AI가 일상이 된 ‘대 AI 시대’, 그 무한한 가능성을 해독하기 위해 SK하이닉스 뉴스룸이 야심 차게 선보이는 [DECODE AI] 시리즈! 각 분야의 최고 전문가들과 함께, 우리 삶 곳곳에 스며든 AI를 샅샅이 파헤칩니다.
3편에서는 무병장수의 꿈을 현실로 만들어줄 헬스케어 AI를 알아볼 예정입니다. 국내 최고의 전문가인 ‘서울대학교병원 헬스케어AI 연구원 이형철 부원장’이 소개하는 헬스케어 AI, 지금부터 함께 살펴봅시다.

AI는 이미 우리 일상 속 수많은 분야를 변화시키고 있다. 특히 의료 분야에서 AI의 발전은 환자의 삶은 물론, 의료진의 업무 방식까지 근본적으로 혁신할 가능성을 보여주고 있다.
2016년 알파고의 등장은 전 세계에 큰 충격을 주었고, 이를 계기로 헬스케어 분야에서도 다양한 인공지능(AI) 알고리즘이 본격적으로 개발되기 시작했다. 국내에서는 2024년 말 기준으로 최근 5년간 식품의약품안전처 인증·허가를 받은 의료용 AI 모델이 총 305개*에 달하며, 미국은 2024년 6월까지 950개의 제품이 승인**을 받았다.
