 네트워크와 볼츠만 머신은 각각 물리학에서 잘 알려진 스핀 상태*에 따른 에너지 이론과 통계역학에 따른 에너지 분포를 응용한 신경망 이론이었으나, 당시의 제한된 연산 능력과 단순한 구조로 인해 이들 역시 의미 있는 규모의 문제를 풀지 못하는 한계가 있었다.
* 스핀 상태(Spin State): 전자가 가지는 고유한 각운동량인 스핀의 방향을 가리키는 개념
심층신경망과 연산 능력이 불러온 혁신
이러한 한계를 극복하기 위해서는 입력층과 출력층 사이에 은닉층을 가지는 심층 신경망 구성의 필요성이 떠올랐다. 그러나 단순한 신경망 구조의 가중치* 계산도 버거운 상황에서 심층 신경망의 가중치 계산을 하는 것은 당시 연산 능력으로는 불가능했으며, 심층 신경망의 가중치 계산을 효율적으로 수행하기 위한 방법론도 부재했다.
* 가중치: 머신러닝에서 가중치는 입력과 다음 뉴런 간의 연결 강도를 나타내는 수치로, 입력이 결과에 미치는 영향을 수치화한 값. 학습 과정에서는 역전파 알고리즘 등을 통해 이 값을 최적화하면서 모델 성능을 개선한다.
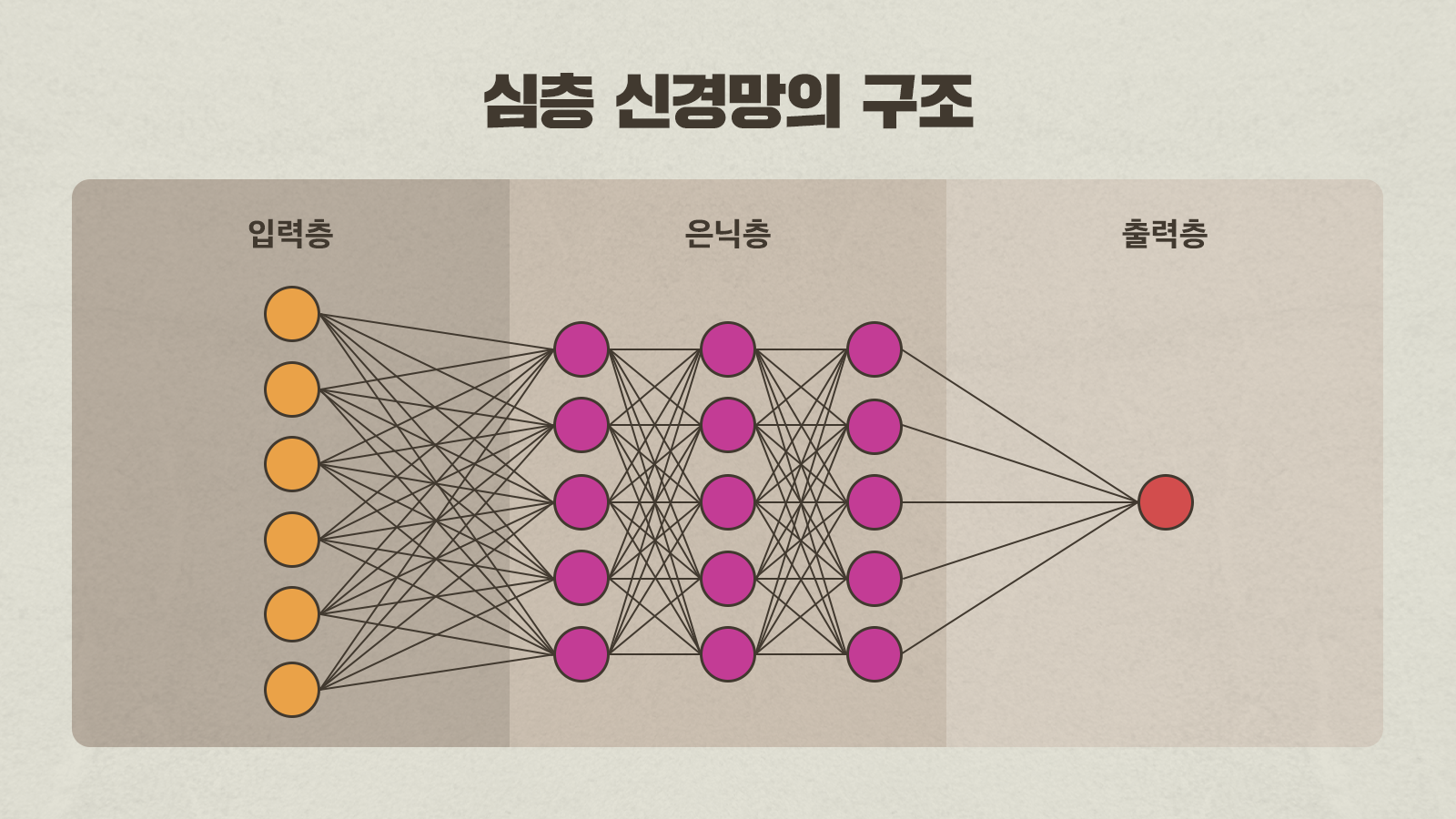
▲ 입력층과 은닉층, 출력층으로 구성된 심층 신경망의 구조
그런데 2010년대에 힌턴 교수 등이 알렉스넷(AlexNet)이라는 이름을 가진 심층 신경망 구조에 역전파* 방식에 기반한 훈련 기법을 적용해 이미지 인식 분야에 혁명을 이루었다. 또한, 꾸준히 발전한 반도체 칩의 성능 향상으로 인해 기존에는 불가능했던 규모의 연산을 비교적 빠른 속도로 수행할 수 있게 됐다.