* 출처: 2024년 의료기기 허가보고서, 식품의약품안전처 2025.4
** 출처: 글로벌 보건산업동향, 한국보건산업진흥원 2024.9
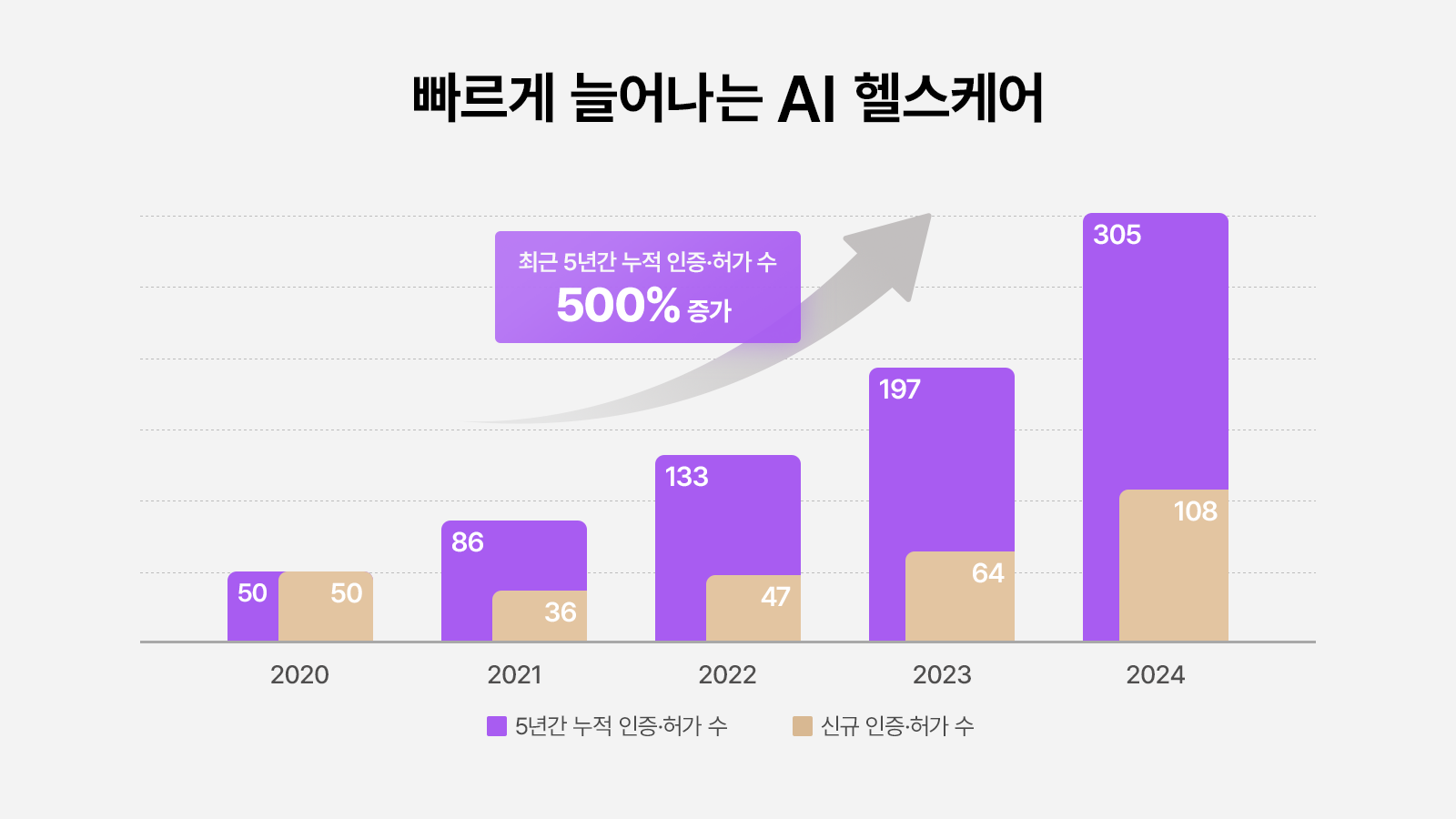
▲ 매년 인증·허가를 받는 의료용 AI 모델이 늘어나고 있다(출처: 식품의약품안전처).
AI, 의료 현장에 스며들다
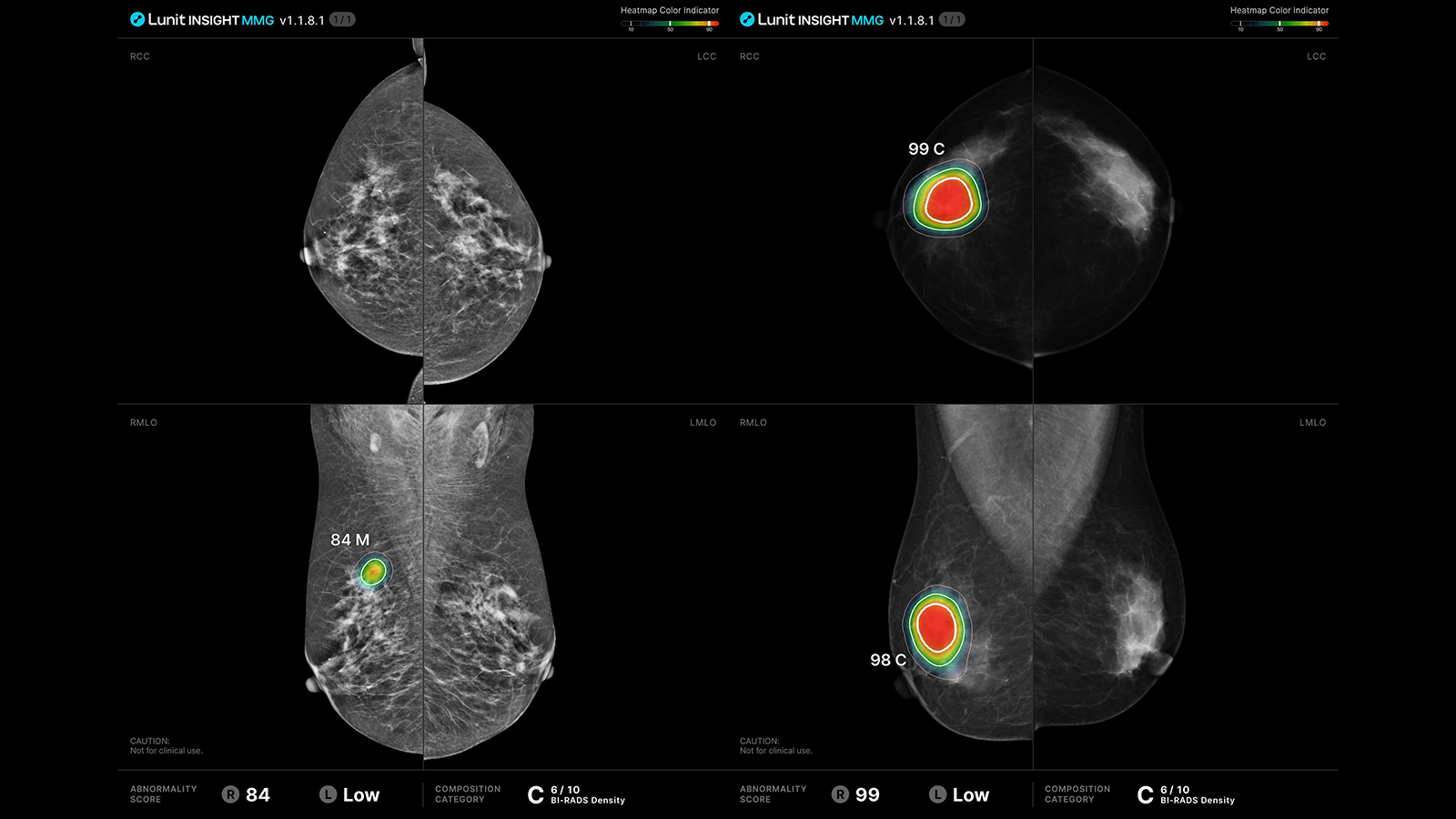
▲ 유방암 진단을 지원하는 루닛의 ‘인사이트(INSIGHT)’(출처: 루닛(Lunit))
그렇다면, 어떤 AI들이 의료계에서 활용되고 있을까? 대표적인 사례로는 루닛(Lunit)의 ‘인사이트(INSIGHT)’와 뷰노(VUNO)의 ‘딥카스(DeepCARS)’가 있다. 루닛 인사이트는 AI 기반 영상 진단 보조 설루션으로, 흉부 엑스레이와 유방촬영술 영상을 분석해 폐질환 및 유방암 진단을 지원한다. 