* 역전파(Back-Propagation): 신경망의 출력 오차를 계산해 이를 입력층 방향으로 거슬러 전파하며 가중치를 수정하는 학습 알고리즘

▲ 노벨 물리학상을 수상하고 있는 존 홉필드 교수(왼쪽)(출처: 노벨 재단)
인류는 지난 70~80년간 하나의 디지털 비트(Digital Bit)의 역전(Flip)*에 필요한 계산 비용을 수조 배 감소시켰다. 홉필드 교수와 힌턴 교수는 이러한 계산 능력의 발전에 힘입어 그들이 제시한 신경망 구조가 실제로 의미 있는 것이었음을 증명했고, 그 결과, 2024년 노벨 물리학상을 받았다.
* 디지털 비트 값이 0에서 1로, 또는 1에서 0으로 변화하는 것
물론 단순히 반도체의 성능 향상만으로 AI가 발전한 것은 아니다. 위에 언급한 이미지 인식 알고리즘은 입력 이미지의 특징을 추출하고 압축한 이후 이를 완전 연결 신경망*에 입력하는 합성곱 신경망*으로 발전하여, 오늘날에는 인간의 인식 능력을 상회하는 결과를 얻고 있다.
* 완전 연결 신경망(Fully-Connected Network, FCN): 한 층의 모든 노드가 다음 층의 모든 노드와 연결된 구조 입력값 전체가 은닉층 전체에 영향을 주기 때문에 강력한 표현력을 가지지만, 기하급수적으로 계산량이 늘어나 메모리 소모가 커지는 단점이 있다.
* 합성곱 신경망(Convolutional Neural Network, CNN): 이미지나 영상 데이터를 학습할 때 주로 사용하는 신경망으로, 공간적 패턴을 추출하는 필터(커널)를 반복 적용해 특징을 학습한다.