2023년 말 RSNA* 발표에 따르면, 10가지 주요 폐질환에 대해 AUC* 0.83~0.99의 진단 정확도를 보였으며, 이 중 8가지 질환에서는 AUC 0.9 이상의 높은 성능을 기록했다[관련링크]. 현재는 글로벌 기업들의 PACS*에 통합돼 50개국 이상에서 활용되고 있다.
* RSNA(Radiological Society of North America): 북미영상의학회. 세계 최대 규모의 영상의학 학술대회로, 의료 영상 AI 기술의 주요 발표 무대다.
* AUC(Area Under the Curve): 인공지능 모델의 성능을 평가하는 지표로, 1에 가까울수록 정확도가 높음을 의미한다.
* PACS(Picture Archiving and Communication System): 의료 영상 저장 및 전송 시스템으로, 병원 내에서 촬영된 CT, 엑스레이, MRI 등 이미지를 디지털로 관리하고 공유할 수 있게 해주는 플랫폼
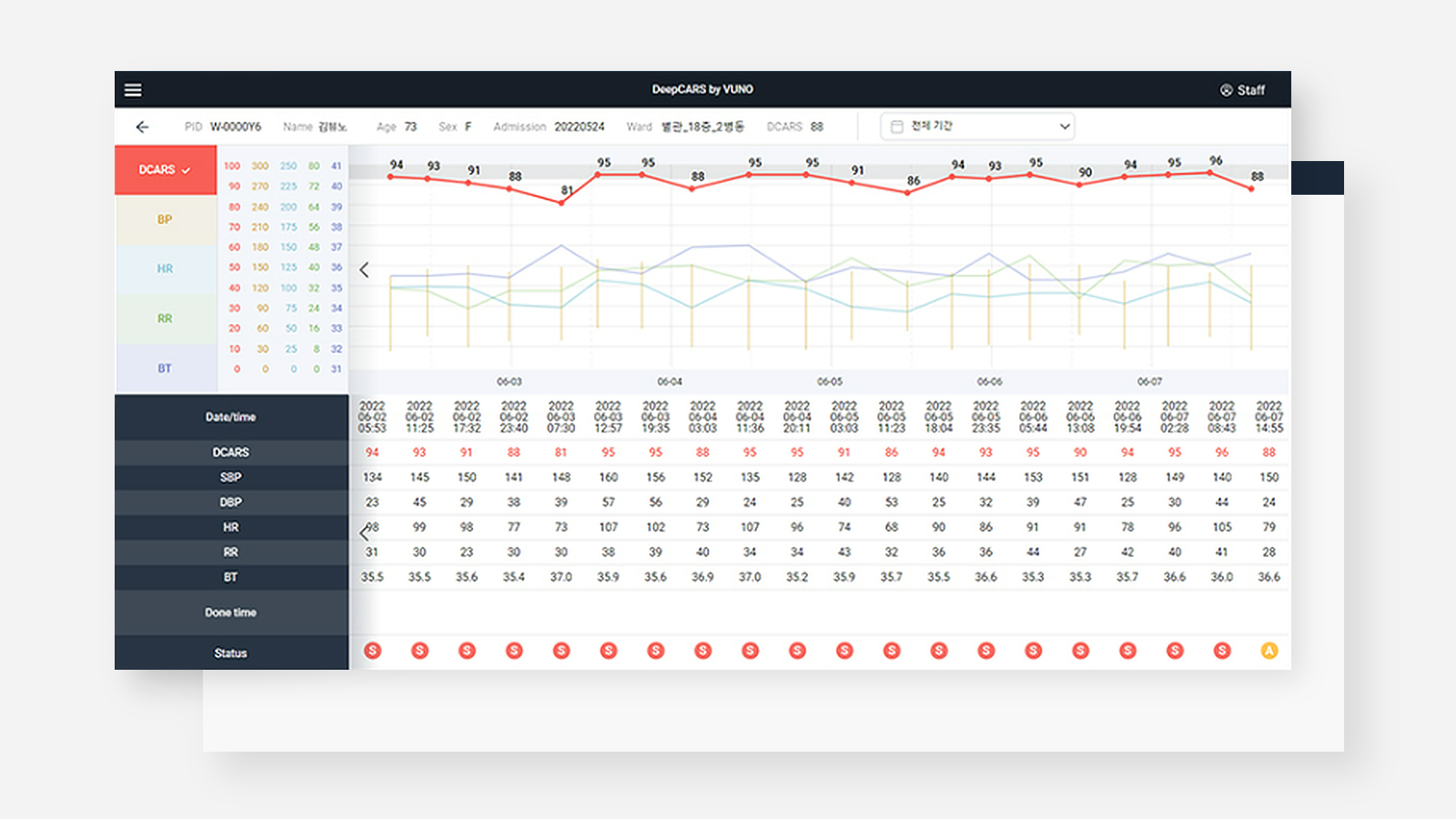
▲ 환자의 생체 신호를 바탕으로 심정비 발생 위험도를 예측하는 뷰노의 ‘딥카스(DeepCARS)’(출처: 뷰노(VUNO))
뷰노 딥카스는 흔히 ‘활력 4징후(혈압, 맥박, 호흡수, 체온)’로 불리는 생체 신호를 바탕으로, 입원 환자의 24시간 내 심정지 발생 위험도를 0~100점의 점수로 예측하는 설루션이다. 서울아산병원 등을 포함한 다기관 후향 임상시험*에서 내부 코호트* AUC 0.860, 외부 코호트 AUC 0.905의 높은 예측 정확도를 입증하였다. 2024년 1분기 기준, 국내 87개 병원에 도입되어 의료진의 추가 업무 부담 없이 환자 모니터링에 활용되고 있다.
* 다기관 후향 임상시험: 여러 병원의 과거 진료 데이터를 활용해, 특정 의료 기술이나 인공지능의 성능을 검증하는 임상 연구 방식
* 코호트(Cohort): 특정 기준에 따라 분류된 임상 연구 집단을 의미. 연구의 신뢰도를 높이기 위해 내부·외부 집단을 나눠 비교 분석한다.