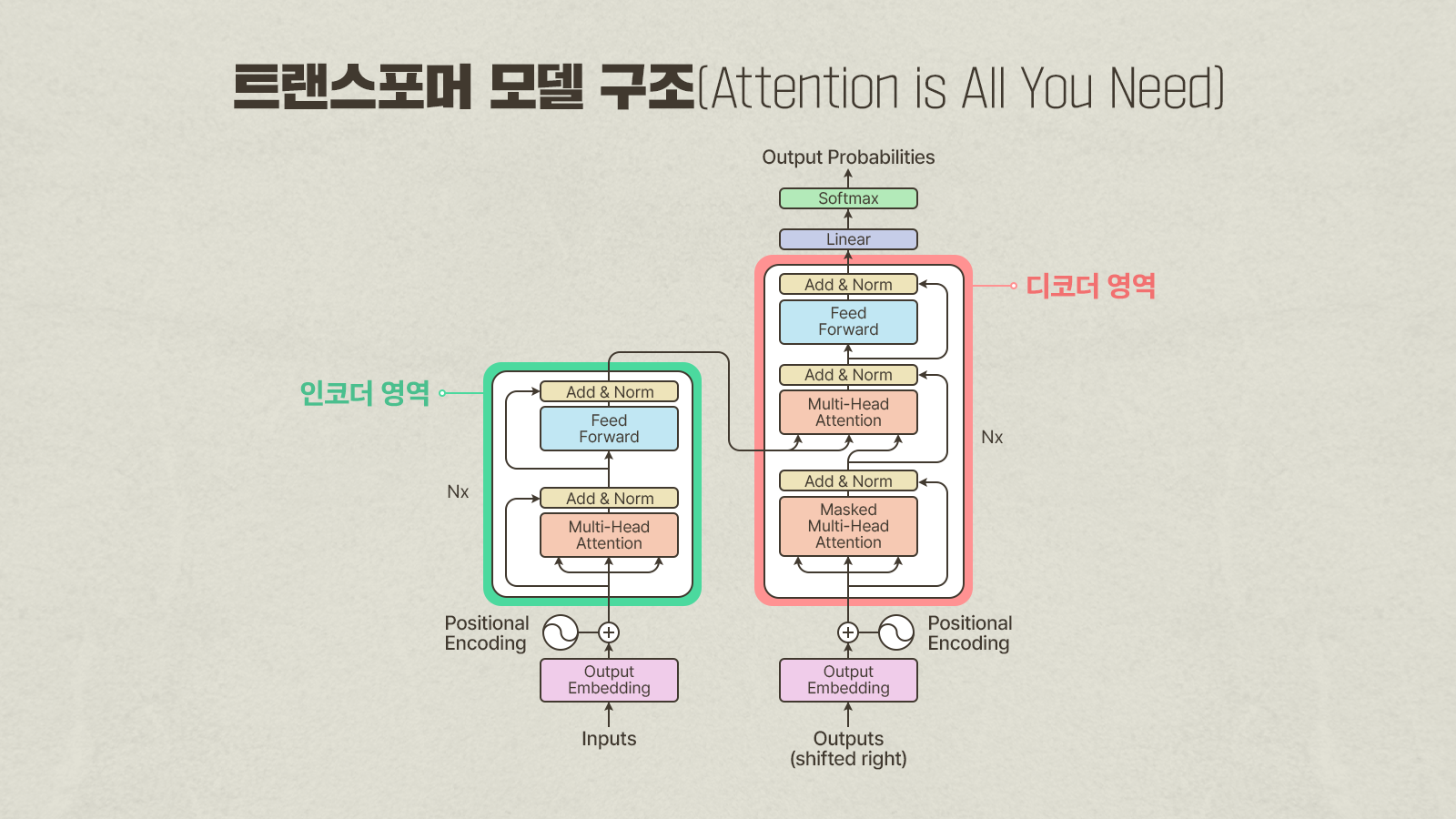
▲ ‘Attention is all you need’ 논문에서 설명하는 트랜스포머 모델 구조
한편, 2017년 구글에서 발표한 논문 ‘Attention is all you need’는 오늘날의 AI 혁명을 유발한 계기가 되었다. 이 논문의 원래 목적은 언어 간 번역 알고리즘과 신경망 구조를 제시하는 것이었다. 언어 번역에서는 주어진 원 문장에 포함된 단어 간의 문맥이 신경망에 반영될 수 있게 하는 것이 중요하다. 이 논문은 이런 관계를 나타낼 방법으로 어텐션 알고리즘*과 이로 이루어진 어텐션 블록*을 제시했고, 어텐션 블록이 FCN으로 반복 연결되는 트랜스포머 구조*를 제시했다.
* 어텐션(Attention) 알고리즘: 입력 데이터 중 중요한 부분에 집중하도록 ‘가중치’를 동적으로 계산해 반영하는 메커니즘
* 어텐션 블록(Attention Block): 트랜스포머의 기본 구성 요소로, 입력 토큰마다 Q, K, V 벡터를 생성하고, 이들 간 유사도에 따라 어텐션 가중치를 계산해 문맥이 반영된 벡터로 변환하는 블록
* 트랜스포머(Transformer) 구조: 인코더-디코더 구조로, 반복이나 합성곱 없이 전적으로 어텐션을 중심으로 설계된 신경망
이후 오픈AI(OpenAI)의 엔지니어들은 웹(Web)상에 존재하는 수많은 텍스트로 트랜스포머를 학습시키면 일반적인 질문에 답을 할 수 있는 거대언어모델(Large Language Model, LLM)이 될 수 있다는 것을 깨닫고 챗GPT를 개발해 냈다.
오늘날 많은 빅테크 기업들이 제공하는 LLM들은 공통적으로 프롬프트 입력을 주면, 이 프롬프트 다음에 올 토큰(말의 단위)을 예측한다. 일견 간단해 보이는 원리이지만 챗GPT-3의 경우 어텐션 블록과 FCN이 96회 반복되는 구조로 되어 있고, 여기에는 총 약 1,750억 개의 가중치가 존재한다.
이 가중치들을 적절한 값으로 조절하는 것이 LLM의 학습 과정이고, 오늘날의 막강한 GPU와 HBM으로 구성된 AI 하드웨어를 이용하더라도 훈련에 수개월이 소요된다. 더욱이 가중치가 많은 신경망일수록 성능이 우수한 경향을 보여 최근에 발표되는 LLM들의 가중치는 수조 개에 달하고 있다.
AI 하드웨어 진화가 만든 새로운 가능성과 한계
이와 같은 신경망 연산기는 전통적인 CPU+메모리(D램) 구조에 기반한 연산기와 큰 차이가 있다. 전통적인 구조에서는 소위 메모리 벽* 또는 폰 노이만 병목현상*이 있어 CPU가 사용할 수 있는 데이터의 제한이 심각하다. 따라서 회로 설계 엔지니어들은 항상 D램 엑세스*를 최소화할 수 있는 방향으로 CPU를 설계해 왔고, 이에 불리언(Boolean) 논리 연산*에 근거한 연산기가 개발되기도 했다.
* 메모리 벽(Memory Wall): CPU의 처리 속도에 비해 메모리의 접근 속도나 대역폭이 크게 뒤처져서, 시스템 성능에 병목을 유발하는 현상
* 폰 노이만 병목현상(Von Neumann bottleneck): CPU와 메모리가 분리되어 있고 데이터를 주고받는 단일 경로(버스)가 제한적이어서 연산 속도에 비해 데이터 전달이 느리게 이루어지는 구조적 병목 현상
* D램 엑세스(Access): CPU가 D램에서 데이터를 읽거나 쓰는 과정
* 불리언 논리 연산(Boolean Logic Operation): 참(True) 또는 거짓(False)만을 대상으로 수행되는 연산으로, 논리합(OR), 논리곱(AND), 부정(NOT) 등이 있다. 프로그래밍 언어 설정, 논리 회로 설계, 데이터 검색 조건 구성 등 여러 분야에서 널리 사용된다.
그런데 LLM과 같이 기계학습(Machine Learning, 머신러닝) 방식에 근거한 신경망은 데이터 자체에 내재하는 규칙을 경험적으로 찾아가는 방식이다 보니 기존 방식과는 비교도 되지 않는 엄청난 규모의 D램 엑세스가 필요했다.