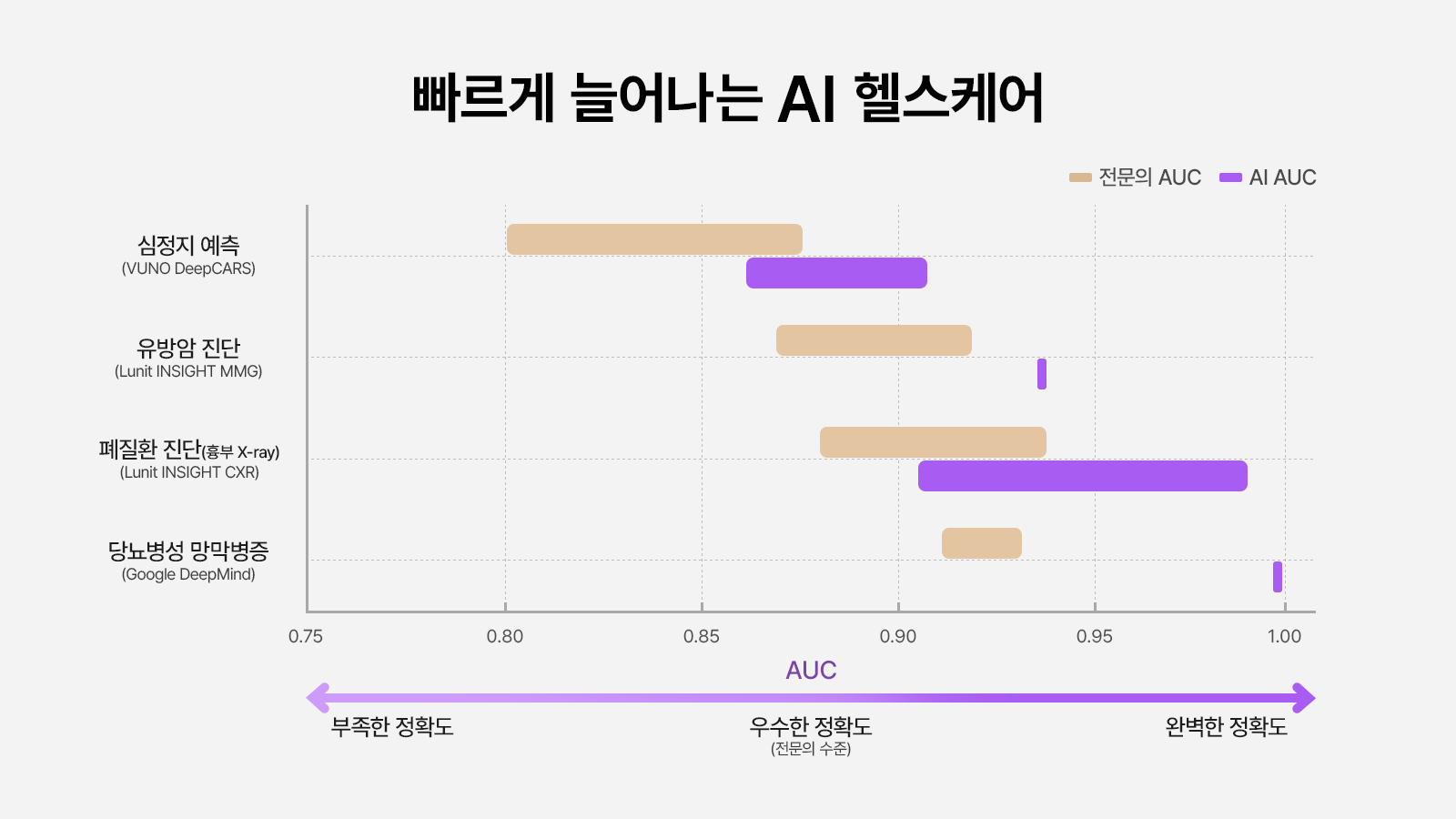
▲ 최근 개발되고 있는 헬스케어 AI의 정확도는 숙련된 전문의 수준을 상회한다.
이러한 인공지능 모델들은 대부분 특정 임상 업무에 특화되어 있으며, 임상의가 직접 라벨링 한 데이터 기반의 지도 학습 방식으로 개발됐다. 이러한 방식은 특정 작업에서는 임상의 수준의 성능을 보여주며, 의료 비용 절감과 환자 안전 향상에 기여하고 있다.
그러나 2021년경부터 주목받기 시작한 파운데이션 모델(Foundation Model) 기반 접근 방식은 다른 방향을 제시한다. 이 방식은 특정 작업에 특화된 모델을 개별적으로 개발하는 대신, 하나의 대규모 모델을 학습시켜 다양한 임상 업무에 폭넓게 적용할 수 있도록 설계된다.
특히 언어 기반 업무의 비중이 높은 의료 환경에서는, 자연어 처리에 특화된 LLM(거대언어모델)이 가장 대표적인 파운데이션 모델로 부상하고 있다.
LLM은 진료 기록 정리, 환자 문진 내용 요약, 의학 지식 기반 질의응답 등 다양한 언어 중심 업무에 적용 가능하며, 실제 의료 현장에서의 활용 가능성도 높아지고 있다. 예를 들어, 미국 의사국가시험(MedQA) 벤치마크에서 챗GPT-4o는 96점이라는 높은 성적을 기록했으며, 최근 공개된 Gemma 3, LLaMA 4 등의 모델은 우수한 한국어 이해 및 생성 능력까지 갖추고 있다. 이러한 기술적 진보는 파운데이션 모델이 단지 이론적 대안을 넘어, 임상 환경에서 활용 가능한 수준에 도달하고 있음을 시사한다.

▲ 더욱 발전된 헬스케어 AI가 상용화된 병원의 예상 모습(AI 활용해 제작)
실제 미국 등 선진국에서는 이미 AI를 임상 현장에 투입해 의무기록 받아쓰기 및 요약 기능을 제공함으로써 비용 절감 및 의료진 업무 부담 감소에 적극적으로 나서고 있다. 헬스케어 비용의 대부분은 인건비로 지출되기 때문에 이러한 AI 기술을 도입하는 것은 막대한 사회적 비용을 절감할 수 있는 효과적인 대안이 될 수 있다.
‘한국형’ 의료용 LLM의 필요성과 실험 및 과제
국내 헬스케어 분야에도 AI, 그중에서도 LLM이 빠르게 도입되고 있다. 하지만 LLM이라고 해서 아무것이나 활용할 수는 없다. 국내 상황에 맞는 한국형 LLM이 필요한 상황이다. 의료 분야에서 말하는 ‘한국형’ LLM은 단순히 ‘한국어’를 잘 구사하는 LLM과는 그 의미가 다르다. 최근 많은 LLM이 뛰어난 한국어 처리 능력을 보여주고 있지만, 그렇다고 해서 한국의 의료법, 가이드라인, 질환 분포, 진료 문화 등 의료 환경 전반을 이해하는 것은 아니다.
예를 들어, 챗GPT와 같은 모델은 한국 의사국가시험 총론 영역에서는 높은 점수를 기록하지만, 의료법 항목에서는 과락(40점 미만)을 받는 경우가 많다. 이는 현재 대부분의 LLM이 미국 기반 데이터로 학습되고 벤치마크 되어 있기 때문일 것이다. 결국, 국내의 의료 현실에 적합한 LLM을 개발하려면 단순한 언어 능력 이상의 현지화된 의료 지식이 필수다.

▲ 지난 1월, 서울대어린이병원 CJ 홀에서 열린 서울대학교병원 ‘헬스케어 AI 연구원’ 개원식(출처: 서울대학교병원)
2025년 1월, 문을 연 서울대학교병원 ‘헬스케어 AI 연구원’은 한국형 의료용 LLM 개발을 위해 오픈 소스 모델 기반의 실험을 진행 중이다. 챗GPT와 같은 상용 모델은 추가 학습이 제한적인 반면, Google의 Gemma 등의 오픈 소스 모델은 파라미터가 공개되어 있어 추가 학습이 용이하고, 병원 외부로 데이터를 반출하지 않아도 된다는 장점이 있다. 다만, 상용 모델에 비해 성능이 낮다는 단점이 있어, 성능 개선을 위한 정제된 학습 데이터가 필요하다.