이를 보다 빠르게 처리할 수 있도록 한 것이 바로 HBM이다. HBM은 CPU나 GPU 등 프로세서와의 연결 채널이 수 개 정도인 기존 D램과 달리 수천개 이상(HBM4 기준 2,000여 개)의 연결 채널을 보유하고 있어, 압도적으로 빠른 속도의 D램 엑세스를 가능하게 했다. 신경망 연산은 벡터 행렬 곱*을 병렬적으로 반복하는데, 최신 GPU에는 수만 개에 달하는 VMM 연산 장치가 병렬로 탑재되어 있다. 이 장치들은 여러 개의 HBM과 데이터를 빠르게 주고받으며, 트랜스포머와 같은 복잡한 모델을 효과적으로 수행한다.
* 벡터 행렬 곱(Vector-Matrix Multiplication, VMM): 입력 벡터와 가중치 행렬을 곱하여 출력 벡터를 만드는 딥러닝의 기본 연산, 신경망의 각 레이어에서 반복적으로 수행되며, 전체 연산 속도에 결정적 영향을 미친다.
그런데 일반적인 PC용 CPU 한 대가 대략 100W 대의 전력을 소모하는 데 비해 최신 서버용 GPU는 수 kW 대의 전력을 소비한다. 특히 최신 AI 서버는 연산을 위한 전력 소모뿐 아니라 이에 따라 발생하는 열을 낮추기 위한 냉각에 소모되는 전력도 엄청난 수준이다. 냉각에 사용되는 전력이 연산에 필요한 전력에 버금가는 모순적인 상황도 발생하고 있다.
이와 같은 서버가 수만 대 존재하는 데이터센터의 전력 사용은 지속 가능성이 의심되는 수준으로 증가하고 있고, 아직 AI를 위한 대형 데이터센터가 많지 않은 우리나라의 경우만 해도 현재 국가 전체가 사용하는 총 전력의 약 1~2% 정도를 이미 데이터센터가 소모하고 있다.
이와 같은 방대한 양의 전력 사용 문제의 근원은 인간의 인지를 구현하기 위해 기계학습 방식을 적용하고 있기 때문이라고 할 수 있다. 인간은 역전파나 트랜스포머를 쓰지 않고도 번역 등 적당한 수준의 인지적 행동을 할 수 있는데, AI는 그렇지 못하다. 인간의 인지를 구현하기 위해서 AI 하드웨어는 수많은 데이터를 이동시키고 처리해야 하며, 이러한 과정에서 방대한 양의 전력이 사용되는 것이다.
PIM*은 이러한 문제를 해결하기 위해 메모리 내부에 연산 기능을 일부 통합한 아키텍처다. 그러나 상이한 프로세서와 메모리 공정 등의 문제에 의해 PIM의 성능을 최대한 끌어내려면 상당한 시간이 소요될 것으로 예상된다. 그럼에도 불구하고 PIM은 기존 CPU 등 프로세서로 데이터를 이동시켜 처리하는 연산 중심 컴퓨팅(Computation-Centric Computing)에서 데이터 저장 위치 근처에서 연산을 수행하는 데이터 중심 컴퓨팅(Data-Centric Computing)으로의 패러다임 변환을 보여주는 상징적인 기술이 될 것이다.
* PIM(Processing-In-Memory): 메모리 반도체에 연산 기능을 더해 인공지능(AI)과 빅데이터 처리 분야에서 데이터 이동 정체 문제를 풀 수 있는 차세대 기술
인간의 뇌를 향한 도전, 뉴로모픽과 미래 과제
하지만, 여전히 PIM은 인공신경망을 위한 VMM 연산을 기존에 비해 효율적으로 수행할 뿐, 인간의 뇌 동작과는 거리가 먼 연산 방식이다. 참다운 의미의 인지적 연산기는 기계학습 방식을 탈피한 알고리즘과 하드웨어를 장착한 것으로 볼 수 있다.
▲ 인류는 인간 뇌의 동작을 완벽하게 이해하지 못하기 때문에 완벽한 형태의 뉴로모픽 프로세서를 구현하기란 쉽지 않다.
이를 통상적으로 뉴로모픽 프로세서(Neuromorphic Processor)라고 부른다. 그러나 뉴로모픽 프로세서의 가장 큰 문제는 아직 우리가 인간 뇌의 구조와 동작을 잘 이해하지 못하고 있다는 점에서 기인한다. 이 때문에 어떤 방식으로 뉴로모픽 프로세서를 만들어야 할지 명확한 방향이 존재하지 않는다. 현재 일부 존재하는 뉴로모픽 프로세서는 여전히 CMOS* 기반의 폰노이만 컴퓨팅 구조를 이용해 스파이킹 신경망*을 조금 더 효율적으로 구현하는 정도에 머물러 있다.
* CMOS(Complementary Metal-Oxide-Semiconductor): P형과 N형 모스펫(MOSFET)을 상보적으로 조합한 반도체 공정 기술이자 현대 디지털 및 아날로그 장치에 활용되는 집적회로(IC) 핵심 기술
* 스파이킹 신경망(Spiking Neural Network, SNN): 생물학적 뉴런이 시간에 따라 스파이크를 발생시키는 방식에서 영감을 받은 인공신경망 입력이 특정 임곗값을 넘는 순간 신호를 발생시키며, 이러한 시간 정보를 핵심으로 활용하는 구조가 특징
더욱 발전된 뉴로모픽 프로세서를 구현하려면 기존의 CMOS와 기계학습 방식을 탈피한 새로운 하드웨어와 이를 효과적으로 구동하기 위한 알고리즘 연구가 병행되어야 한다. 이를 위해서는 주어진 데이터를 기계학습 방식보다 더 효과적으로 처리하는 것에서 더 나아가 데이터의 입력 자체를 더 지능적으로 해야 한다.
가령 인간의 눈을 예로 들 수 있다. 눈은 대상의 형태와 이동을 감지하고 이를 뇌에 전달할 때 필요한 정보만을 추출해 보내는 기능을 가지고 있어, 운전 등의 작업에 매우 유용하다. 이에 비해 카메라에 기반한 비전 시스템(Vision System)은 모든 픽셀 정보를 그대로 프로세서로 보내기 때문에 효율적인 운용이 어렵다.

▲ SK하이닉스 등 반도체 기업들은 뉴로모픽 시스템 구현을 위한 연구·개발을 이어가고 있다.
2010년대 이후 이를 실현하기 위하여 멤리스터*를 이용한 연구가 이루어지고 있다. 멤리스터는 전기 신호의 인가 과정에 의하여 소자의 전기적인 상태가 결정되는 특별한 성능을 가져 뉴로모픽 시스템 구현에 적합하다.
* 멤리스터(Memristor): 메모리(Memory)와 레지스터(Resistor)의 합성어로 전하량에 따라 변화하는 유도 자속에 관련된 기억 저항(Memristance) 소자
그러나 멤리스터를 이용한 뉴로모픽 시스템은 아직 상기한 기계학습 방식에 비하여 실용적인 결과에 도달하지는 못하고 있다. 이는 근본적으로 다양한 병렬연결과 계층적 구조, 그리고 복잡하게 얽힌 종합적인 인간 뇌의 정보 전달 체계를 정확히 이해하지 못하고 있는 문제에 기인한다.
또한 오랜 기간 양산에 적합한 공정을 개발시켜 온 실리콘(Si) 기반의 CMOS 공정과 달리 멤리스터는 아직 양산에 적합한 물질과 공정, 그리고 최적의 회로 구조 등이 명확하지 않은 상태에 머물러 있다. 따라서, 인간의 인지 능력과 비슷한 수준의 뉴로모픽 프로세서 개발을 위해선 심리학, 뇌과학, 인지과학, 전자공학, 재료공학 등 다학제적인 연구를 통해 접근해야 한다.