이에 연구원은 2024년 한 해 동안 3,800만 건의 의무기록 데이터를 가명화하고, SOAP* 구조 기반의 임상 기록 데이터셋과 일반 의료 지식을 담은 ClinicalQA* 데이터셋을 구축했다. 반복성과 개인정보 이슈를 최소화하기 위해 정제(Distillation) 과정을 거쳐 학습 효율을 높였다**.
* SOAP(Subjective-Objective-Assessment-Plan): 의료진이 진료 시 사용하는 기본 문서화 구조로, 주관적 증상, 객관적 소견, 진단 평가, 치료 계획을 순서대로 기록한다.
* ClinicalQA: 임상 상황에서 자주 등장하는 질의응답 데이터를 기반으로 구성된 의료 지식 학습용 데이터셋
** 해당 데이터셋은 의료 특화 연구소 플랫폼(nstri.net)과 허깅페이스(Hugging Face)에서 확인할 수 있다.
향후에는 추론 과정을 단계적으로 수행하는 CoT* 방식의 추론형 LLM 개발이 필요하다[관련링크]. 또한 진료과 특화 모델들을 조합하는 MoE* 구조는 진단 정확도를 높이는 효과적인 방법으로, 연구원이 MIT, Google과 공동 연구한 결과, 정확도가 평균 12% 향상된 바 있다[관련링크].
* CoT(Chain of Thought): 모델이 문제 해결 과정을 단계적으로 서술하면서 답을 도출하는 방식으로, 복잡한 의사결정의 정확도를 높일 수 있다.
* MoE(Mixture of Experts): 여러 개의 특화된 모델(전문가)을 조합해 상황에 따라 선택적으로 활용하는 구조로, 복잡한 문제에 더 유연하고 정밀하게 대응할 수 있다.
더불어 의료 현장은 언어, 영상, 시계열, 수치 등 다양한 데이터를 통합적으로 다루는 분야인 만큼, 멀티모달 LLM* 개발 역시 중요한 과제로 떠오르고 있다.
* 멀티모달 LLM: 텍스트뿐 아니라 영상, 음성, 생체 신호 등 서로 다른 형태의 데이터를 동시에 처리할 수 있는 인공지능 언어 모델
더 넓은 영역으로 확대되는 헬스케어 AI

의료 현장에 특화된 LLM은 의무기록 자동 요약, 초안 작성, 환자 맞춤형 질의응답 등 다양한 임상 업무를 효과적으로 지원할 수 있다. 최근에는 음성 인식(Speech-to-Text) 기술과 결합한 Voice EMR(음성 기반 전자의무기록) 개발도 현실화되고 있다. ‘헬스케어 AI 연구원’에서도 이러한 LLM 기술을 활용해 HIS.AI(의무기록 작성 효율화), CLAIM.AI(원무 및 보험 청구 자동화), RESAERCH.AI(연구자 맞춤형 논문 큐레이션) 등의 프로젝트를 추진 중이다.
헬스케어 AI 연구는 단순히 기술 개발에 그치지 않고, 의료진과 개발자 간의 긴밀한 협력을 통해 실질적인 의료 문제 해결을 목표로 한다. 연구 초기 단계부터 임상 현장의 피드백을 빠르게 반영함으로써, 임상적 정확성과 안전성을 함께 갖춰가는 방향으로 발전하고 있다.
또한 필자가 속한 서울대병원은 공공기관으로서, AI 기술의 혜택이 보다 많은 이들에게 공평하게 돌아갈 수 있도록 오픈 데이터셋과 오픈 소스 모델 등을 지향한다. ‘헬스케어 AI 연구원’ 역시 “함께 만드는 지속 가능하고 건강한 미래”라는 슬로건 아래, 의료 AI의 공익적 가치를 실현하며 의료 서비스의 효율성과 안전성을 동시에 높여 나가고자 한다.
사람 중심의 의료와 기술의 공존, 그 교차점에서 헬스케어 AI가 수행할 역할은 이제 막 시작되고 있다.
※ 본 칼럼은 AI/반도체에 관한 인사이트를 제공하는 외부 전문가 칼럼으로, SK하이닉스의 공식 입장과는 다를 수 있습니다.